Fault Tolerant ML: Efficient Meta-Aggregation and Synchronous Training

0
🏋️
Sign in to get full access
Overview
- Investigates Byzantine-robust training in distributed machine learning systems
- Aims to enhance both efficiency and practicality of this challenging framework
- Introduces the Centered Trimmed Meta Aggregator (CTMA) - an efficient meta-aggregator that improves baseline aggregators
- Proposes using a double-momentum gradient estimation technique for Byzantine-robust training
Plain English Explanation
In distributed machine learning (ML) systems, where multiple devices or "workers" collaborate to train a shared model, there is a risk of "Byzantine failures." This means some workers may contribute incorrect updates, either due to malice or error. Ensuring resilience against these failures is crucial as distributed ML becomes more common for complex tasks.
The researchers introduce the Centered Trimmed Meta Aggregator (CTMA), an efficient tool that can upgrade baseline aggregators to perform optimally, while requiring low computational power. They also propose using a double-momentum gradient estimation technique within the Byzantine-robust training context. This technique has theoretical and practical advantages, like simplifying the tuning process and reducing reliance on many hyperparameters (settings that need to be manually configured). The researchers provide theoretical analysis supporting the effectiveness of this approach, especially in the stochastic convex optimization framework.
Technical Explanation
The paper focuses on enhancing both the efficiency and practicality of Byzantine-robust training in distributed ML systems. The researchers' first contribution is the Centered Trimmed Meta Aggregator (CTMA), a meta-aggregator that can upgrade baseline aggregators to achieve optimal performance levels, while having low computational demands.
Additionally, the researchers propose leveraging a recently developed gradient estimation technique based on a double-momentum strategy within the Byzantine-robust training context. This approach offers theoretical and practical advantages, such as simplifying the tuning process and reducing reliance on numerous hyperparameters. The researchers provide theoretical analysis of this technique's effectiveness, particularly within the stochastic convex optimization (SCO) framework.
Critical Analysis
The paper thoroughly addresses the challenge of ensuring Byzantine-resilience in distributed ML systems, proposing two novel techniques to enhance efficiency and practicality. The introduction of the CTMA meta-aggregator and the application of the double-momentum gradient estimation approach represent meaningful contributions to the field.
However, the paper does not extensively discuss potential limitations or caveats of the proposed methods. For example, it would be valuable to understand the specific scenarios or settings where these techniques may perform less optimally, or any implementation challenges that may arise. Additionally, the researchers could explore further research directions, such as evaluating the techniques in more diverse distributed learning environments or investigating their scalability to large-scale systems.
Conclusion
This paper tackles the crucial challenge of ensuring Byzantine-robustness in distributed machine learning systems, proposing two novel techniques to improve both the efficiency and practicality of this framework. The introduction of the CTMA meta-aggregator and the application of a double-momentum gradient estimation approach offer theoretical and practical advantages, with the potential to simplify the training process and reduce reliance on numerous hyperparameters. While the paper provides a strong technical foundation, further research is needed to thoroughly evaluate the limitations and scalability of these methods, as well as explore additional directions for enhancing Byzantine-robust distributed learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Fault Tolerant ML: Efficient Meta-Aggregation and Synchronous Training
Tehila Dahan, Kfir Y. Levy
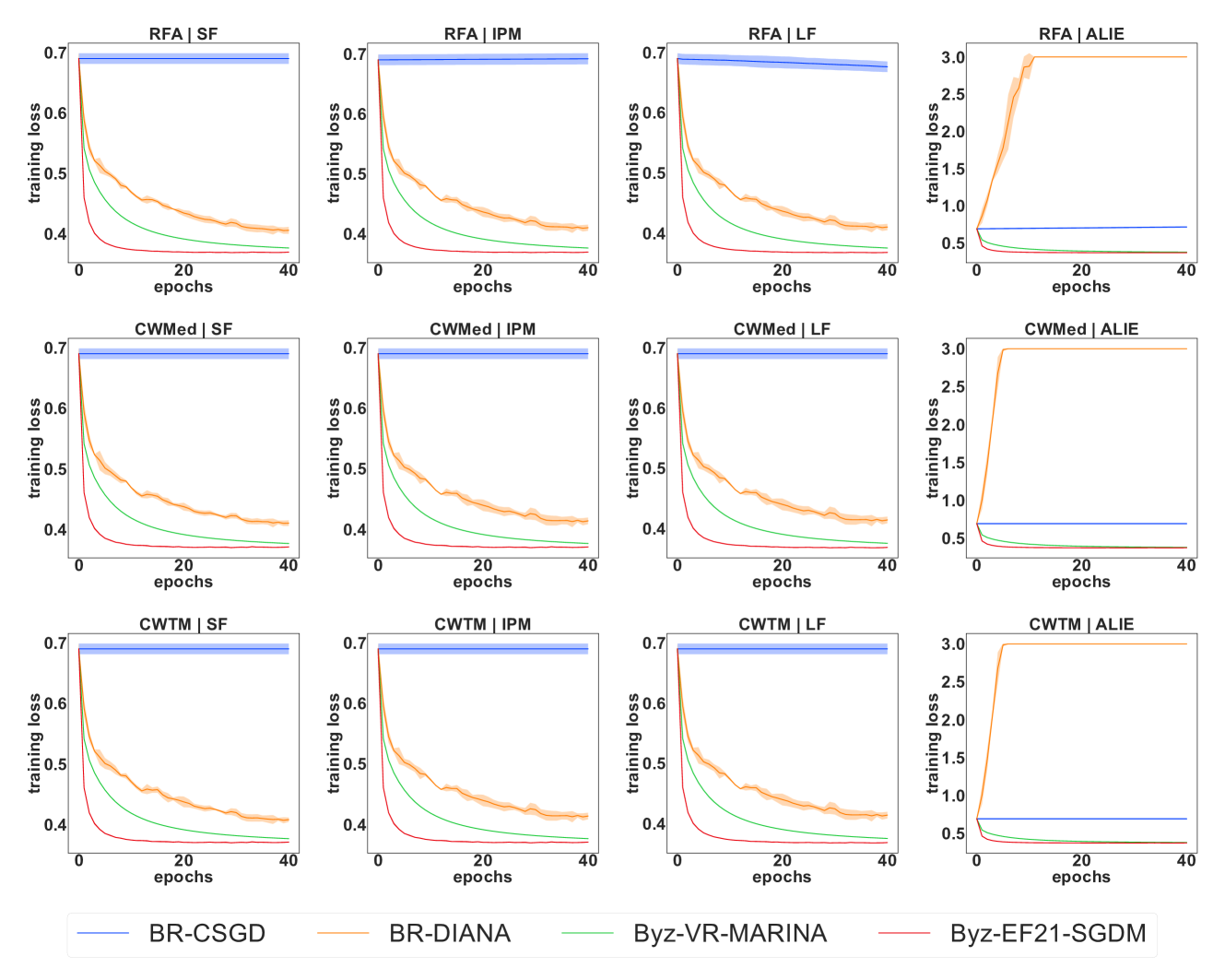
In this paper, we investigate the challenging framework of Byzantine-robust training in distributed machine learning (ML) systems, focusing on enhancing both efficiency and practicality. As distributed ML systems become integral for complex ML tasks, ensuring resilience against Byzantine failures-where workers may contribute incorrect updates due to malice or error-gains paramount importance. Our first contribution is the introduction of the Centered Trimmed Meta Aggregator (CTMA), an efficient meta-aggregator that upgrades baseline aggregators to optimal performance levels, while requiring low computational demands. Additionally, we propose harnessing a recently developed gradient estimation technique based on a double-momentum strategy within the Byzantine context. Our paper highlights its theoretical and practical advantages for Byzantine-robust training, especially in simplifying the tuning process and reducing the reliance on numerous hyperparameters. The effectiveness of this technique is supported by theoretical insights within the stochastic convex optimization (SCO) framework and corroborated by empirical evidence.
Read more9/4/2024
0
New!Byzantine-Robust and Communication-Efficient Distributed Learning via Compressed Momentum Filtering
Changxin Liu, Yanghao Li, Yuhao Yi, Karl H. Johansson
Distributed learning has become the standard approach for training large-scale machine learning models across private data silos. While distributed learning enhances privacy preservation and training efficiency, it faces critical challenges related to Byzantine robustness and communication reduction. Existing Byzantine-robust and communication-efficient methods rely on full gradient information either at every iteration or at certain iterations with a probability, and they only converge to an unnecessarily large neighborhood around the solution. Motivated by these issues, we propose a novel Byzantine-robust and communication-efficient stochastic distributed learning method that imposes no requirements on batch size and converges to a smaller neighborhood around the optimal solution than all existing methods, aligning with the theoretical lower bound. Our key innovation is leveraging Polyak Momentum to mitigate the noise caused by both biased compressors and stochastic gradients, thus defending against Byzantine workers under information compression. We provide proof of tight complexity bounds for our algorithm in the context of non-convex smooth loss functions, demonstrating that these bounds match the lower bounds in Byzantine-free scenarios. Finally, we validate the practical significance of our algorithm through an extensive series of experiments, benchmarking its performance on both binary classification and image classification tasks.
Read more9/16/2024

0
Byzantine-tolerant distributed learning of finite mixture models
Qiong Zhang, Jiahua Chen
This paper proposes two split-and-conquer (SC) learning estimators for finite mixture models that are tolerant to Byzantine failures. In SC learning, individual machines obtain local estimates, which are then transmitted to a central server for aggregation. During this communication, the server may receive malicious or incorrect information from some local machines, a scenario known as Byzantine failures. While SC learning approaches have been devised to mitigate Byzantine failures in statistical models with Euclidean parameters, developing Byzantine-tolerant methods for finite mixture models with non-Euclidean parameters requires a distinct strategy. Our proposed distance-based methods are hyperparameter tuning free, unlike existing methods, and are resilient to Byzantine failures while achieving high statistical efficiency. We validate the effectiveness of our methods both theoretically and empirically via experiments on simulated and real data from machine learning applications for digit recognition. The code for the experiment can be found at https://github.com/SarahQiong/RobustSCGMM.
Read more7/22/2024
🎯
0
Byzantine Robustness and Partial Participation Can Be Achieved at Once: Just Clip Gradient Differences
Grigory Malinovsky, Peter Richt'arik, Samuel Horv'ath, Eduard Gorbunov
Distributed learning has emerged as a leading paradigm for training large machine learning models. However, in real-world scenarios, participants may be unreliable or malicious, posing a significant challenge to the integrity and accuracy of the trained models. Byzantine fault tolerance mechanisms have been proposed to address these issues, but they often assume full participation from all clients, which is not always practical due to the unavailability of some clients or communication constraints. In our work, we propose the first distributed method with client sampling and provable tolerance to Byzantine workers. The key idea behind the developed method is the use of gradient clipping to control stochastic gradient differences in recursive variance reduction. This allows us to bound the potential harm caused by Byzantine workers, even during iterations when all sampled clients are Byzantine. Furthermore, we incorporate communication compression into the method to enhance communication efficiency. Under general assumptions, we prove convergence rates for the proposed method that match the existing state-of-the-art (SOTA) theoretical results. We also propose a heuristic on adjusting any Byzantine-robust method to a partial participation scenario via clipping.
Read more6/10/2024