Feature Importance Disparities for Data Bias Investigations
2303.01704
0
0
✨
Abstract
It is widely held that one cause of downstream bias in classifiers is bias present in the training data. Rectifying such biases may involve context-dependent interventions such as training separate models on subgroups, removing features with bias in the collection process, or even conducting real-world experiments to ascertain sources of bias. Despite the need for such data bias investigations, few automated methods exist to assist practitioners in these efforts. In this paper, we present one such method that given a dataset $X$ consisting of protected and unprotected features, outcomes $y$, and a regressor $h$ that predicts $y$ given $X$, outputs a tuple $(f_j, g)$, with the following property: $g$ corresponds to a subset of the training dataset $(X, y)$, such that the $j^{th}$ feature $f_j$ has much larger (or smaller) influence in the subgroup $g$, than on the dataset overall, which we call feature importance disparity (FID). We show across $4$ datasets and $4$ common feature importance methods of broad interest to the machine learning community that we can efficiently find subgroups with large FID values even over exponentially large subgroup classes and in practice these groups correspond to subgroups with potentially serious bias issues as measured by standard fairness metrics.
Create account to get full access
Overview
- This paper presents a method to identify subgroups in a dataset where a particular feature has a much larger or smaller influence on the model's predictions compared to the overall dataset.
- The authors call this phenomenon "feature importance disparity" (FID) and show that it can be used to detect potential bias issues in machine learning models.
- The method is evaluated on 4 datasets and 4 common feature importance methods, demonstrating its ability to efficiently find subgroups with large FID values.
Plain English Explanation
When training machine learning models, the data used for training can sometimes contain biases. These biases can then be reflected in the model's outputs, leading to unfair or undesirable results. To address this issue, researchers may need to investigate the sources of bias in the training data, such as by removing problematic features or conducting real-world experiments.
This paper introduces a method that can help practitioners identify subgroups within a dataset where a particular feature has a much stronger or weaker influence on the model's predictions compared to the overall dataset. The authors call this "feature importance disparity" (FID). By finding these subgroups, researchers can better understand the sources of bias in their data and take steps to mitigate them.
The method is evaluated on several datasets and feature importance techniques, demonstrating its ability to efficiently identify subgroups with large FID values. These subgroups often correspond to areas where the model may be exhibiting serious bias issues, as measured by standard fairness metrics.
Technical Explanation
The paper presents a method that, given a dataset X consisting of protected and unprotected features, outcomes y, and a regressor h that predicts y from X, outputs a tuple (f_j, g). The f_j component corresponds to the jth feature, and g corresponds to a subset of the training dataset (X, y) where the jth feature f_j has much larger (or smaller) influence on the model's predictions compared to the overall dataset.
The authors call this phenomenon "feature importance disparity" (FID) and show that it can be used to detect potential bias issues in machine learning models. They evaluate their method across 4 datasets and 4 common feature importance methods, demonstrating its ability to efficiently find subgroups with large FID values, even over exponentially large subgroup classes.
The key insight is that by identifying these subgroups with large FID, researchers can better understand the sources of bias in their data and take steps to mitigate them, such as by removing problematic features, training separate models on subgroups, or conducting real-world experiments to ascertain the causes of bias.
Critical Analysis
The paper presents a novel and promising approach for identifying potential sources of bias in machine learning models. By focusing on feature importance disparity, the method provides a targeted way to uncover subgroups where the model may be exhibiting unfair or undesirable behavior.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that their method may not be able to identify all sources of bias, as there may be complex interactions between features that are not captured by the FID metric. Additionally, the method relies on the accuracy of the feature importance techniques used, which can themselves be subject to biases or limitations.
Further research could explore ways to combine the FID approach with other bias detection and mitigation strategies, such as investigating the quality and fairness of the underlying data or developing more robust feature importance methods. Practitioners should also be cautious about over-relying on any single bias detection technique and instead adopt a more comprehensive, multifaceted approach to addressing algorithmic bias.
Conclusion
This paper presents a novel method for identifying subgroups within a dataset where a particular feature has a much stronger or weaker influence on a model's predictions compared to the overall dataset. By detecting these "feature importance disparities," researchers can better understand the sources of bias in their training data and take steps to mitigate them, such as by removing problematic features, training separate models on subgroups, or conducting real-world experiments to ascertain the causes of bias.
The authors demonstrate the effectiveness of their approach across several datasets and feature importance methods, showing that it can efficiently identify subgroups with large FID values that often correspond to areas of serious bias. This work represents an important step towards more systematic and automated methods for detecting and addressing bias in machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

The Impact of Differential Feature Under-reporting on Algorithmic Fairness
Nil-Jana Akpinar, Zachary C. Lipton, Alexandra Chouldechova
0
0
Predictive risk models in the public sector are commonly developed using administrative data that is more complete for subpopulations that more greatly rely on public services. In the United States, for instance, information on health care utilization is routinely available to government agencies for individuals supported by Medicaid and Medicare, but not for the privately insured. Critiques of public sector algorithms have identified such differential feature under-reporting as a driver of disparities in algorithmic decision-making. Yet this form of data bias remains understudied from a technical viewpoint. While prior work has examined the fairness impacts of additive feature noise and features that are clearly marked as missing, the setting of data missingness absent indicators (i.e. differential feature under-reporting) has been lacking in research attention. In this work, we present an analytically tractable model of differential feature under-reporting which we then use to characterize the impact of this kind of data bias on algorithmic fairness. We demonstrate how standard missing data methods typically fail to mitigate bias in this setting, and propose a new set of methods specifically tailored to differential feature under-reporting. Our results show that, in real world data settings, under-reporting typically leads to increasing disparities. The proposed solution methods show success in mitigating increases in unfairness.
5/6/2024
👁️
Enhancing Intrinsic Features for Debiasing via Investigating Class-Discerning Common Attributes in Bias-Contrastive Pair
Jeonghoon Park, Chaeyeon Chung, Juyoung Lee, Jaegul Choo
0
0
In the image classification task, deep neural networks frequently rely on bias attributes that are spuriously correlated with a target class in the presence of dataset bias, resulting in degraded performance when applied to data without bias attributes. The task of debiasing aims to compel classifiers to learn intrinsic attributes that inherently define a target class rather than focusing on bias attributes. While recent approaches mainly focus on emphasizing the learning of data samples without bias attributes (i.e., bias-conflicting samples) compared to samples with bias attributes (i.e., bias-aligned samples), they fall short of directly guiding models where to focus for learning intrinsic features. To address this limitation, this paper proposes a method that provides the model with explicit spatial guidance that indicates the region of intrinsic features. We first identify the intrinsic features by investigating the class-discerning common features between a bias-aligned (BA) sample and a bias-conflicting (BC) sample (i.e., bias-contrastive pair). Next, we enhance the intrinsic features in the BA sample that are relatively under-exploited for prediction compared to the BC sample. To construct the bias-contrastive pair without using bias information, we introduce a bias-negative score that distinguishes BC samples from BA samples employing a biased model. The experiments demonstrate that our method achieves state-of-the-art performance on synthetic and real-world datasets with various levels of bias severity.
6/18/2024
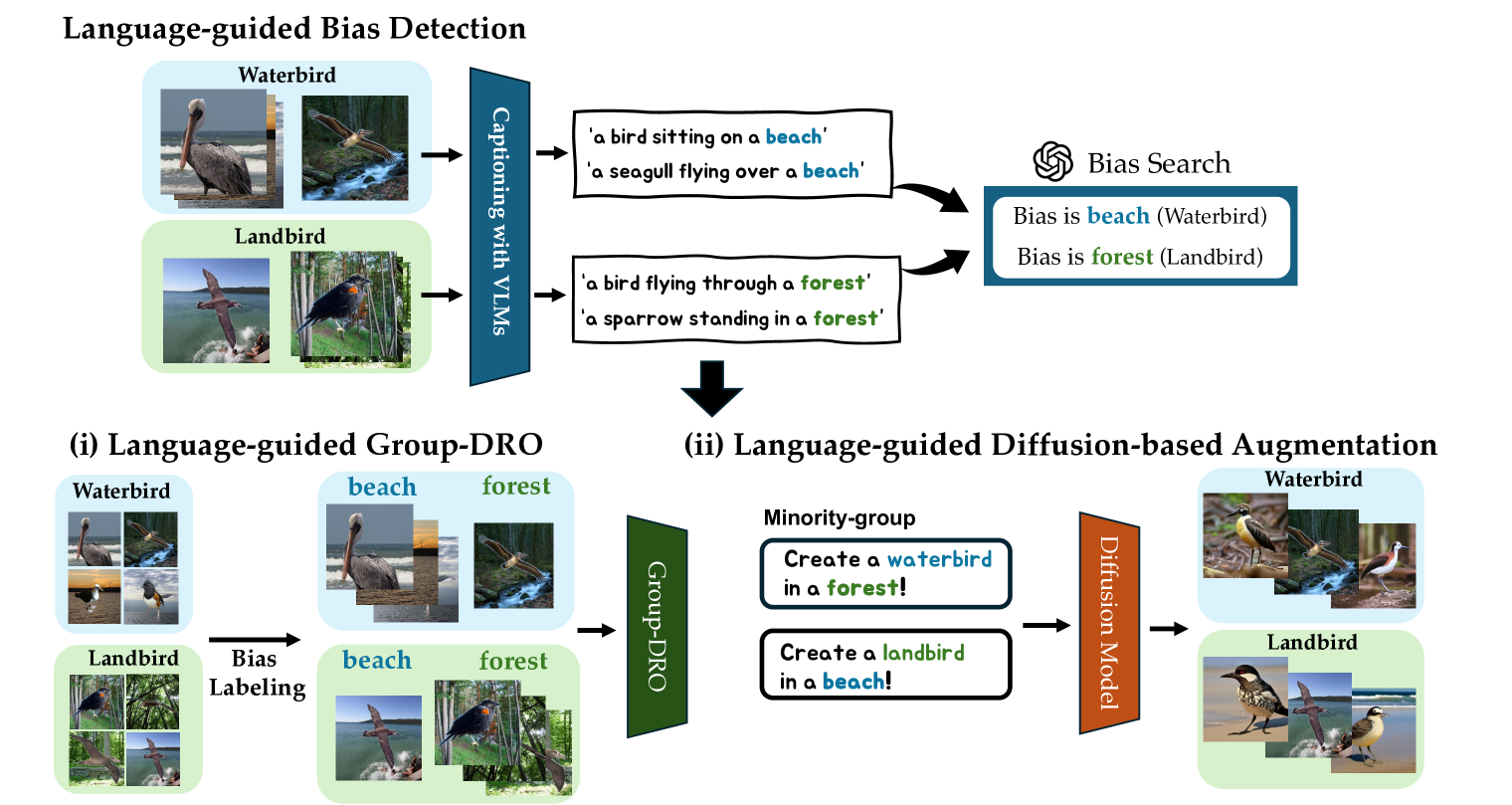
Language-guided Detection and Mitigation of Unknown Dataset Bias
Zaiying Zhao, Soichiro Kumano, Toshihiko Yamasaki
0
0
Dataset bias is a significant problem in training fair classifiers. When attributes unrelated to classification exhibit strong biases towards certain classes, classifiers trained on such dataset may overfit to these bias attributes, substantially reducing the accuracy for minority groups. Mitigation techniques can be categorized according to the availability of bias information (ie, prior knowledge). Although scenarios with unknown biases are better suited for real-world settings, previous work in this field often suffers from a lack of interpretability regarding biases and lower performance. In this study, we propose a framework to identify potential biases as keywords without prior knowledge based on the partial occurrence in the captions. We further propose two debiasing methods: (a) handing over to an existing debiasing approach which requires prior knowledge by assigning pseudo-labels, and (b) employing data augmentation via text-to-image generative models, using acquired bias keywords as prompts. Despite its simplicity, experimental results show that our framework not only outperforms existing methods without prior knowledge, but also is even comparable with a method that assumes prior knowledge.
6/6/2024
📊
Trusting Fair Data: Leveraging Quality in Fairness-Driven Data Removal Techniques
Manh Khoi Duong, Stefan Conrad
0
0
In this paper, we deal with bias mitigation techniques that remove specific data points from the training set to aim for a fair representation of the population in that set. Machine learning models are trained on these pre-processed datasets, and their predictions are expected to be fair. However, such approaches may exclude relevant data, making the attained subsets less trustworthy for further usage. To enhance the trustworthiness of prior methods, we propose additional requirements and objectives that the subsets must fulfill in addition to fairness: (1) group coverage, and (2) minimal data loss. While removing entire groups may improve the measured fairness, this practice is very problematic as failing to represent every group cannot be considered fair. In our second concern, we advocate for the retention of data while minimizing discrimination. By introducing a multi-objective optimization problem that considers fairness and data loss, we propose a methodology to find Pareto-optimal solutions that balance these objectives. By identifying such solutions, users can make informed decisions about the trade-off between fairness and data quality and select the most suitable subset for their application.
6/12/2024