Enhancing Intrinsic Features for Debiasing via Investigating Class-Discerning Common Attributes in Bias-Contrastive Pair
2404.19250
0
0
👁️
Abstract
In the image classification task, deep neural networks frequently rely on bias attributes that are spuriously correlated with a target class in the presence of dataset bias, resulting in degraded performance when applied to data without bias attributes. The task of debiasing aims to compel classifiers to learn intrinsic attributes that inherently define a target class rather than focusing on bias attributes. While recent approaches mainly focus on emphasizing the learning of data samples without bias attributes (i.e., bias-conflicting samples) compared to samples with bias attributes (i.e., bias-aligned samples), they fall short of directly guiding models where to focus for learning intrinsic features. To address this limitation, this paper proposes a method that provides the model with explicit spatial guidance that indicates the region of intrinsic features. We first identify the intrinsic features by investigating the class-discerning common features between a bias-aligned (BA) sample and a bias-conflicting (BC) sample (i.e., bias-contrastive pair). Next, we enhance the intrinsic features in the BA sample that are relatively under-exploited for prediction compared to the BC sample. To construct the bias-contrastive pair without using bias information, we introduce a bias-negative score that distinguishes BC samples from BA samples employing a biased model. The experiments demonstrate that our method achieves state-of-the-art performance on synthetic and real-world datasets with various levels of bias severity.
Create account to get full access
Overview
- Deep neural networks in image classification tasks often rely on bias attributes that are correlated with the target class, leading to degraded performance when applied to unbiased data.
- The task of debiasing aims to compel classifiers to learn intrinsic attributes that define the target class rather than focus on bias attributes.
- Recent approaches focus on emphasizing the learning of bias-conflicting samples compared to bias-aligned samples, but they don't directly guide the model to focus on learning intrinsic features.
- This paper proposes a method that provides the model with explicit spatial guidance to indicate the regions of intrinsic features.
Plain English Explanation
Deep learning models used for image classification tasks can sometimes learn to rely on "shortcut" features that are correlated with the target class, but don't actually define it. For example, a model trained to classify images of dogs might learn to focus on the background of the image (like grass or trees) rather than the actual dog, because those background features happen to co-occur with dogs in the training data.
This can lead to the model performing poorly when applied to new images that don't have those same background features, even though they contain a dog. The goal of debiasing is to get the model to focus on the intrinsic features of the target class (like the shape, texture, and features of the dog itself) rather than relying on these spurious correlations.
Recent approaches have tried to do this by emphasizing the learning of samples that don't have the bias features (bias-conflicting samples), compared to samples that do have the bias features (bias-aligned samples). However, this doesn't directly guide the model to focus on the regions of the image that contain the intrinsic features.
This paper proposes a new method that provides the model with explicit spatial guidance, indicating the specific regions of the image that contain the intrinsic features of the target class. By focusing the model's attention on these key regions, it can learn to base its predictions on the true defining features of the class, rather than relying on biased correlations.
Technical Explanation
The key steps of the proposed method are:
- Identify the intrinsic features of the target class by finding the class-discerning common features between a bias-aligned (BA) sample and a bias-conflicting (BC) sample (i.e., a "bias-contrastive pair").
- Enhance the intrinsic features in the BA sample that are relatively under-exploited for prediction compared to the BC sample.
- Construct the bias-contrastive pair without using any bias information, by introducing a "bias-negative score" that can distinguish BC samples from BA samples using a biased model.
The experiments show that this method achieves state-of-the-art performance on both synthetic and real-world datasets with varying levels of bias severity. By providing the model with explicit guidance on where to focus, it is able to learn the intrinsic features that define the target class, rather than relying on spurious correlations with biased attributes.
Critical Analysis
The paper provides a novel and promising approach to the challenge of debiasing deep learning models in image classification tasks. By explicitly guiding the model to focus on the intrinsic features of the target class, it addresses a key limitation of prior methods that only emphasized the learning of bias-conflicting samples.
However, the paper does not address some potential limitations or areas for further research:
- The method relies on being able to identify the intrinsic features of the target class, which may not always be straightforward, especially for more complex classes.
- The proposed "bias-negative score" for constructing the bias-contrastive pair could be sensitive to the choice of biased model used, and may not generalize well to different types of bias.
- The experiments were limited to image classification tasks, and it's unclear how well the method would transfer to other domains or tasks where dataset bias may manifest differently.
Overall, this paper presents a valuable contribution to the field of debiasing deep learning models, but further research is needed to address these potential limitations and explore the broader applicability of the approach.
Conclusion
This paper proposes a novel method for debiasing deep neural networks in image classification tasks by providing the model with explicit spatial guidance to focus on the intrinsic features of the target class, rather than relying on spurious correlations with bias attributes.
The key innovation is the use of a "bias-contrastive pair" to identify the intrinsic features and then enhance their learning in the bias-aligned samples. This approach outperforms previous state-of-the-art methods on both synthetic and real-world datasets, demonstrating the potential of this technique to improve the robustness and fairness of deep learning models in the presence of dataset bias.
While there are some limitations that warrant further research, this paper represents an important step forward in the ongoing effort to debias deep neural networks and ensure they are learning truly meaningful representations, rather than relying on superficial correlations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
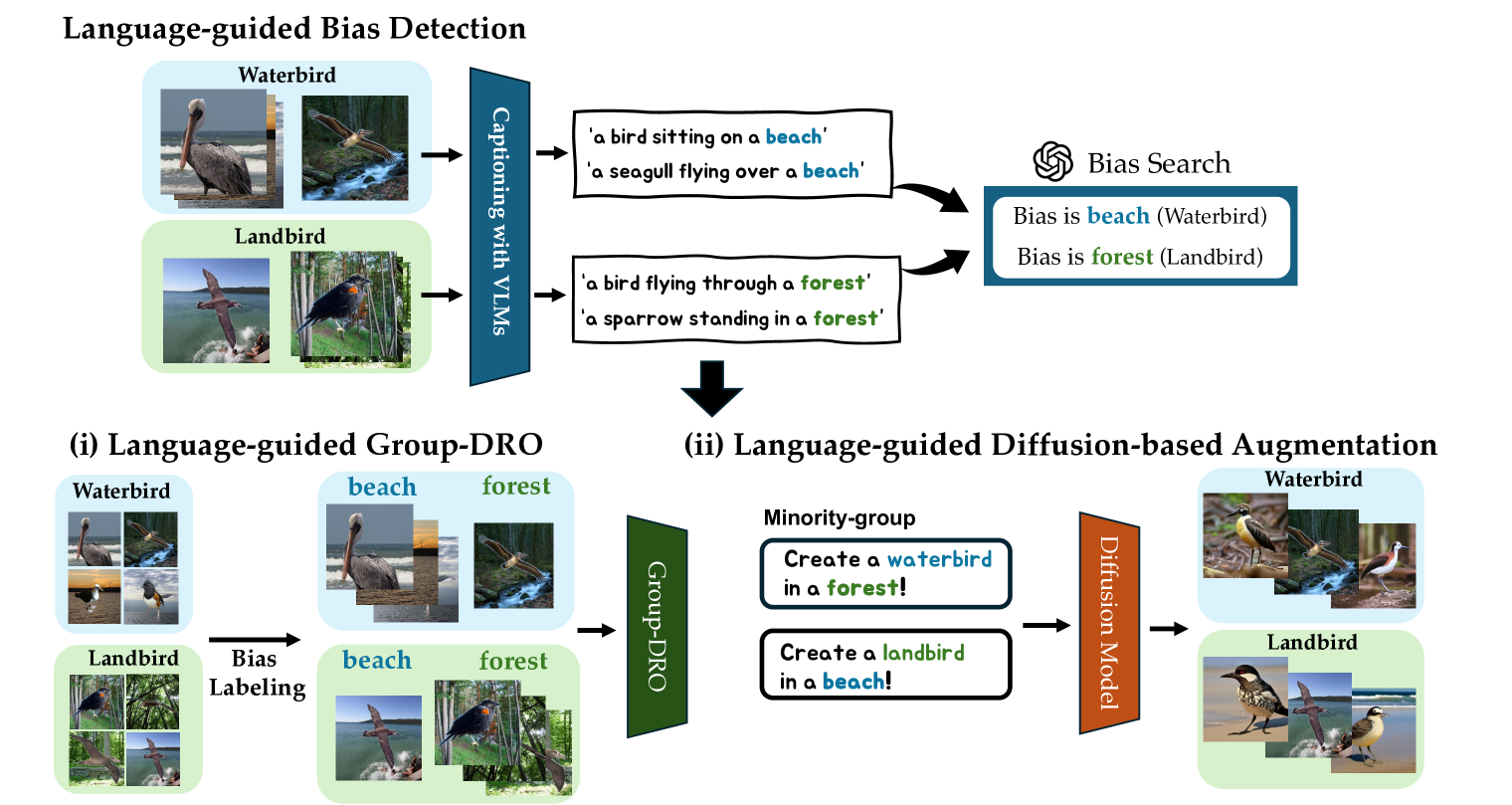
Language-guided Detection and Mitigation of Unknown Dataset Bias
Zaiying Zhao, Soichiro Kumano, Toshihiko Yamasaki
0
0
Dataset bias is a significant problem in training fair classifiers. When attributes unrelated to classification exhibit strong biases towards certain classes, classifiers trained on such dataset may overfit to these bias attributes, substantially reducing the accuracy for minority groups. Mitigation techniques can be categorized according to the availability of bias information (ie, prior knowledge). Although scenarios with unknown biases are better suited for real-world settings, previous work in this field often suffers from a lack of interpretability regarding biases and lower performance. In this study, we propose a framework to identify potential biases as keywords without prior knowledge based on the partial occurrence in the captions. We further propose two debiasing methods: (a) handing over to an existing debiasing approach which requires prior knowledge by assigning pseudo-labels, and (b) employing data augmentation via text-to-image generative models, using acquired bias keywords as prompts. Despite its simplicity, experimental results show that our framework not only outperforms existing methods without prior knowledge, but also is even comparable with a method that assumes prior knowledge.
6/6/2024
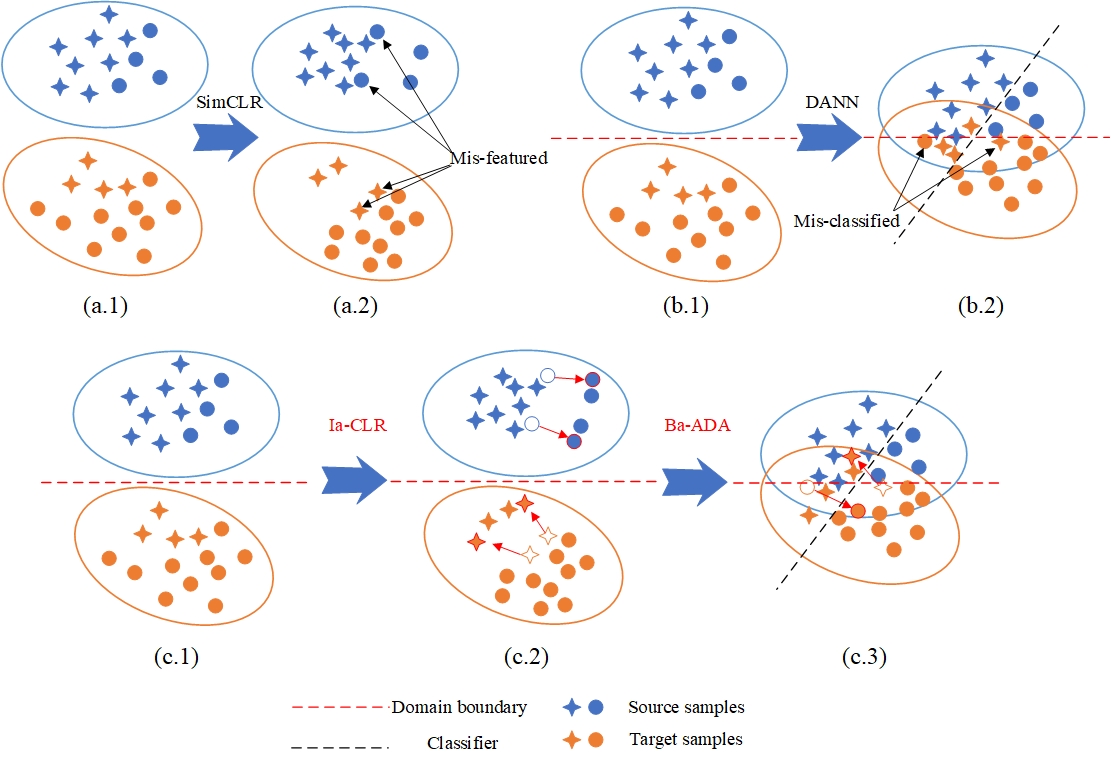
Self-degraded contrastive domain adaptation for industrial fault diagnosis with bi-imbalanced data
Gecheng Chen, Zeyu Yang, Chengwen Luo, Jianqiang Li
0
0
Modern industrial fault diagnosis tasks often face the combined challenge of distribution discrepancy and bi-imbalance. Existing domain adaptation approaches pay little attention to the prevailing bi-imbalance, leading to poor domain adaptation performance or even negative transfer. In this work, we propose a self-degraded contrastive domain adaptation (Sd-CDA) diagnosis framework to handle the domain discrepancy under the bi-imbalanced data. It first pre-trains the feature extractor via imbalance-aware contrastive learning based on model pruning to learn the feature representation efficiently in a self-supervised manner. Then it forces the samples away from the domain boundary based on supervised contrastive domain adversarial learning (SupCon-DA) and ensures the features generated by the feature extractor are discriminative enough. Furthermore, we propose the pruned contrastive domain adversarial learning (PSupCon-DA) to pay automatically re-weighted attention to the minorities to enhance the performance towards bi-imbalanced data. We show the superiority of the proposed method via two experiments.
6/3/2024
✨
Feature Importance Disparities for Data Bias Investigations
Peter W. Chang, Leor Fishman, Seth Neel
0
0
It is widely held that one cause of downstream bias in classifiers is bias present in the training data. Rectifying such biases may involve context-dependent interventions such as training separate models on subgroups, removing features with bias in the collection process, or even conducting real-world experiments to ascertain sources of bias. Despite the need for such data bias investigations, few automated methods exist to assist practitioners in these efforts. In this paper, we present one such method that given a dataset $X$ consisting of protected and unprotected features, outcomes $y$, and a regressor $h$ that predicts $y$ given $X$, outputs a tuple $(f_j, g)$, with the following property: $g$ corresponds to a subset of the training dataset $(X, y)$, such that the $j^{th}$ feature $f_j$ has much larger (or smaller) influence in the subgroup $g$, than on the dataset overall, which we call feature importance disparity (FID). We show across $4$ datasets and $4$ common feature importance methods of broad interest to the machine learning community that we can efficiently find subgroups with large FID values even over exponentially large subgroup classes and in practice these groups correspond to subgroups with potentially serious bias issues as measured by standard fairness metrics.
6/4/2024
📊
Mitigating Bias Using Model-Agnostic Data Attribution
Sander De Coninck, Wei-Cheng Wang, Sam Leroux, Pieter Simoens
0
0
Mitigating bias in machine learning models is a critical endeavor for ensuring fairness and equity. In this paper, we propose a novel approach to address bias by leveraging pixel image attributions to identify and regularize regions of images containing significant information about bias attributes. Our method utilizes a model-agnostic approach to extract pixel attributions by employing a convolutional neural network (CNN) classifier trained on small image patches. By training the classifier to predict a property of the entire image using only a single patch, we achieve region-based attributions that provide insights into the distribution of important information across the image. We propose utilizing these attributions to introduce targeted noise into datasets with confounding attributes that bias the data, thereby constraining neural networks from learning these biases and emphasizing the primary attributes. Our approach demonstrates its efficacy in enabling the training of unbiased classifiers on heavily biased datasets.
5/9/2024