Agglomerative Federated Learning: Empowering Larger Model Training via End-Edge-Cloud Collaboration
2312.11489
0
0

Abstract
Federated Learning (FL) enables training Artificial Intelligence (AI) models over end devices without compromising their privacy. As computing tasks are increasingly performed by a combination of cloud, edge, and end devices, FL can benefit from this End-Edge-Cloud Collaboration (EECC) paradigm to achieve collaborative device-scale expansion with real-time access. Although Hierarchical Federated Learning (HFL) supports multi-tier model aggregation suitable for EECC, prior works assume the same model structure on all computing nodes, constraining the model scale by the weakest end devices. To address this issue, we propose Agglomerative Federated Learning (FedAgg), which is a novel EECC-empowered FL framework that allows the trained models from end, edge, to cloud to grow larger in size and stronger in generalization ability. FedAgg recursively organizes computing nodes among all tiers based on Bridge Sample Based Online Distillation Protocol (BSBODP), which enables every pair of parent-child computing nodes to mutually transfer and distill knowledge extracted from generated bridge samples. This design enhances the performance by exploiting the potential of larger models, with privacy constraints of FL and flexibility requirements of EECC both satisfied. Experiments under various settings demonstrate that FedAgg outperforms state-of-the-art methods by an average of 4.53% accuracy gains and remarkable improvements in convergence rate.
Create account to get full access
Overview
- This paper proposes a new approach called Agglomerative Federated Learning (AFL) that enables the training of larger machine learning models by combining resources from the end, edge, and cloud computing devices.
- AFL addresses the challenge of model heterogeneity in federated learning, where devices have varying capabilities, by dynamically grouping devices into clusters based on their model parameters.
- The paper introduces a novel interaction protocol that coordinates the collaboration between the end, edge, and cloud components to efficiently aggregate model updates and enable the training of large-scale models.
Plain English Explanation
The paper introduces a new way of training large machine learning models called Agglomerative Federated Learning (AFL). In traditional federated learning, devices like smartphones or tablets work together to train a shared model without sharing their raw data. However, these devices can have very different capabilities, which makes it challenging to train a single large model.
AFL solves this problem by dynamically grouping devices into clusters based on the similarity of their model parameters. Devices in the same cluster can then collaborate more effectively to train a model that is tailored to their specific capabilities. The paper also describes a new way for the devices, edge servers (like local Wi-Fi access points), and cloud servers to coordinate and efficiently combine the model updates from the different clusters.
This allows AFL to leverage the combined computing power of many devices, even if they have very different hardware and capabilities. By doing this, AFL can train much larger and more sophisticated machine learning models than would be possible using traditional federated learning approaches.
Technical Explanation
The paper proposes a novel federated learning framework called Agglomerative Federated Learning (AFL) that enables the training of larger machine learning models by leveraging the combined resources of end devices, edge servers, and cloud servers.
AFL addresses the challenge of model heterogeneity in federated learning, where participating devices have varying computational capabilities and model architectures. AFL dynamically clusters devices based on the similarity of their model parameters, allowing devices within the same cluster to collaborate more effectively on training a shared model tailored to their specific capabilities.
The paper introduces a new interaction protocol that coordinates the collaboration between the end devices, edge servers, and cloud servers. This protocol efficiently aggregates model updates from the different device clusters and enables the training of large-scale models that would not be possible with traditional federated learning approaches.
The authors evaluate AFL on several benchmark datasets and show that it can achieve higher model accuracy compared to standard federated learning, particularly for large model architectures. They also demonstrate AFL's ability to handle non-IID data distributions across devices and improve data efficiency by leveraging the edge and cloud resources.
Critical Analysis
The paper provides a promising approach to address the model heterogeneity challenge in federated learning, which is a key barrier to deploying large-scale machine learning models in distributed environments. The dynamic clustering and interaction protocol introduced in AFL enable more effective collaboration between devices with varying capabilities.
However, the paper does not fully address the data barrier challenges that can arise in federated learning scenarios, where devices may have limited or non-representative data. Additionally, the evaluation is primarily focused on synthetic and relatively simple benchmark tasks, and further research is needed to understand the real-world applicability and scalability of AFL, particularly for more complex machine learning problems.
Another potential limitation is the reliance on edge servers, which may not be available or feasible in all deployment scenarios. The paper could be strengthened by exploring alternative architectures that minimize the dependency on edge infrastructure or provide strategies to handle its absence.
Despite these caveats, the core ideas in AFL represent an important step towards enabling the training of larger and more sophisticated machine learning models in federated learning settings, which has significant implications for privacy-preserving AI applications.
Conclusion
The Agglomerative Federated Learning (AFL) approach proposed in this paper offers a promising solution to the model heterogeneity challenge in federated learning. By dynamically clustering devices based on their model parameters and introducing a novel interaction protocol, AFL enables the training of larger and more complex machine learning models by leveraging the combined resources of end devices, edge servers, and cloud servers.
While the paper identifies some important limitations and areas for further research, the core ideas in AFL have the potential to significantly advance the field of federated learning and unlock new opportunities for privacy-preserving AI applications at scale. As the demand for large, high-performance models continues to grow, approaches like AFL that can effectively harness distributed computing resources will become increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
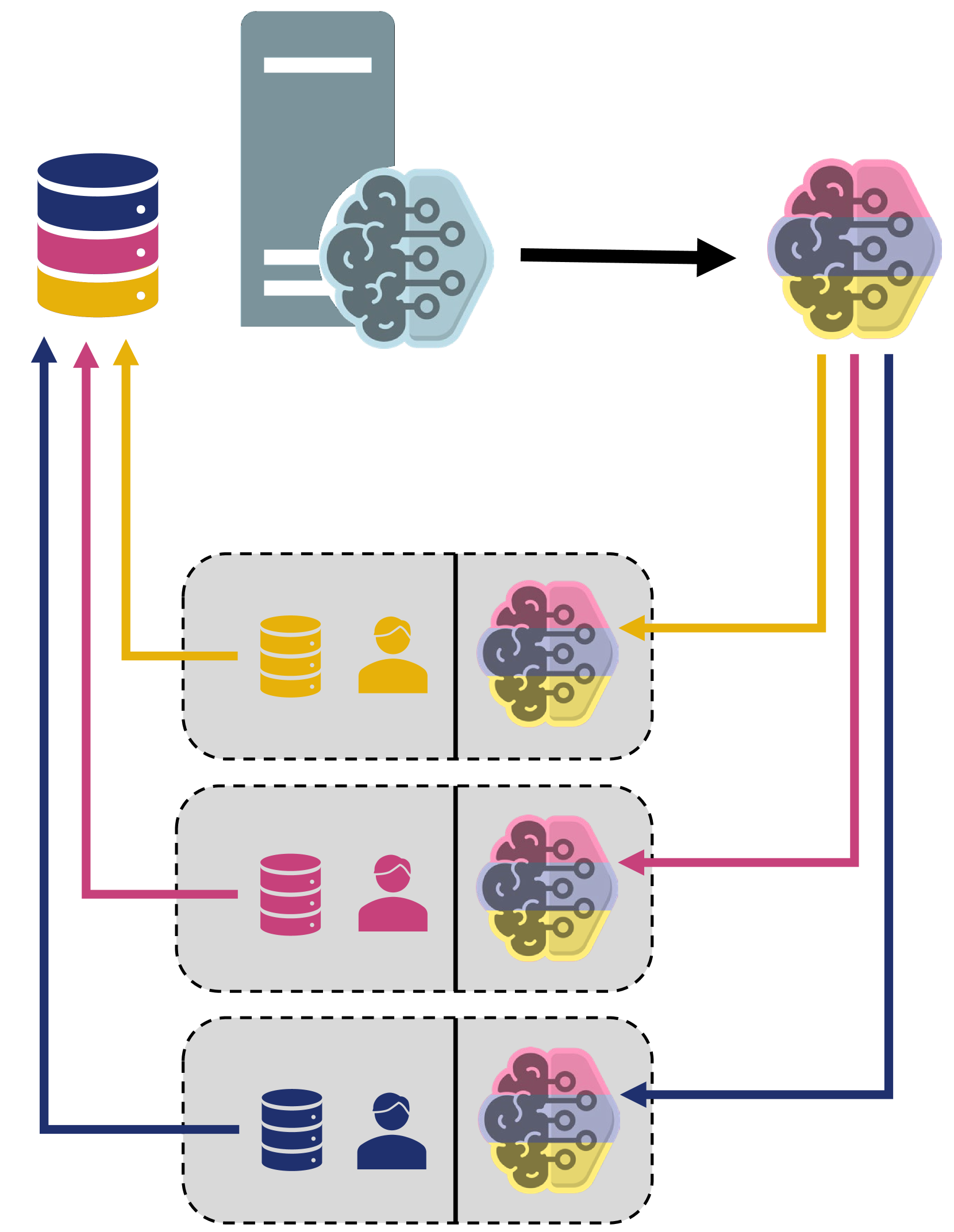
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024
Efficient Model Compression for Hierarchical Federated Learning
Xi Zhu, Songcan Yu, Junbo Wang, Qinglin Yang
0
0
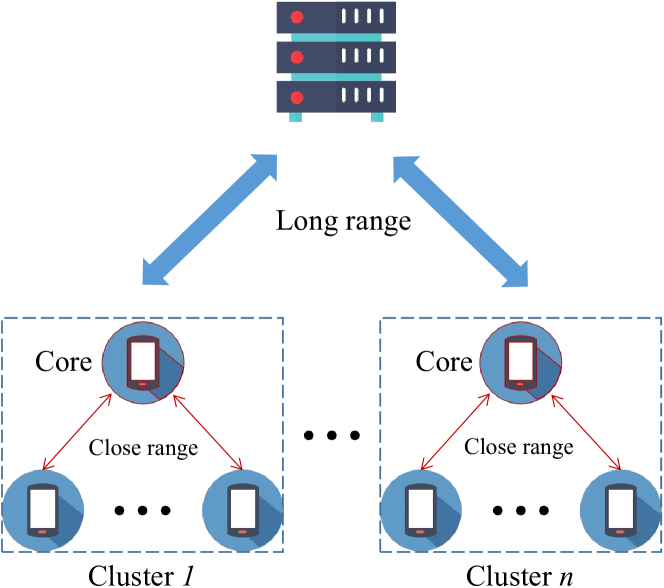
Federated learning (FL), as an emerging collaborative learning paradigm, has garnered significant attention due to its capacity to preserve privacy within distributed learning systems. In these systems, clients collaboratively train a unified neural network model using their local datasets and share model parameters rather than raw data, enhancing privacy. Predominantly, FL systems are designed for mobile and edge computing environments where training typically occurs over wireless networks. Consequently, as model sizes increase, the conventional FL frameworks increasingly consume substantial communication resources. To address this challenge and improve communication efficiency, this paper introduces a novel hierarchical FL framework that integrates the benefits of clustered FL and model compression. We present an adaptive clustering algorithm that identifies a core client and dynamically organizes clients into clusters. Furthermore, to enhance transmission efficiency, each core client implements a local aggregation with compression (LC aggregation) algorithm after collecting compressed models from other clients within the same cluster. Simulation results affirm that our proposed algorithms not only maintain comparable predictive accuracy but also significantly reduce energy consumption relative to existing FL mechanisms.
5/29/2024
Toward efficient resource utilization at edge nodes in federated learning
Sadi Alawadi, Addi Ait-Mlouk, Salman Toor, Andreas Hellander
0
0
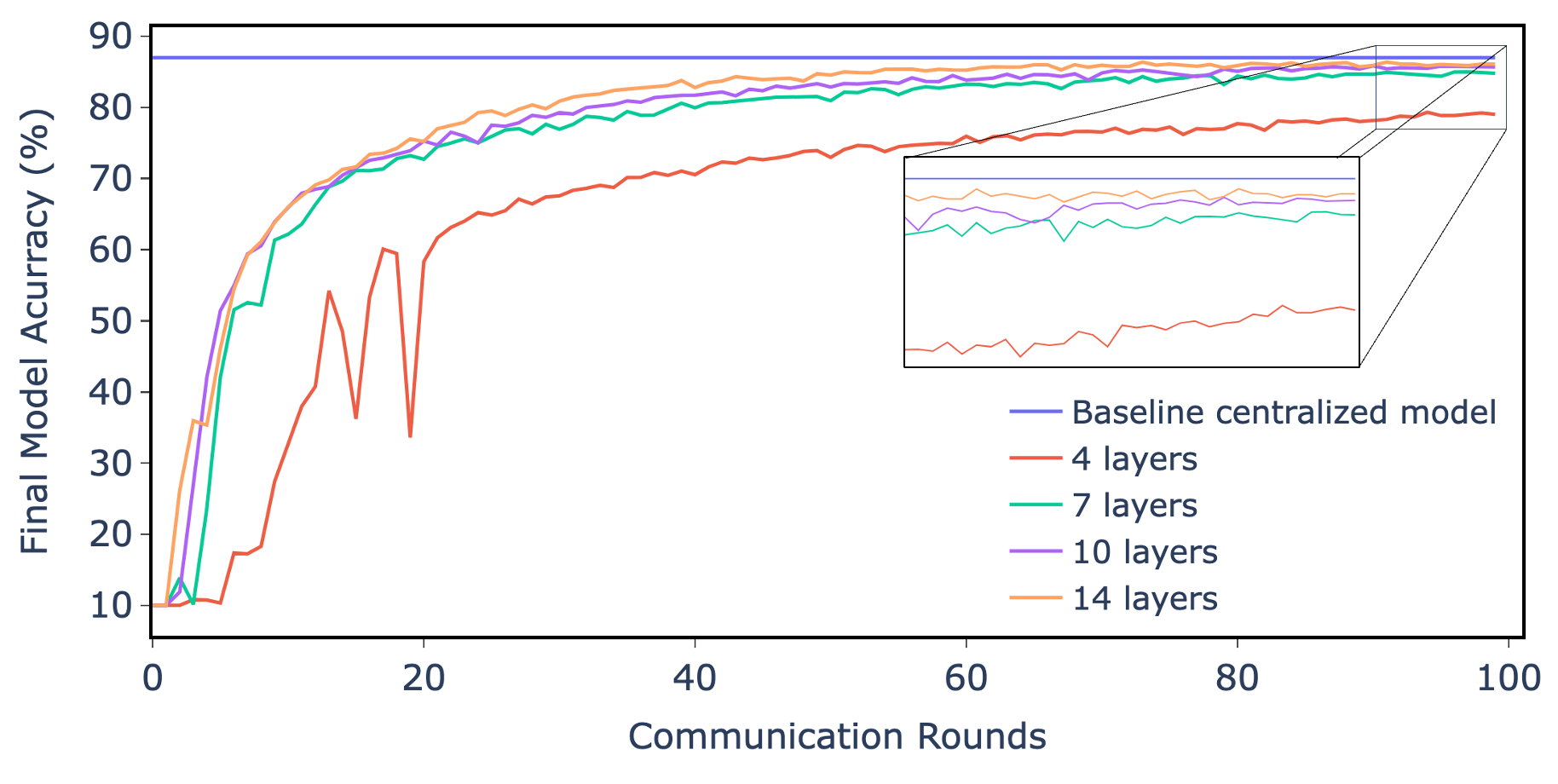
Federated learning (FL) enables edge nodes to collaboratively contribute to constructing a global model without sharing their data. This is accomplished by devices computing local, private model updates that are then aggregated by a server. However, computational resource constraints and network communication can become a severe bottleneck for larger model sizes typical for deep learning applications. Edge nodes tend to have limited hardware resources (RAM, CPU), and the network bandwidth and reliability at the edge is a concern for scaling federated fleet applications. In this paper, we propose and evaluate a FL strategy inspired by transfer learning in order to reduce resource utilization on devices, as well as the load on the server and network in each global training round. For each local model update, we randomly select layers to train, freezing the remaining part of the model. In doing so, we can reduce both server load and communication costs per round by excluding all untrained layer weights from being transferred to the server. The goal of this study is to empirically explore the potential trade-off between resource utilization on devices and global model convergence under the proposed strategy. We implement the approach using the federated learning framework FEDn. A number of experiments were carried out over different datasets (CIFAR-10, CASA, and IMDB), performing different tasks using different deep-learning model architectures. Our results show that training the model partially can accelerate the training process, efficiently utilizes resources on-device, and reduce the data transmission by around 75% and 53% when we train 25%, and 50% of the model layers, respectively, without harming the resulting global model accuracy.
6/12/2024
Communication-Efficient Model Aggregation with Layer Divergence Feedback in Federated Learning
Liwei Wang, Jun Li, Wen Chen, Qingqing Wu, Ming Ding
0
0
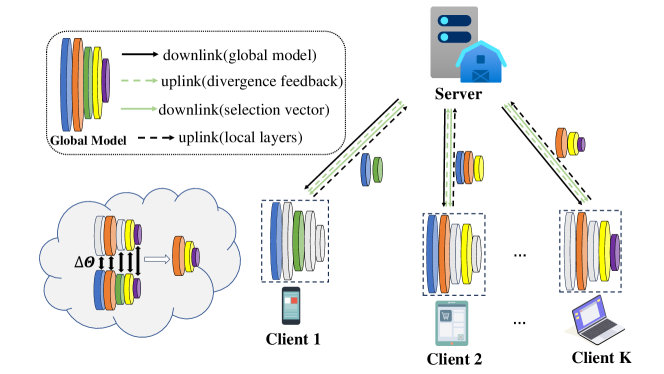
Federated Learning (FL) facilitates collaborative machine learning by training models on local datasets, and subsequently aggregating these local models at a central server. However, the frequent exchange of model parameters between clients and the central server can result in significant communication overhead during the FL training process. To solve this problem, this paper proposes a novel FL framework, the Model Aggregation with Layer Divergence Feedback mechanism (FedLDF). Specifically, we calculate model divergence between the local model and the global model from the previous round. Then through model layer divergence feedback, the distinct layers of each client are uploaded and the amount of data transferred is reduced effectively. Moreover, the convergence bound reveals that the access ratio of clients has a positive correlation with model performance. Simulation results show that our algorithm uploads local models with reduced communication overhead while upholding a superior global model performance.
4/15/2024