Federated Learning Architectures: A Performance Evaluation with Crop Yield Prediction Application

0

Sign in to get full access
Overview
- Compares the performance of different federated learning architectures for a crop yield prediction application
- Evaluates the trade-offs between model accuracy, communication cost, and training time
- Provides insights into the suitability of federated learning approaches for agricultural applications
Plain English Explanation
This research paper examines different ways of implementing federated learning, a technique that allows multiple devices or organizations to collaboratively train a machine learning model without sharing their individual data. The researchers tested these federated learning architectures on the problem of predicting crop yields, which is an important task in agricultural applications.
The key idea behind federated learning is that the model is trained on many devices in parallel, and only the model updates are shared with a central server, rather than the raw data. This can be beneficial for privacy, as the sensitive data never leaves the local device. However, it also introduces challenges in terms of communication overhead and model convergence.
The researchers explored different ways of organizing the federated learning process, such as having a central server coordinate the updates, or allowing the devices to self-organize into clusters and update each other directly. They measured the trade-offs between the accuracy of the final crop yield prediction model, the amount of communication required, and the total training time.
Technical Explanation
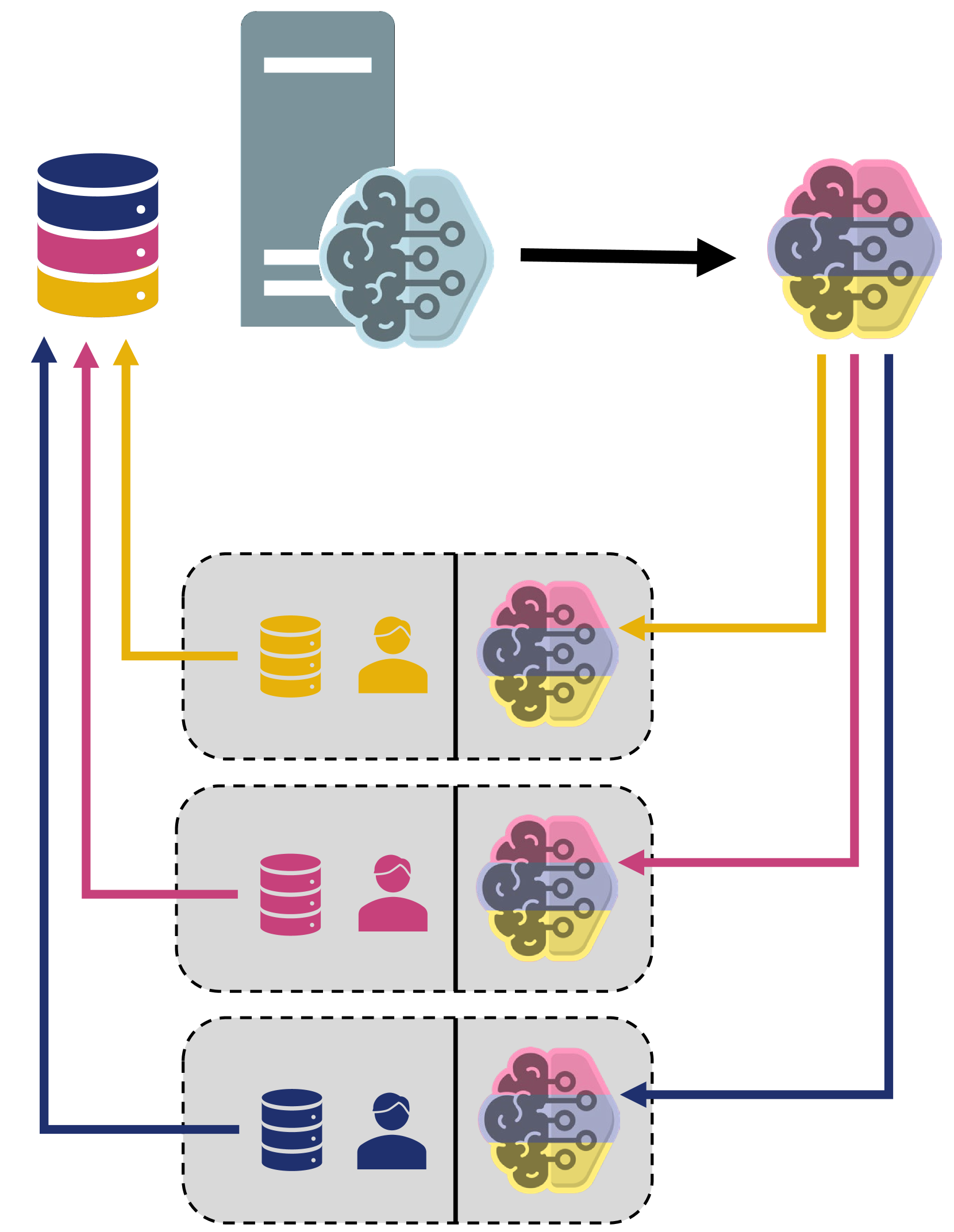
The paper evaluates three federated learning architectures for a crop yield prediction task:
-
Centralized Federated Learning: A central server coordinates the training process, aggregating model updates from the client devices.
-
Clustered Federated Learning: Client devices self-organize into clusters and share model updates within their clusters, reducing communication with the central server.
-
Proximity-based Self-Federated Learning: Similar to clustered federated learning, but the clusters are formed based on the geographic proximity of the client devices.
The researchers used a crop yield dataset and a convolutional neural network model to evaluate the performance of these three architectures. They measured the model accuracy, total training time, and communication cost (the amount of data exchanged between devices and the server) for each approach.
The results showed that the clustered and proximity-based approaches achieved higher model accuracy compared to the centralized approach, but at the cost of increased training time and communication overhead. The proximity-based approach performed best in terms of balancing model accuracy, training time, and communication cost.
Critical Analysis
The paper provides a thorough and well-designed evaluation of different federated learning architectures for a practical agricultural application. The researchers acknowledge several limitations and areas for future research:
- The experiments were conducted using a single dataset and model architecture, so the generalizability of the findings to other agricultural applications is uncertain.
- The paper does not address the issue of client device heterogeneity, which can be a significant challenge in real-world federated learning deployments.
- The analysis of communication cost is limited to the amount of data exchanged and does not consider the impact of network latency or bandwidth constraints.
- The paper does not explore the potential privacy and security implications of the different federated learning architectures.
Future research could expand the evaluation to include a wider range of datasets, model types, and device configurations to better understand the trade-offs and suitability of federated learning for agricultural applications. Incorporating additional metrics, such as privacy preservation and energy efficiency, would also be valuable.
Conclusion
This research paper provides a comprehensive evaluation of federated learning architectures for a crop yield prediction task, highlighting the trade-offs between model accuracy, communication cost, and training time. The findings suggest that decentralized approaches, such as clustered and proximity-based federated learning, can offer advantages over a centralized architecture, particularly in terms of model performance. These insights can inform the design and deployment of federated learning systems in agricultural and other real-world applications where data privacy and resource constraints are important considerations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Federated Learning Architectures: A Performance Evaluation with Crop Yield Prediction Application
Anwesha Mukherjee, Rajkumar Buyya
Federated learning has become an emerging technology for data analysis for IoT applications. This paper implements centralized and decentralized federated learning frameworks for crop yield prediction based on Long Short-Term Memory Network. For centralized federated learning, multiple clients and one server is considered, where the clients exchange their model updates with the server that works as the aggregator to build the global model. For the decentralized framework, a collaborative network is formed among the devices either using ring topology or using mesh topology. In this network, each device receives model updates from the neighbour devices, and performs aggregation to build the upgraded model. The performance of the centralized and decentralized federated learning frameworks are evaluated in terms of prediction accuracy, precision, recall, F1-Score, and training time. The experimental results present that $geq$97% and $>$97.5% prediction accuracy are achieved using the centralized and decentralized federated learning-based frameworks respectively. The results also show that the using centralized federated learning the response time can be reduced by $sim$75% than the cloud-only framework. Finally, the future research directions of the use of federated learning in crop yield prediction are explored in this paper.
Read more8/7/2024

0
SCALE: Self-regulated Clustered federAted LEarning in a Homogeneous Environment
Sai Puppala, Ismail Hossain, Md Jahangir Alam, Sajedul Talukder, Zahidur Talukder, Syed Bahauddin
Federated Learning (FL) has emerged as a transformative approach for enabling distributed machine learning while preserving user privacy, yet it faces challenges like communication inefficiencies and reliance on centralized infrastructures, leading to increased latency and costs. This paper presents a novel FL methodology that overcomes these limitations by eliminating the dependency on edge servers, employing a server-assisted Proximity Evaluation for dynamic cluster formation based on data similarity, performance indices, and geographical proximity. Our integrated approach enhances operational efficiency and scalability through a Hybrid Decentralized Aggregation Protocol, which merges local model training with peer-to-peer weight exchange and a centralized final aggregation managed by a dynamically elected driver node, significantly curtailing global communication overhead. Additionally, the methodology includes Decentralized Driver Selection, Check-pointing to reduce network traffic, and a Health Status Verification Mechanism for system robustness. Validated using the breast cancer dataset, our architecture not only demonstrates a nearly tenfold reduction in communication overhead but also shows remarkable improvements in reducing training latency and energy consumption while maintaining high learning performance, offering a scalable, efficient, and privacy-preserving solution for the future of federated learning ecosystems.
Read more7/29/2024
0
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
Read more5/28/2024
🤖
0
Federated learning in food research
Zuzanna Fendor, Bas H. M. van der Velden, Xinxin Wang, Andrea Jr. Carnoli, Osman Mutlu, Ali Hurriyetou{g}lu
Research in the food domain is at times limited due to data sharing obstacles, such as data ownership, privacy requirements, and regulations. While important, these obstacles can restrict data-driven methods such as machine learning. Federated learning, the approach of training models on locally kept data and only sharing the learned parameters, is a potential technique to alleviate data sharing obstacles. This systematic review investigates the use of federated learning within the food domain, structures included papers in a federated learning framework, highlights knowledge gaps, and discusses potential applications. A total of 41 papers were included in the review. The current applications include solutions to water and milk quality assessment, cybersecurity of water processing, pesticide residue risk analysis, weed detection, and fraud detection, focusing on centralized horizontal federated learning. One of the gaps found was the lack of vertical or transfer federated learning and decentralized architectures.
Read more6/11/2024