Federated Learning Can Find Friends That Are Advantageous

0
📶
Sign in to get full access
Overview
- Federated Learning (FL) is a distributed machine learning approach where multiple clients collaborate to train a shared model without sharing their local data.
- The distributed and heterogeneous nature of client data in FL presents both opportunities and challenges.
- While collaboration can enhance the learning process, not all collaborations are beneficial, and some may even be detrimental.
- This study introduces a novel algorithm that assigns adaptive aggregation weights to clients participating in FL training, identifying those with data distributions most conducive to a specific learning objective.
Plain English Explanation
Federated Learning (FL) allows multiple devices or "clients" to train a shared machine learning model without sharing their private data. This distributed approach can be very powerful, as the combined knowledge of the clients can result in a better model. However, the clients may have very different data, which can sometimes make the collaboration less effective.
The researchers in this study developed a new way to address this challenge. Their algorithm assigns different weights to the updates from each client, based on how well their data aligns with the learning objective. This helps the model focus on the most relevant and helpful information, rather than treating all clients equally.
The researchers show that their method performs at least as well as the traditional approach, where only clients with the same data distribution are used. And in many cases, it outperforms the traditional method, demonstrating the value of judicious client selection in Federated Learning. This work lays the foundation for more streamlined and effective FL implementations in the future.
Technical Explanation
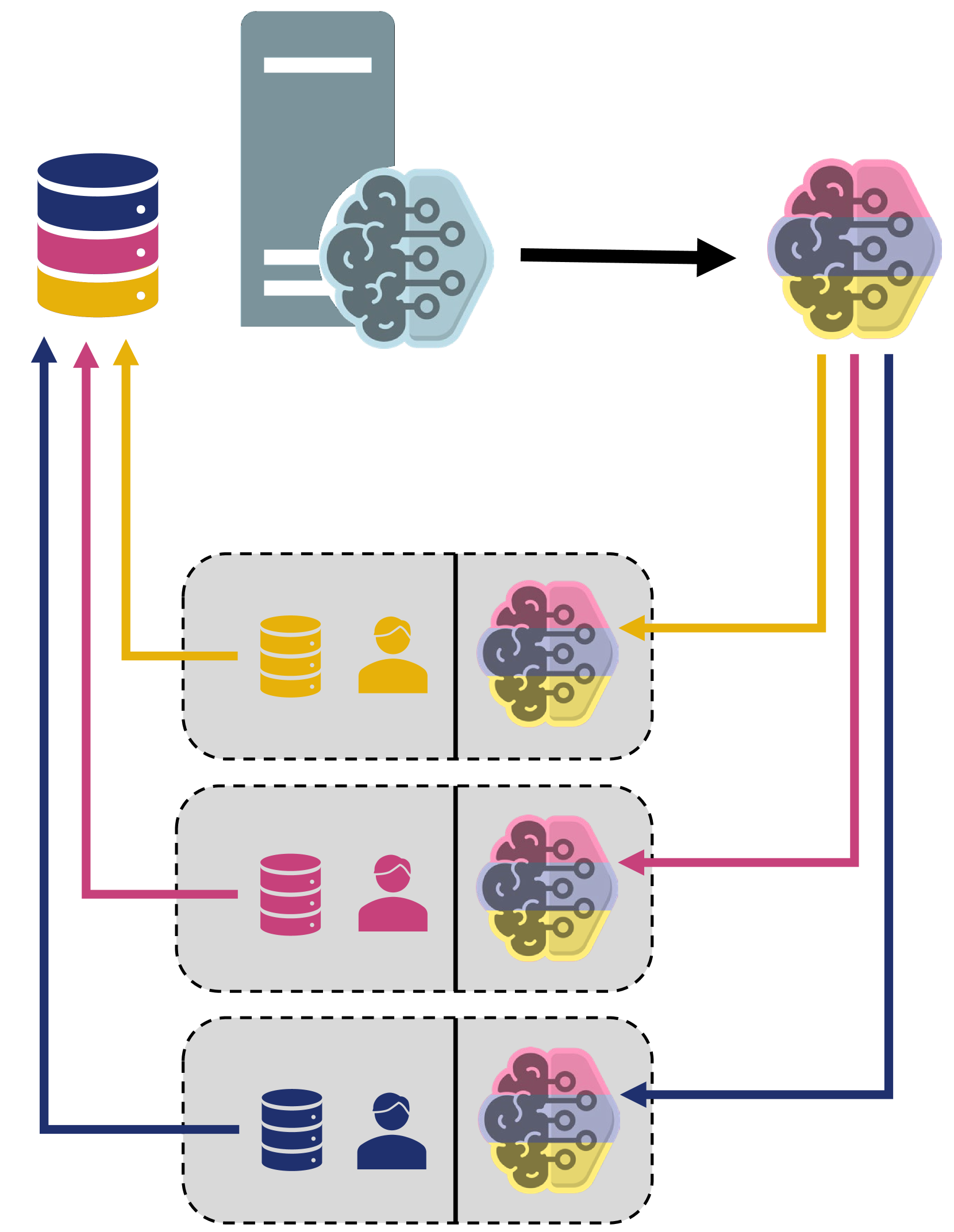
The researchers introduce a novel Adaptive Federated Aggregation (AFA) algorithm that assigns different aggregation weights to clients participating in the Federated Learning (FL) training process. The goal is to identify clients with data distributions that are most conducive to the specific learning objective, and give their updates higher priority during the aggregation step.
The AFA algorithm works as follows:
- It first estimates the similarity between each client's data distribution and the target distribution for the learning task.
- It then assigns higher aggregation weights to clients with more similar data distributions, and lower weights to those with less similar distributions.
- This adaptive weighting scheme is applied during the FL training process, where the server aggregates the model updates received from the clients.
The researchers prove that the AFA algorithm converges no worse than the traditional FL approach that only aggregates updates from clients with the same data distribution. They also provide empirical evaluations showing that collaborations guided by their AFA algorithm outperform the traditional FL methods.
Critical Analysis
The paper highlights the critical role of client selection in Federated Learning, where not all collaborations are equally beneficial. While the proposed AFA algorithm demonstrates promising results, the researchers acknowledge that further research is needed to address potential limitations:
- The algorithm assumes that the target data distribution is known a priori, which may not always be the case in real-world scenarios.
- The computational overhead of estimating the similarity between client data distributions and the target distribution could be non-trivial, especially in large-scale FL systems.
- The paper focuses on a centralized FL setting, and it would be valuable to investigate decentralized personalized approaches that can better handle data heterogeneity.
Additionally, the researchers do not explore the potential negative impacts that their client selection strategy might have on the privacy and fairness of the FL system. These are important considerations that should be addressed in future research.
Conclusion
This study presents a novel Adaptive Federated Aggregation (AFA) algorithm that addresses the challenges of data heterogeneity in Federated Learning. By adaptively assigning weights to client updates based on their data distribution similarity, the AFA algorithm is able to outperform traditional FL approaches and demonstrate the critical importance of judicious client selection.
The findings of this research lay the groundwork for more streamlined and effective FL implementations in the future, paving the way for wider adoption of this distributed machine learning technique. As the field of Federated Learning continues to evolve, it will be crucial to address the remaining challenges and potential pitfalls highlighted in this paper to ensure the technology achieves its full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Federated Learning Can Find Friends That Are Advantageous
Nazarii Tupitsa, Samuel Horv'ath, Martin Tak'av{c}, Eduard Gorbunov
In Federated Learning (FL), the distributed nature and heterogeneity of client data present both opportunities and challenges. While collaboration among clients can significantly enhance the learning process, not all collaborations are beneficial; some may even be detrimental. In this study, we introduce a novel algorithm that assigns adaptive aggregation weights to clients participating in FL training, identifying those with data distributions most conducive to a specific learning objective. We demonstrate that our aggregation method converges no worse than the method that aggregates only the updates received from clients with the same data distribution. Furthermore, empirical evaluations consistently reveal that collaborations guided by our algorithm outperform traditional FL approaches. This underscores the critical role of judicious client selection and lays the foundation for more streamlined and effective FL implementations in the coming years.
Read more7/18/2024
0
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
Read more5/28/2024

0
FedClust: Tackling Data Heterogeneity in Federated Learning through Weight-Driven Client Clustering
Md Sirajul Islam, Simin Javaherian, Fei Xu, Xu Yuan, Li Chen, Nian-Feng Tzeng
Federated learning (FL) is an emerging distributed machine learning paradigm that enables collaborative training of machine learning models over decentralized devices without exposing their local data. One of the major challenges in FL is the presence of uneven data distributions across client devices, violating the well-known assumption of independent-and-identically-distributed (IID) training samples in conventional machine learning. To address the performance degradation issue incurred by such data heterogeneity, clustered federated learning (CFL) shows its promise by grouping clients into separate learning clusters based on the similarity of their local data distributions. However, state-of-the-art CFL approaches require a large number of communication rounds to learn the distribution similarities during training until the formation of clusters is stabilized. Moreover, some of these algorithms heavily rely on a predefined number of clusters, thus limiting their flexibility and adaptability. In this paper, we propose {em FedClust}, a novel approach for CFL that leverages the correlation between local model weights and the data distribution of clients. {em FedClust} groups clients into clusters in a one-shot manner by measuring the similarity degrees among clients based on the strategically selected partial weights of locally trained models. We conduct extensive experiments on four benchmark datasets with different non-IID data settings. Experimental results demonstrate that {em FedClust} achieves higher model accuracy up to $sim$45% as well as faster convergence with a significantly reduced communication cost up to 2.7$times$ compared to its state-of-the-art counterparts.
Read more7/11/2024

0
An Aggregation-Free Federated Learning for Tackling Data Heterogeneity
Yuan Wang, Huazhu Fu, Renuga Kanagavelu, Qingsong Wei, Yong Liu, Rick Siow Mong Goh
The performance of Federated Learning (FL) hinges on the effectiveness of utilizing knowledge from distributed datasets. Traditional FL methods adopt an aggregate-then-adapt framework, where clients update local models based on a global model aggregated by the server from the previous training round. This process can cause client drift, especially with significant cross-client data heterogeneity, impacting model performance and convergence of the FL algorithm. To address these challenges, we introduce FedAF, a novel aggregation-free FL algorithm. In this framework, clients collaboratively learn condensed data by leveraging peer knowledge, the server subsequently trains the global model using the condensed data and soft labels received from the clients. FedAF inherently avoids the issue of client drift, enhances the quality of condensed data amid notable data heterogeneity, and improves the global model performance. Extensive numerical studies on several popular benchmark datasets show FedAF surpasses various state-of-the-art FL algorithms in handling label-skew and feature-skew data heterogeneity, leading to superior global model accuracy and faster convergence.
Read more5/1/2024