FedFQ: Federated Learning with Fine-Grained Quantization

0

Sign in to get full access
Overview
- FedFQ is a new federated learning technique that uses fine-grained quantization to improve communication efficiency and model performance.
- Federated learning allows multiple devices to collaboratively train a shared model without sharing their raw data.
- Fine-grained quantization reduces the amount of data that needs to be exchanged during model updates, reducing communication costs.
- The paper proposes adaptive quantization strategies to further optimize the quantization process.
Plain English Explanation
FedFQ: Federated Learning with Fine-Grained Quantization is a new technique for federated learning that aims to improve the process by using fine-grained quantization.
Federated learning is a way for multiple devices, like smartphones or sensors, to work together to train a shared machine learning model without each device having to share its private data. Instead, the devices collaborate by sending model updates back to a central server, which aggregates the updates to improve the shared model.
Fine-grained quantization is a method of reducing the amount of data that needs to be sent during these model updates. It does this by converting the full-precision numbers in the model updates into smaller, lower-precision numbers. This reduces the communication costs and makes the overall federated learning process more efficient.
The key innovation in FedFQ is the use of adaptive quantization strategies. These strategies dynamically adjust the quantization process based on factors like the device's computational power or network conditions. This helps to further optimize the tradeoff between model performance and communication efficiency.
By combining federated learning with fine-grained and adaptive quantization, FedFQ aims to enable federated learning applications that are more practical and scalable, especially in resource-constrained environments.
Technical Explanation
The FedFQ paper proposes a new federated learning framework that incorporates fine-grained and adaptive quantization strategies to improve communication efficiency and model performance.
In traditional federated learning, client devices send full-precision model updates to the central server, which can be costly in terms of communication bandwidth. FedFQ addresses this by applying fine-grained quantization to the model updates before transmission. This reduces the amount of data that needs to be exchanged while still maintaining model accuracy.
The paper introduces two key quantization strategies:
-
Fine-grained Quantization: Rather than quantizing the entire model update, FedFQ quantizes the update at a more granular level, such as by layer or even parameter. This allows for a more precise control over the quantization process.
-
Adaptive Quantization: FedFQ dynamically adjusts the quantization parameters based on factors like the device's computational capacity, network conditions, and the current training state. This helps to strike the optimal balance between model performance and communication efficiency.
The authors evaluate FedFQ on several benchmark datasets and demonstrate significant improvements in communication cost and model accuracy compared to standard federated learning approaches. For example, they show that FedFQ can achieve up to 4.5x reduction in communication overhead while maintaining comparable model performance.
Critical Analysis
The FedFQ paper presents a novel and promising approach to improving the efficiency of federated learning. The use of fine-grained and adaptive quantization strategies is a clever way to reduce the communication costs associated with federated learning, which is a key challenge in deploying these systems at scale.
One potential limitation of the work is that the evaluation is conducted on relatively small-scale datasets and models. It would be valuable to see how FedFQ performs on larger, more complex tasks that are more representative of real-world federated learning applications.
Additionally, the paper does not fully address the potential impact of quantization on the model's generalization performance. While the results show that FedFQ can maintain model accuracy, further analysis on the model's robustness and transfer learning capabilities would be helpful.
Another area for further research could be the integration of FedFQ with other federated learning techniques, such as differential privacy or hierarchical aggregation, to create even more powerful and secure federated learning systems.
Overall, the FedFQ paper represents an important contribution to the field of federated learning, and the proposed techniques have the potential to significantly improve the practicality and scalability of federated learning in a wide range of applications.
Conclusion
The FedFQ paper introduces a novel federated learning framework that combines fine-grained and adaptive quantization strategies to improve communication efficiency and model performance. By reducing the amount of data that needs to be exchanged during the federated learning process, FedFQ has the potential to enable more practical and scalable federated learning applications, especially in resource-constrained environments.
The paper's experimental results demonstrate significant improvements in communication cost and model accuracy compared to standard federated learning approaches. While further research is needed to fully understand the impact of quantization on model robustness and generalization, the core ideas presented in FedFQ represent an important step forward in the field of federated learning.
As federated learning continues to gain traction in a wide range of industries, techniques like FedFQ will become increasingly important for making these systems more efficient, reliable, and accessible to a broad range of users and devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FedFQ: Federated Learning with Fine-Grained Quantization
Haowei Li, Weiying Xie, Hangyu Ye, Jitao Ma, Shuran Ma, Yunsong Li
Federated learning (FL) is a decentralized approach, enabling multiple participants to collaboratively train a model while ensuring the protection of data privacy. The transmission of updates from numerous edge clusters to the server creates a significant communication bottleneck in FL. Quantization is an effective compression technology, showcasing immense potential in addressing this bottleneck problem. The Non-IID nature of FL renders it sensitive to quantization. Existing quantized FL frameworks inadequately balance high compression ratios and superior convergence performance by roughly employing a uniform quantization bit-width on the client-side. In this work, we propose a communication-efficient FL algorithm with a fine-grained adaptive quantization strategy (FedFQ). FedFQ addresses the trade-off between achieving high communication compression ratios and maintaining superior convergence performance by introducing parameter-level quantization. Specifically, we have designed a Constraint-Guided Simulated Annealing algorithm to determine specific quantization schemes. We derive the convergence of FedFQ, demonstrating its superior convergence performance compared to existing quantized FL algorithms. We conducted extensive experiments on multiple benchmarks and demonstrated that, while maintaining lossless performance, FedFQ achieves a compression ratio of 27 times to 63 times compared to the baseline experiment.
Read more8/20/2024

0
FedAQ: Communication-Efficient Federated Edge Learning via Joint Uplink and Downlink Adaptive Quantization
Linping Qu, Shenghui Song, Chi-Ying Tsui
Federated learning (FL) is a powerful machine learning paradigm which leverages the data as well as the computational resources of clients, while protecting clients' data privacy. However, the substantial model size and frequent aggregation between the server and clients result in significant communication overhead, making it challenging to deploy FL in resource-limited wireless networks. In this work, we aim to mitigate the communication overhead by using quantization. Previous research on quantization has primarily focused on the uplink communication, employing either fixed-bit quantization or adaptive quantization methods. In this work, we introduce a holistic approach by joint uplink and downlink adaptive quantization to reduce the communication overhead. In particular, we optimize the learning convergence by determining the optimal uplink and downlink quantization bit-length, with a communication energy constraint. Theoretical analysis shows that the optimal quantization levels depend on the range of model gradients or weights. Based on this insight, we propose a decreasing-trend quantization for the uplink and an increasing-trend quantization for the downlink, which aligns with the change of the model parameters during the training process. Experimental results show that, the proposed joint uplink and downlink adaptive quantization strategy can save up to 66.7% energy compared with the existing schemes.
Read more6/27/2024

0
QMGeo: Differentially Private Federated Learning via Stochastic Quantization with Mixed Truncated Geometric Distribution
Zixi Wang, M. Cenk Gursoy
Federated learning (FL) is a framework which allows multiple users to jointly train a global machine learning (ML) model by transmitting only model updates under the coordination of a parameter server, while being able to keep their datasets local. One key motivation of such distributed frameworks is to provide privacy guarantees to the users. However, preserving the users' datasets locally is shown to be not sufficient for privacy. Several differential privacy (DP) mechanisms have been proposed to provide provable privacy guarantees by introducing randomness into the framework, and majority of these mechanisms rely on injecting additive noise. FL frameworks also face the challenge of communication efficiency, especially as machine learning models grow in complexity and size. Quantization is a commonly utilized method, reducing the communication cost by transmitting compressed representation of the underlying information. Although there have been several studies on DP and quantization in FL, the potential contribution of the quantization method alone in providing privacy guarantees has not been extensively analyzed yet. We in this paper present a novel stochastic quantization method, utilizing a mixed geometric distribution to introduce the randomness needed to provide DP, without any additive noise. We provide convergence analysis for our framework and empirically study its performance.
Read more6/12/2024
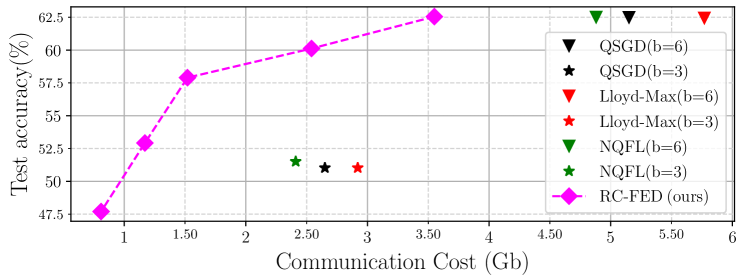
0
Rate-Constrained Quantization for Communication-Efficient Federated Learning
Shayan Mohajer Hamidi, Ali Bereyhi
Quantization is a common approach to mitigate the communication cost of federated learning (FL). In practice, the quantized local parameters are further encoded via an entropy coding technique, such as Huffman coding, for efficient data compression. In this case, the exact communication overhead is determined by the bit rate of the encoded gradients. Recognizing this fact, this work deviates from the existing approaches in the literature and develops a novel quantized FL framework, called textbf{r}ate-textbf{c}onstrained textbf{fed}erated learning (RC-FED), in which the gradients are quantized subject to both fidelity and data rate constraints. We formulate this scheme, as a joint optimization in which the quantization distortion is minimized while the rate of encoded gradients is kept below a target threshold. This enables for a tunable trade-off between quantization distortion and communication cost. We analyze the convergence behavior of RC-FED, and show its superior performance against baseline quantized FL schemes on several datasets.
Read more9/11/2024