Rate-Constrained Quantization for Communication-Efficient Federated Learning

0
Sign in to get full access
Overview
- This paper proposes a rate-constrained quantization approach for communication-efficient federated learning.
- The key idea is to adaptively quantize the model updates at each client, reducing the communication bandwidth required during the federated training process.
- The approach aims to balance the tradeoff between the model accuracy and the communication cost.
Plain English Explanation
The paper describes a technique called rate-constrained quantization that can make federated learning more efficient. In federated learning, multiple devices or clients collaboratively train a machine learning model without sharing their private data.
The main challenge is that the model updates from each client need to be communicated to a central server, which can consume a lot of network bandwidth. This paper's key insight is to adaptively quantize the model updates at each client before transmission. Quantization involves representing the model parameters with fewer bits, reducing the communication cost.
The method tries to find the right balance between model accuracy and communication efficiency. It adapts the level of quantization for each client based on factors like the available network bandwidth and the importance of the model updates. This allows the system to minimize the communication overhead while still maintaining good model performance.
Technical Explanation
The paper introduces a rate-constrained quantization approach for communication-efficient federated learning. The core idea is to adaptively quantize the model updates at each client before transmitting them to the central server, reducing the required communication bandwidth.
The method first assigns a quantization rate to each client based on factors like the available network bandwidth and the importance of the client's model updates. It then uses this rate to determine the appropriate level of quantization for the client's updates. This allows the system to balance the tradeoff between model accuracy and communication cost.
The paper also introduces a gradient clipping technique to further improve the quantization efficiency. This involves capping the magnitude of the model gradients before quantization, which helps preserve the important signal while reducing the overall bit rate.
The authors evaluate their approach on several benchmark datasets and show that it can achieve significant communication savings compared to standard federated learning, while maintaining comparable model performance. They also demonstrate the effectiveness of the gradient clipping technique in further reducing the communication overhead.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed rate-constrained quantization approach. The authors explore the tradeoffs between model accuracy and communication efficiency, and provide insights into the factors that influence these tradeoffs.
However, the paper does not address some potential limitations or areas for further research. For example, the approach assumes that the clients' network bandwidth and the importance of their model updates are known a priori. In practice, these factors may be difficult to estimate accurately, which could impact the performance of the system.
Additionally, the paper focuses on the single-task federated learning scenario. It would be interesting to see how the rate-constrained quantization approach would perform in more complex, multi-task or continual learning settings, where the importance of different model parameters may change over time.
Overall, the paper makes a valuable contribution to the field of communication-efficient federated learning, and the proposed techniques could be useful in a variety of real-world applications where data privacy and network constraints are important considerations.
Conclusion
This paper presents a novel rate-constrained quantization approach for improving the communication efficiency of federated learning. By adaptively quantizing the model updates at each client based on factors like available bandwidth and update importance, the method can significantly reduce the overall communication cost while maintaining comparable model performance.
The technical insights and empirical evaluation in this work represent an important step forward in addressing the challenges of deploying federated learning systems in resource-constrained environments. The techniques described could have broad applicability in areas like mobile, edge, and IoT computing, where minimizing network usage is crucial for practical deployment.
Further research is needed to address some of the potential limitations, such as the need for accurate a priori knowledge of client-specific factors. Nonetheless, this paper provides a solid foundation for developing communication-efficient federated learning algorithms that can enable widespread adoption of this privacy-preserving machine learning paradigm.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rate-Constrained Quantization for Communication-Efficient Federated Learning
Shayan Mohajer Hamidi, Ali Bereyhi
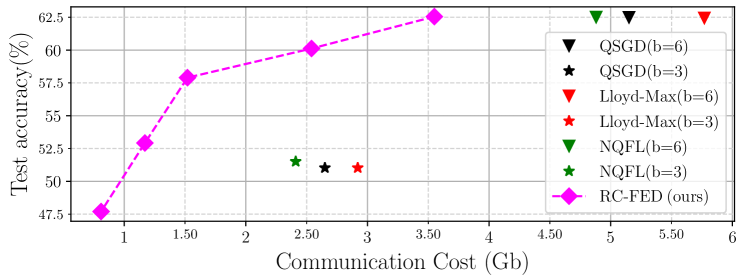
Quantization is a common approach to mitigate the communication cost of federated learning (FL). In practice, the quantized local parameters are further encoded via an entropy coding technique, such as Huffman coding, for efficient data compression. In this case, the exact communication overhead is determined by the bit rate of the encoded gradients. Recognizing this fact, this work deviates from the existing approaches in the literature and develops a novel quantized FL framework, called textbf{r}ate-textbf{c}onstrained textbf{fed}erated learning (RC-FED), in which the gradients are quantized subject to both fidelity and data rate constraints. We formulate this scheme, as a joint optimization in which the quantization distortion is minimized while the rate of encoded gradients is kept below a target threshold. This enables for a tunable trade-off between quantization distortion and communication cost. We analyze the convergence behavior of RC-FED, and show its superior performance against baseline quantized FL schemes on several datasets.
Read more9/11/2024

0
FedFQ: Federated Learning with Fine-Grained Quantization
Haowei Li, Weiying Xie, Hangyu Ye, Jitao Ma, Shuran Ma, Yunsong Li
Federated learning (FL) is a decentralized approach, enabling multiple participants to collaboratively train a model while ensuring the protection of data privacy. The transmission of updates from numerous edge clusters to the server creates a significant communication bottleneck in FL. Quantization is an effective compression technology, showcasing immense potential in addressing this bottleneck problem. The Non-IID nature of FL renders it sensitive to quantization. Existing quantized FL frameworks inadequately balance high compression ratios and superior convergence performance by roughly employing a uniform quantization bit-width on the client-side. In this work, we propose a communication-efficient FL algorithm with a fine-grained adaptive quantization strategy (FedFQ). FedFQ addresses the trade-off between achieving high communication compression ratios and maintaining superior convergence performance by introducing parameter-level quantization. Specifically, we have designed a Constraint-Guided Simulated Annealing algorithm to determine specific quantization schemes. We derive the convergence of FedFQ, demonstrating its superior convergence performance compared to existing quantized FL algorithms. We conducted extensive experiments on multiple benchmarks and demonstrated that, while maintaining lossless performance, FedFQ achieves a compression ratio of 27 times to 63 times compared to the baseline experiment.
Read more8/20/2024

0
FedAQ: Communication-Efficient Federated Edge Learning via Joint Uplink and Downlink Adaptive Quantization
Linping Qu, Shenghui Song, Chi-Ying Tsui
Federated learning (FL) is a powerful machine learning paradigm which leverages the data as well as the computational resources of clients, while protecting clients' data privacy. However, the substantial model size and frequent aggregation between the server and clients result in significant communication overhead, making it challenging to deploy FL in resource-limited wireless networks. In this work, we aim to mitigate the communication overhead by using quantization. Previous research on quantization has primarily focused on the uplink communication, employing either fixed-bit quantization or adaptive quantization methods. In this work, we introduce a holistic approach by joint uplink and downlink adaptive quantization to reduce the communication overhead. In particular, we optimize the learning convergence by determining the optimal uplink and downlink quantization bit-length, with a communication energy constraint. Theoretical analysis shows that the optimal quantization levels depend on the range of model gradients or weights. Based on this insight, we propose a decreasing-trend quantization for the uplink and an increasing-trend quantization for the downlink, which aligns with the change of the model parameters during the training process. Experimental results show that, the proposed joint uplink and downlink adaptive quantization strategy can save up to 66.7% energy compared with the existing schemes.
Read more6/27/2024

0
Distributed Deep Reinforcement Learning Based Gradient Quantization for Federated Learning Enabled Vehicle Edge Computing
Cui Zhang, Wenjun Zhang, Qiong Wu, Pingyi Fan, Qiang Fan, Jiangzhou Wang, Khaled B. Letaief
Federated Learning (FL) can protect the privacy of the vehicles in vehicle edge computing (VEC) to a certain extent through sharing the gradients of vehicles' local models instead of local data. The gradients of vehicles' local models are usually large for the vehicular artificial intelligence (AI) applications, thus transmitting such large gradients would cause large per-round latency. Gradient quantization has been proposed as one effective approach to reduce the per-round latency in FL enabled VEC through compressing gradients and reducing the number of bits, i.e., the quantization level, to transmit gradients. The selection of quantization level and thresholds determines the quantization error, which further affects the model accuracy and training time. To do so, the total training time and quantization error (QE) become two key metrics for the FL enabled VEC. It is critical to jointly optimize the total training time and QE for the FL enabled VEC. However, the time-varying channel condition causes more challenges to solve this problem. In this paper, we propose a distributed deep reinforcement learning (DRL)-based quantization level allocation scheme to optimize the long-term reward in terms of the total training time and QE. Extensive simulations identify the optimal weighted factors between the total training time and QE, and demonstrate the feasibility and effectiveness of the proposed scheme.
Read more7/12/2024