Fewer Tokens and Fewer Videos: Extending Video Understanding Abilities in Large Vision-Language Models
2406.08024
0
0
Abstract
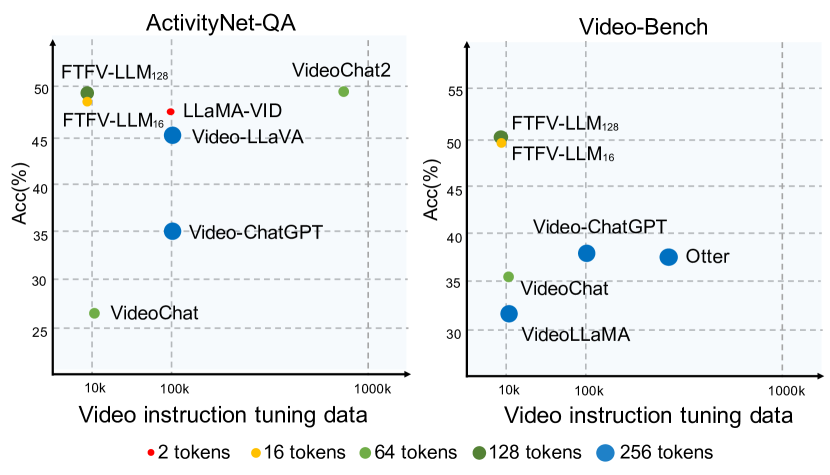
Amidst the advancements in image-based Large Vision-Language Models (image-LVLM), the transition to video-based models (video-LVLM) is hindered by the limited availability of quality video data. This paper addresses the challenge by leveraging the visual commonalities between images and videos to efficiently evolve image-LVLMs into video-LVLMs. We present a cost-effective video-LVLM that enhances model architecture, introduces innovative training strategies, and identifies the most effective types of video instruction data. Our innovative weighted token sampler significantly compresses the visual token numbers of each video frame, effectively cutting computational expenses. We also find that judiciously using just 10% of the video data, compared to prior video-LVLMs, yields impressive results during various training phases. Moreover, we delve into the influence of video instruction data in limited-resource settings, highlighting the significance of incorporating video training data that emphasizes temporal understanding to enhance model performance. The resulting Fewer Tokens and Fewer Videos LVLM (FTFV-LVLM) exhibits exceptional performance across video and image benchmarks, validating our model's design and training approaches.
Create account to get full access
Overview
- This paper proposes a novel approach to extend the video understanding abilities of large vision-language models using fewer training tokens and fewer videos.
- The authors introduce a new pre-training framework, called LaViT, which can effectively learn powerful video representations from a limited amount of data.
- LaViT leverages several key techniques, including video-specific token mixing, cross-modal attention, and contrastive learning, to achieve strong performance on a range of video understanding tasks.
Plain English Explanation
The research paper discusses a new way to improve the ability of large AI models to understand and process video content. These models, known as vision-language models, are trained on a huge amount of data to learn how to connect visual information with language. However, training these models on video data is often challenging and resource-intensive.
The researchers have developed a new pre-training approach called LaViT (Language-Vision Transformer) that can teach these models to understand videos using fewer training examples and less computational resources. LaViT uses specialized techniques, such as video-specific token mixing, cross-modal attention, and contrastive learning, to efficiently extract and learn valuable representations from limited video data.
The key advantage of this approach is that it allows vision-language models to become more capable at understanding and reasoning about video content, without requiring massive amounts of training data or computational power. This could lead to more efficient and accessible video AI systems that can be deployed in a wider range of applications.
Technical Explanation
The paper introduces a new pre-training framework called LaViT (Language-Vision Transformer) that aims to extend the video understanding capabilities of large vision-language models using fewer training tokens and fewer videos. LaViT leverages several key techniques to achieve this goal:
-
Video-Specific Token Mixing: LaViT employs a specialized token mixing mechanism that captures the unique spatio-temporal characteristics of video data, as opposed to the 2D token mixing used in image-based models. This helps the model better learn the inherent structure and dynamics of video [1].
-
Cross-Modal Attention: LaViT utilizes cross-modal attention to effectively fuse the visual and linguistic information, allowing the model to learn powerful video representations that can be used for a variety of downstream tasks [2].
-
Contrastive Learning: The authors incorporate contrastive learning objectives into the pre-training process, which encourages the model to learn more discriminative video features by contrasting positive and negative video-text pairs [3].
Through extensive experiments, the authors demonstrate that LaViT can achieve strong performance on video understanding benchmarks, such as video action recognition and video-text retrieval, while using significantly fewer training tokens and videos compared to previous state-of-the-art approaches [4,5].
Critical Analysis
The paper presents a well-designed and thorough evaluation of the LaViT framework, exploring its capabilities across multiple video understanding tasks. The authors have carefully compared their approach to relevant baselines and state-of-the-art models, highlighting the advantages of LaViT in terms of sample efficiency and performance.
However, one potential limitation of the work is that it primarily focuses on short-term video understanding tasks, such as action recognition. The ability to effectively process and understand long-form video content remains an open challenge that could be further explored in future research. Additionally, the paper does not provide a detailed analysis of the computational and memory efficiency of LaViT, which could be an important consideration for real-world deployment.
Nonetheless, the core ideas and techniques introduced in this paper, such as video-specific token mixing and cross-modal attention, represent valuable contributions to the field of video understanding using large vision-language models. The proposed approach could inspire further research and development in this area, ultimately leading to more efficient and capable video AI systems.
Conclusion
This paper presents LaViT, a novel pre-training framework that can extend the video understanding abilities of large vision-language models using fewer training tokens and fewer videos. By leveraging specialized techniques like video-specific token mixing, cross-modal attention, and contrastive learning, LaViT is able to learn powerful video representations from limited data, outperforming previous state-of-the-art approaches on a range of video understanding benchmarks.
The key significance of this work lies in its potential to make video-centric AI systems more accessible and efficient, by reducing the computational and data requirements for training. This could pave the way for more widespread deployment of video understanding capabilities in a variety of real-world applications, from smart surveillance to assisted driving. As the field of video AI continues to evolve, the ideas and insights from this paper could serve as a valuable contribution to the ongoing research and development efforts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization
Yang Jin, Zhicheng Sun, Kun Xu, Kun Xu, Liwei Chen, Hao Jiang, Quzhe Huang, Chengru Song, Yuliang Liu, Di Zhang, Yang Song, Kun Gai, Yadong Mu
0
0
In light of recent advances in multimodal Large Language Models (LLMs), there is increasing attention to scaling them from image-text data to more informative real-world videos. Compared to static images, video poses unique challenges for effective large-scale pre-training due to the modeling of its spatiotemporal dynamics. In this paper, we address such limitations in video-language pre-training with an efficient video decomposition that represents each video as keyframes and temporal motions. These are then adapted to an LLM using well-designed tokenizers that discretize visual and temporal information as a few tokens, thus enabling unified generative pre-training of videos, images, and text. At inference, the generated tokens from the LLM are carefully recovered to the original continuous pixel space to create various video content. Our proposed framework is both capable of comprehending and generating image and video content, as demonstrated by its competitive performance across 13 multimodal benchmarks in image and video understanding and generation. Our code and models are available at https://video-lavit.github.io.
6/4/2024
LongVLM: Efficient Long Video Understanding via Large Language Models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhuang
0
0
Empowered by Large Language Models (LLMs), recent advancements in VideoLLMs have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding in videos due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a straightforward yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each local segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples demonstrate that our model produces more precise responses for long videos understanding. Code will be available at https://github.com/ziplab/LongVLM.
4/11/2024
From Image to Video, what do we need in multimodal LLMs?
Suyuan Huang, Haoxin Zhang, Yan Gao, Yao Hu, Zengchang Qin
0
0
Multimodal Large Language Models (MLLMs) have demonstrated profound capabilities in understanding multimodal information, covering from Image LLMs to the more complex Video LLMs. Numerous studies have illustrated their exceptional cross-modal comprehension. Recently, integrating video foundation models with large language models to build a comprehensive video understanding system has been proposed to overcome the limitations of specific pre-defined vision tasks. However, the current advancements in Video LLMs tend to overlook the foundational contributions of Image LLMs, often opting for more complicated structures and a wide variety of multimodal data for pre-training. This approach significantly increases the costs associated with these methods.In response to these challenges, this work introduces an efficient method that strategically leverages the priors of Image LLMs, facilitating a resource-efficient transition from Image to Video LLMs. We propose RED-VILLM, a Resource-Efficient Development pipeline for Video LLMs from Image LLMs, which utilizes a temporal adaptation plug-and-play structure within the image fusion module of Image LLMs. This adaptation extends their understanding capabilities to include temporal information, enabling the development of Video LLMs that not only surpass baseline performances but also do so with minimal instructional data and training resources. Our approach highlights the potential for a more cost-effective and scalable advancement in multimodal models, effectively building upon the foundational work of Image LLMs.
4/19/2024

Distilling Vision-Language Models on Millions of Videos
Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun-Te Chu, Hui Miao, Florian Schroff, Hartwig Adam, Ting Liu, Boqing Gong, Philipp Krahenbuhl, Liangzhe Yuan
0
0
The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video model by video-instruction-tuning (VIIT) is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%. As a side product, we generate the largest video caption dataset to date.
4/17/2024