Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization
2402.03161
0
0
📊
Abstract
In light of recent advances in multimodal Large Language Models (LLMs), there is increasing attention to scaling them from image-text data to more informative real-world videos. Compared to static images, video poses unique challenges for effective large-scale pre-training due to the modeling of its spatiotemporal dynamics. In this paper, we address such limitations in video-language pre-training with an efficient video decomposition that represents each video as keyframes and temporal motions. These are then adapted to an LLM using well-designed tokenizers that discretize visual and temporal information as a few tokens, thus enabling unified generative pre-training of videos, images, and text. At inference, the generated tokens from the LLM are carefully recovered to the original continuous pixel space to create various video content. Our proposed framework is both capable of comprehending and generating image and video content, as demonstrated by its competitive performance across 13 multimodal benchmarks in image and video understanding and generation. Our code and models are available at https://video-lavit.github.io.
Create account to get full access
Overview
- This paper addresses the challenges of effectively pre-training large language models (LLMs) on video data, beyond just static images.
- The authors propose an efficient video decomposition approach that represents each video as a combination of keyframes and temporal motions.
- This allows the LLM to be pre-trained on a unified representation of video, images, and text, enabling the model to both comprehend and generate multimedia content.
- The authors demonstrate the model's competitive performance on a range of multimodal benchmarks in image and video understanding and generation.
Plain English Explanation
Large language models (LLMs) have made significant progress in understanding and generating text, images, and even audio. However, effectively training these models on video data poses unique challenges due to the complex spatiotemporal dynamics involved.
The authors of this paper propose a solution to this problem by representing each video as a combination of keyframes (important static images) and temporal motions (the dynamic changes over time). This efficient video decomposition allows the LLM to be pre-trained on a unified representation of video, images, and text.
During this pre-training process, the model learns to understand and generate various multimedia content, including images, videos, and text. At inference, the model can then generate new video content by carefully recovering the token-based representations back into continuous pixel space.
The authors demonstrate that their proposed framework outperforms other state-of-the-art models on a wide range of multimodal benchmarks, showcasing its ability to comprehend and generate both images and videos.
Technical Explanation
The key innovation in this paper is the efficient video decomposition approach used to represent each video as a combination of keyframes and temporal motions. This allows the authors to adapt the video data to an LLM using well-designed tokenizers that discretize the visual and temporal information into a few tokens.
The tokenized representations of the videos, images, and text are then used to pre-train the LLM in a unified manner, enabling the model to learn a shared understanding of these different modalities. During inference, the generated tokens from the LLM are carefully recovered to the original continuous pixel space to create new video content.
The authors evaluate their proposed framework on 13 multimodal benchmarks, covering both video and image understanding and generation tasks. The results demonstrate the model's strong performance, outperforming other state-of-the-art approaches in various video-language tasks.
Critical Analysis
The authors acknowledge that their approach is limited to modeling short-term temporal dynamics and may struggle with longer-form videos. Additionally, the video decomposition and token recovery processes could introduce artifacts or quality degradation in the generated videos.
While the paper presents promising results, further research is needed to address these limitations and explore ways to scale the model to handle more complex video content and longer sequences. Integrating other modalities, such as audio, could also enhance the model's understanding and generation capabilities.
Conclusion
This paper introduces an efficient approach to effectively pre-train large language models on video data, enabling them to comprehend and generate a wide range of multimedia content. The key innovation is the video decomposition method that represents each video as a combination of keyframes and temporal motions, which can be efficiently adapted to the LLM.
The demonstrated performance on various multimodal benchmarks suggests that this framework could be a significant step towards developing more capable and versatile large language models that can seamlessly handle images, videos, and text. Further research to address the identified limitations could lead to even more powerful and flexible multimedia-understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
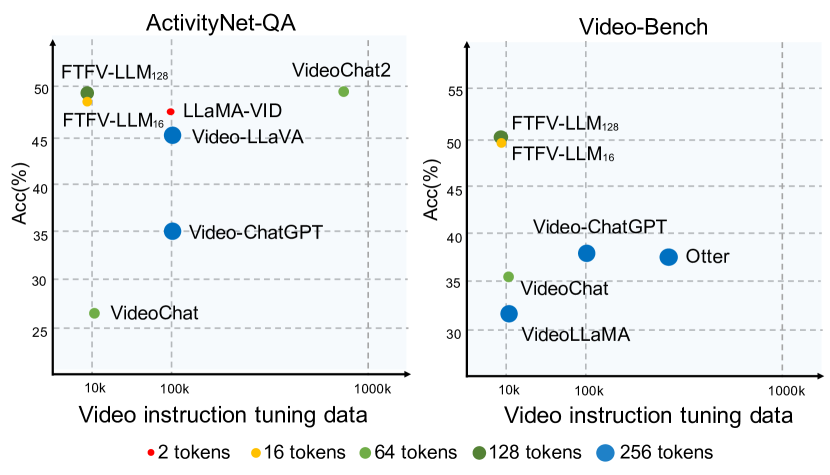
Fewer Tokens and Fewer Videos: Extending Video Understanding Abilities in Large Vision-Language Models
Shimin Chen, Yitian Yuan, Shaoxiang Chen, Zequn Jie, Lin Ma
0
0
Amidst the advancements in image-based Large Vision-Language Models (image-LVLM), the transition to video-based models (video-LVLM) is hindered by the limited availability of quality video data. This paper addresses the challenge by leveraging the visual commonalities between images and videos to efficiently evolve image-LVLMs into video-LVLMs. We present a cost-effective video-LVLM that enhances model architecture, introduces innovative training strategies, and identifies the most effective types of video instruction data. Our innovative weighted token sampler significantly compresses the visual token numbers of each video frame, effectively cutting computational expenses. We also find that judiciously using just 10% of the video data, compared to prior video-LVLMs, yields impressive results during various training phases. Moreover, we delve into the influence of video instruction data in limited-resource settings, highlighting the significance of incorporating video training data that emphasizes temporal understanding to enhance model performance. The resulting Fewer Tokens and Fewer Videos LVLM (FTFV-LVLM) exhibits exceptional performance across video and image benchmarks, validating our model's design and training approaches.
6/13/2024
From Image to Video, what do we need in multimodal LLMs?
Suyuan Huang, Haoxin Zhang, Yan Gao, Yao Hu, Zengchang Qin
0
0
Multimodal Large Language Models (MLLMs) have demonstrated profound capabilities in understanding multimodal information, covering from Image LLMs to the more complex Video LLMs. Numerous studies have illustrated their exceptional cross-modal comprehension. Recently, integrating video foundation models with large language models to build a comprehensive video understanding system has been proposed to overcome the limitations of specific pre-defined vision tasks. However, the current advancements in Video LLMs tend to overlook the foundational contributions of Image LLMs, often opting for more complicated structures and a wide variety of multimodal data for pre-training. This approach significantly increases the costs associated with these methods.In response to these challenges, this work introduces an efficient method that strategically leverages the priors of Image LLMs, facilitating a resource-efficient transition from Image to Video LLMs. We propose RED-VILLM, a Resource-Efficient Development pipeline for Video LLMs from Image LLMs, which utilizes a temporal adaptation plug-and-play structure within the image fusion module of Image LLMs. This adaptation extends their understanding capabilities to include temporal information, enabling the development of Video LLMs that not only surpass baseline performances but also do so with minimal instructional data and training resources. Our approach highlights the potential for a more cost-effective and scalable advancement in multimodal models, effectively building upon the foundational work of Image LLMs.
4/19/2024

VideoLLM-online: Online Video Large Language Model for Streaming Video
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, Mike Zheng Shou
0
0
Recent Large Language Models have been enhanced with vision capabilities, enabling them to comprehend images, videos, and interleaved vision-language content. However, the learning methods of these large multimodal models typically treat videos as predetermined clips, making them less effective and efficient at handling streaming video inputs. In this paper, we propose a novel Learning-In-Video-Stream (LIVE) framework, which enables temporally aligned, long-context, and real-time conversation within a continuous video stream. Our LIVE framework comprises comprehensive approaches to achieve video streaming dialogue, encompassing: (1) a training objective designed to perform language modeling for continuous streaming inputs, (2) a data generation scheme that converts offline temporal annotations into a streaming dialogue format, and (3) an optimized inference pipeline to speed up the model responses in real-world video streams. With our LIVE framework, we built VideoLLM-online model upon Llama-2/Llama-3 and demonstrate its significant advantages in processing streaming videos. For instance, on average, our model can support streaming dialogue in a 5-minute video clip at over 10 FPS on an A100 GPU. Moreover, it also showcases state-of-the-art performance on public offline video benchmarks, such as recognition, captioning, and forecasting. The code, model, data, and demo have been made available at https://showlab.github.io/videollm-online.
6/18/2024
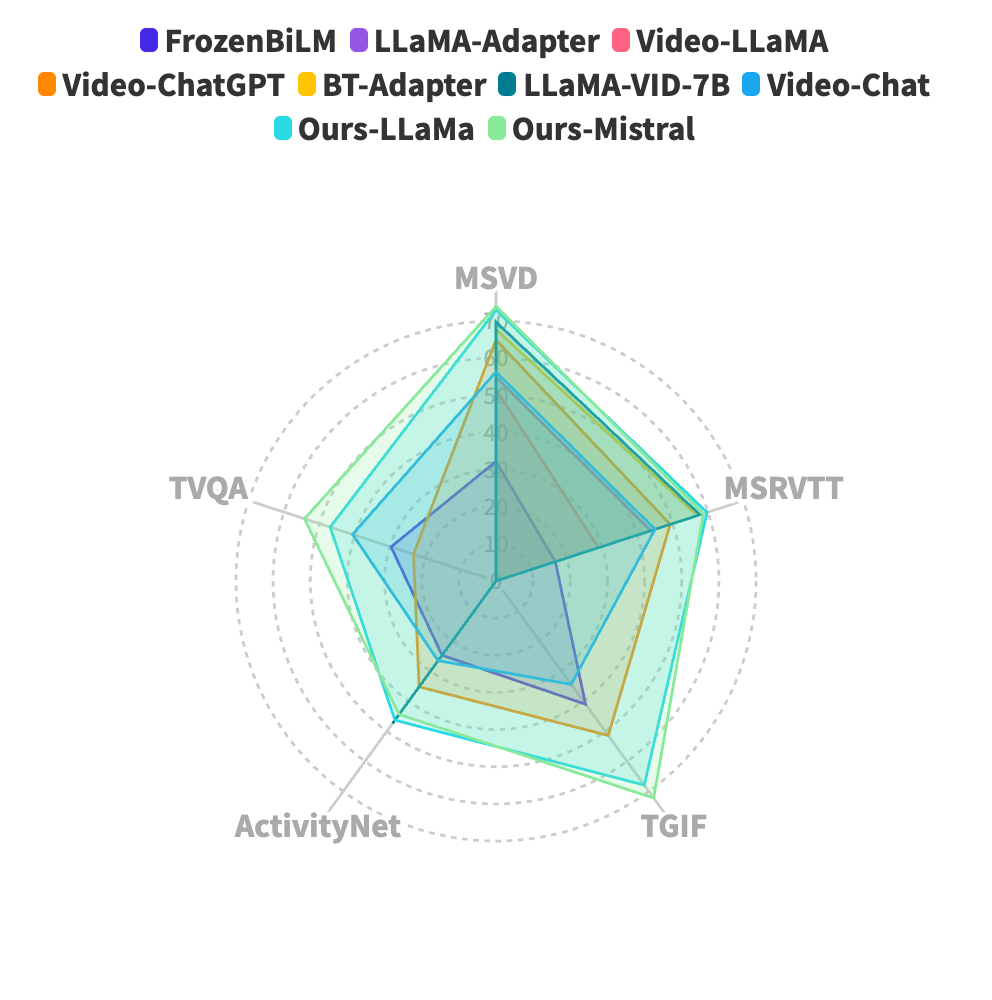
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
Kirolos Ataallah, Xiaoqian Shen, Eslam Abdelrahman, Essam Sleiman, Deyao Zhu, Jian Ding, Mohamed Elhoseiny
0
0
This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
4/5/2024