From Image to Video, what do we need in multimodal LLMs?
2404.11865
0
0
Abstract
Multimodal Large Language Models (MLLMs) have demonstrated profound capabilities in understanding multimodal information, covering from Image LLMs to the more complex Video LLMs. Numerous studies have illustrated their exceptional cross-modal comprehension. Recently, integrating video foundation models with large language models to build a comprehensive video understanding system has been proposed to overcome the limitations of specific pre-defined vision tasks. However, the current advancements in Video LLMs tend to overlook the foundational contributions of Image LLMs, often opting for more complicated structures and a wide variety of multimodal data for pre-training. This approach significantly increases the costs associated with these methods.In response to these challenges, this work introduces an efficient method that strategically leverages the priors of Image LLMs, facilitating a resource-efficient transition from Image to Video LLMs. We propose RED-VILLM, a Resource-Efficient Development pipeline for Video LLMs from Image LLMs, which utilizes a temporal adaptation plug-and-play structure within the image fusion module of Image LLMs. This adaptation extends their understanding capabilities to include temporal information, enabling the development of Video LLMs that not only surpass baseline performances but also do so with minimal instructional data and training resources. Our approach highlights the potential for a more cost-effective and scalable advancement in multimodal models, effectively building upon the foundational work of Image LLMs.
Get summaries of the top AI research delivered straight to your inbox:
From Image to Video, what do we need in multimodal LLMs?
Overview
- Explores the challenges and opportunities in developing multimodal large language models (LLMs) that can comprehend and generate both visual and textual content
- Discusses the need for resource-efficient approaches to expand LLM capabilities beyond text to include video understanding
- Highlights key research areas, such as cross-modal comprehension, to advance the field of multimodal LLMs
Plain English Explanation
Large language models (LLMs) have made remarkable progress in understanding and generating text, but to truly be "intelligent," they need to be able to comprehend and interact with the world in a more holistic way. This means going beyond just text and being able to understand and work with different types of media, like images and videos.
Modaverse: Efficiently Transforming Modalities in LLMs and LongVLM: Efficient Long Video Understanding via Large Language Models are just a couple of examples of research exploring how to expand LLM capabilities to include video understanding. The key idea is to find resource-efficient ways to enable LLMs to process and generate content across different modalities, like text, images, and video.
One important area of research is cross-modal comprehension, which looks at how LLMs can understand the relationships and connections between different types of media. For example, how can an LLM understand the context and meaning of a video clip based on the accompanying text, or vice versa?
By advancing multimodal LLM capabilities, we can unlock new possibilities for how these powerful models can be used to understand and interact with the world around us. This could have applications in areas like education, entertainment, and even scientific research.
Technical Explanation
The paper explores the challenges and opportunities in developing multimodal large language models (LLMs) that can comprehend and generate both visual and textual content.
One key area of focus is cross-modal comprehension, which looks at how LLMs can understand the relationships and connections between different types of media, such as text and video. This could involve understanding the context and meaning of a video clip based on the accompanying text, or vice versa.
The paper also discusses the need for resource-efficient approaches to expand LLM capabilities beyond text to include video understanding. Research like Modaverse: Efficiently Transforming Modalities in LLMs and LongVLM: Efficient Long Video Understanding via Large Language Models is exploring ways to enable LLMs to process and generate content across different modalities in a more efficient manner.
By advancing multimodal LLM capabilities, the goal is to unlock new possibilities for how these powerful models can be used to understand and interact with the world around us, with potential applications in areas like education, entertainment, and scientific research.
Critical Analysis
The paper highlights the important challenges and research directions in developing multimodal LLMs, but it also acknowledges the significant technical hurdles that need to be overcome.
One key limitation is the resource-intensive nature of expanding LLMs to handle multiple modalities, such as video. The paper discusses the need for more efficient approaches, but it does not provide a detailed solution. Further research is required to develop practical and scalable methods for integrating video and other media into LLMs.
Additionally, the paper focuses primarily on cross-modal comprehension, but it does not extensively explore other aspects of multimodal LLMs, such as generation or reasoning across modalities. These areas may also present unique challenges and require dedicated research.
Finally, the paper does not delve into potential ethical or social implications of multimodal LLMs, such as the risks of generating or manipulating video content. As these models become more capable, it will be important to consider these broader societal impacts.
Conclusion
The paper highlights the significant potential of multimodal LLMs to unlock new possibilities in how we understand and interact with the world around us. By expanding LLM capabilities beyond just text to include visual and other media, we can enable these powerful models to comprehend and generate content in more holistic and natural ways.
However, the development of such multimodal LLMs presents substantial technical challenges, particularly in terms of resource efficiency and cross-modal comprehension. Continued research and innovation in areas like Modaverse and LongVLM will be crucial to overcoming these hurdles and realizing the full potential of multimodal LLMs.
As the field progresses, it will also be important to consider the broader implications and potential risks of these advanced models, and to ensure that they are developed and deployed responsibly and ethically.
Related Papers

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
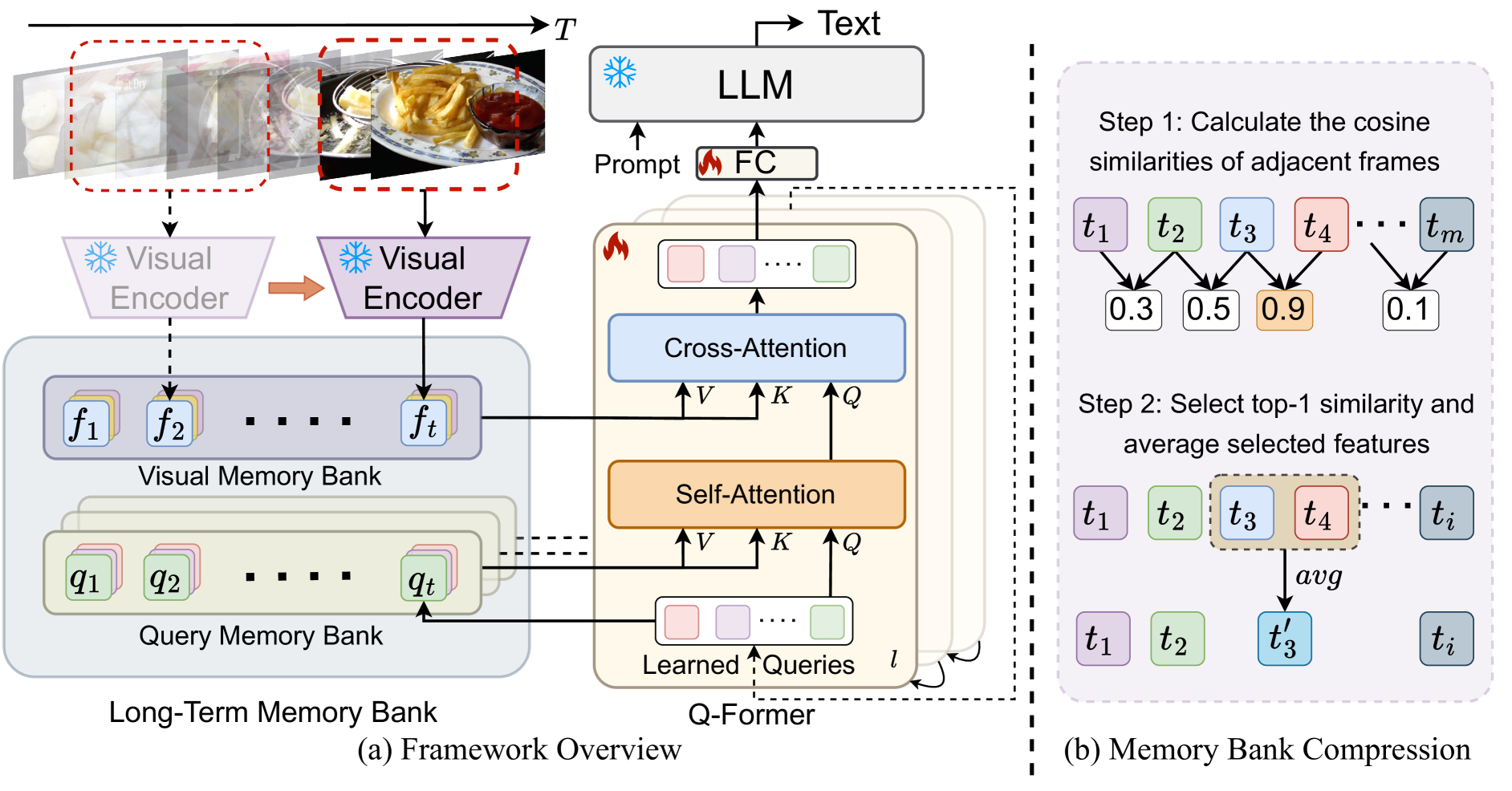
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, Ser-Nam Lim
0
0
With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
4/9/2024
🤔
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, Anton Belyi, Haotian Zhang, Karanjeet Singh, Doug Kang, Ankur Jain, Hongyu H`e, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Guoli Yin, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, Yinfei Yang
0
0
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
4/22/2024

Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, Saining Xie
0
0
Is vision good enough for language? Recent advancements in multimodal models primarily stem from the powerful reasoning abilities of large language models (LLMs). However, the visual component typically depends only on the instance-level contrastive language-image pre-training (CLIP). Our research reveals that the visual capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings. To understand the roots of these errors, we explore the gap between the visual embedding space of CLIP and vision-only self-supervised learning. We identify ''CLIP-blind pairs'' - images that CLIP perceives as similar despite their clear visual differences. With these pairs, we construct the Multimodal Visual Patterns (MMVP) benchmark. MMVP exposes areas where state-of-the-art systems, including GPT-4V, struggle with straightforward questions across nine basic visual patterns, often providing incorrect answers and hallucinated explanations. We further evaluate various CLIP-based vision-and-language models and found a notable correlation between visual patterns that challenge CLIP models and those problematic for multimodal LLMs. As an initial effort to address these issues, we propose a Mixture of Features (MoF) approach, demonstrating that integrating vision self-supervised learning features with MLLMs can significantly enhance their visual grounding capabilities. Together, our research suggests visual representation learning remains an open challenge, and accurate visual grounding is crucial for future successful multimodal systems.
4/26/2024