FewShotNeRF: Meta-Learning-based Novel View Synthesis for Rapid Scene-Specific Adaptation

0

Sign in to get full access
Overview
- FewShotNeRF is a meta-learning-based approach for rapid scene-specific adaptation of neural radiance fields (NeRF) models.
- It can generate novel views of a scene from just a few input images, without requiring extensive fine-tuning.
- The method combines a pre-trained NeRF model with a lightweight, scene-specific adaptation network to enable fast adaptation to new scenes.
Plain English Explanation
FewShotNeRF is a new technique that makes it easier to create 3D models of real-world scenes from just a handful of photos. Typically, creating these types of 3D models, called neural radiance fields (NeRFs), requires lots of training data and computational power. FewShotNeRF solves this by using a "pre-trained" NeRF model that has already learned general 3D modeling skills. When you give FewShotNeRF a few photos of a new scene, it can quickly adapt the pre-trained model to that specific scene, allowing it to generate novel views - new images of the scene from different angles - without needing to start from scratch. This makes NeRF technology more practical for real-world applications that may only have access to a limited number of photos.
Technical Explanation
FewShotNeRF builds on the neural radiance field (NeRF) approach for novel view synthesis. NeRF models the 3D structure of a scene by learning a continuous function that maps 3D coordinates to color and density. However, training a NeRF model from scratch requires a large number of input images, which can be impractical in many real-world scenarios.
To address this, FewShotNeRF uses a meta-learning approach. It starts with a pre-trained NeRF model that has learned general 3D modeling skills. When presented with a new scene, FewShotNeRF adds a lightweight, scene-specific adaptation network that can quickly fine-tune the pre-trained NeRF to the new scene using just a few input images. This allows FewShotNeRF to generate high-quality novel views of the scene without the need for extensive fine-tuning.
The key components of FewShotNeRF are:
- Pre-trained NeRF Model: A NeRF model that has been trained on a large and diverse dataset of 3D scenes, giving it general 3D modeling capabilities.
- Adaptation Network: A small neural network that can quickly adapt the pre-trained NeRF model to a new scene using just a few input images.
- Meta-Learning: The process of training the adaptation network to efficiently fine-tune the pre-trained NeRF for new scenes, leveraging insights from the diverse training data.
Through this combination of a pre-trained NeRF and a meta-learning-based adaptation network, FewShotNeRF can generate high-quality novel views of new scenes with just a handful of input images, significantly reducing the amount of data and computation required compared to training a NeRF from scratch.
Critical Analysis
The FewShotNeRF paper presents a promising approach for enabling rapid scene-specific adaptation of NeRF models, which could greatly expand the practical applicability of this technology. However, the paper also acknowledges some limitations and areas for future research:
- Scalability: While FewShotNeRF can adapt to new scenes quickly, the performance of the adaptation network may degrade as the complexity and diversity of the target scenes increases. Further research is needed to understand the scalability limits of this approach.
- Generalization: The paper focuses on evaluating FewShotNeRF on a specific dataset of indoor scenes. It's unclear how well the method would generalize to more diverse scene types, such as outdoor environments or dynamic scenes.
- Interpretability: As with many neural network-based approaches, the inner workings of the FewShotNeRF model are not fully interpretable. This can make it challenging to understand the specific mechanisms underlying the rapid adaptation capabilities.
Overall, FewShotNeRF represents an important step forward in making NeRF-based novel view synthesis more practical and accessible. Further research to address the limitations and explore the broader applicability of this approach could lead to significant advancements in 3D scene modeling and understanding.
Conclusion
FewShotNeRF introduces a meta-learning-based approach for rapidly adapting neural radiance field (NeRF) models to new scenes using just a few input images. By combining a pre-trained NeRF model with a lightweight, scene-specific adaptation network, FewShotNeRF can generate high-quality novel views of new scenes without the need for extensive fine-tuning.
This advance could have important implications for various applications that require 3D scene modeling, such as virtual and augmented reality, robotics, and autonomous driving. By reducing the data and computational requirements for NeRF-based novel view synthesis, FewShotNeRF brings this powerful 3D modeling technique closer to real-world practicality.
While the paper presents promising results, it also highlights areas for future research, such as exploring the scalability and generalization of the approach to more diverse scene types. Continued advancements in this direction could further expand the capabilities and impact of NeRF-based 3D scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FewShotNeRF: Meta-Learning-based Novel View Synthesis for Rapid Scene-Specific Adaptation
Piraveen Sivakumar, Paul Janson, Jathushan Rajasegaran, Thanuja Ambegoda
In this paper, we address the challenge of generating novel views of real-world objects with limited multi-view images through our proposed approach, FewShotNeRF. Our method utilizes meta-learning to acquire optimal initialization, facilitating rapid adaptation of a Neural Radiance Field (NeRF) to specific scenes. The focus of our meta-learning process is on capturing shared geometry and textures within a category, embedded in the weight initialization. This approach expedites the learning process of NeRFs and leverages recent advancements in positional encodings to reduce the time required for fitting a NeRF to a scene, thereby accelerating the inner loop optimization of meta-learning. Notably, our method enables meta-learning on a large number of 3D scenes to establish a robust 3D prior for various categories. Through extensive evaluations on the Common Objects in 3D open source dataset, we empirically demonstrate the efficacy and potential of meta-learning in generating high-quality novel views of objects.
Read more8/12/2024

0
Knowledge NeRF: Few-shot Novel View Synthesis for Dynamic Articulated Objects
Wenxiao Cai, Xinyue Lei, Xinyu He, Junming Leo Chen, Yangang Wang
We present Knowledge NeRF to synthesize novel views for dynamic scenes. Reconstructing dynamic 3D scenes from few sparse views and rendering them from arbitrary perspectives is a challenging problem with applications in various domains. Previous dynamic NeRF methods learn the deformation of articulated objects from monocular videos. However, qualities of their reconstructed scenes are limited. To clearly reconstruct dynamic scenes, we propose a new framework by considering two frames at a time.We pretrain a NeRF model for an articulated object.When articulated objects moves, Knowledge NeRF learns to generate novel views at the new state by incorporating past knowledge in the pretrained NeRF model with minimal observations in the present state. We propose a projection module to adapt NeRF for dynamic scenes, learning the correspondence between pretrained knowledge base and current states. Experimental results demonstrate the effectiveness of our method in reconstructing dynamic 3D scenes with 5 input images in one state. Knowledge NeRF is a new pipeline and promising solution for novel view synthesis in dynamic articulated objects. The data and implementation are publicly available at https://github.com/RussRobin/Knowledge_NeRF.
Read more4/9/2024
🧠
0
Novel View Synthesis with Neural Radiance Fields for Industrial Robot Applications
Markus Hillemann, Robert Langendorfer, Max Heiken, Max Mehltretter, Andreas Schenk, Martin Weinmann, Stefan Hinz, Christian Heipke, Markus Ulrich
Neural Radiance Fields (NeRFs) have become a rapidly growing research field with the potential to revolutionize typical photogrammetric workflows, such as those used for 3D scene reconstruction. As input, NeRFs require multi-view images with corresponding camera poses as well as the interior orientation. In the typical NeRF workflow, the camera poses and the interior orientation are estimated in advance with Structure from Motion (SfM). But the quality of the resulting novel views, which depends on different parameters such as the number and distribution of available images, as well as the accuracy of the related camera poses and interior orientation, is difficult to predict. In addition, SfM is a time-consuming pre-processing step, and its quality strongly depends on the image content. Furthermore, the undefined scaling factor of SfM hinders subsequent steps in which metric information is required. In this paper, we evaluate the potential of NeRFs for industrial robot applications. We propose an alternative to SfM pre-processing: we capture the input images with a calibrated camera that is attached to the end effector of an industrial robot and determine accurate camera poses with metric scale based on the robot kinematics. We then investigate the quality of the novel views by comparing them to ground truth, and by computing an internal quality measure based on ensemble methods. For evaluation purposes, we acquire multiple datasets that pose challenges for reconstruction typical of industrial applications, like reflective objects, poor texture, and fine structures. We show that the robot-based pose determination reaches similar accuracy as SfM in non-demanding cases, while having clear advantages in more challenging scenarios. Finally, we present first results of applying the ensemble method to estimate the quality of the synthetic novel view in the absence of a ground truth.
Read more5/8/2024
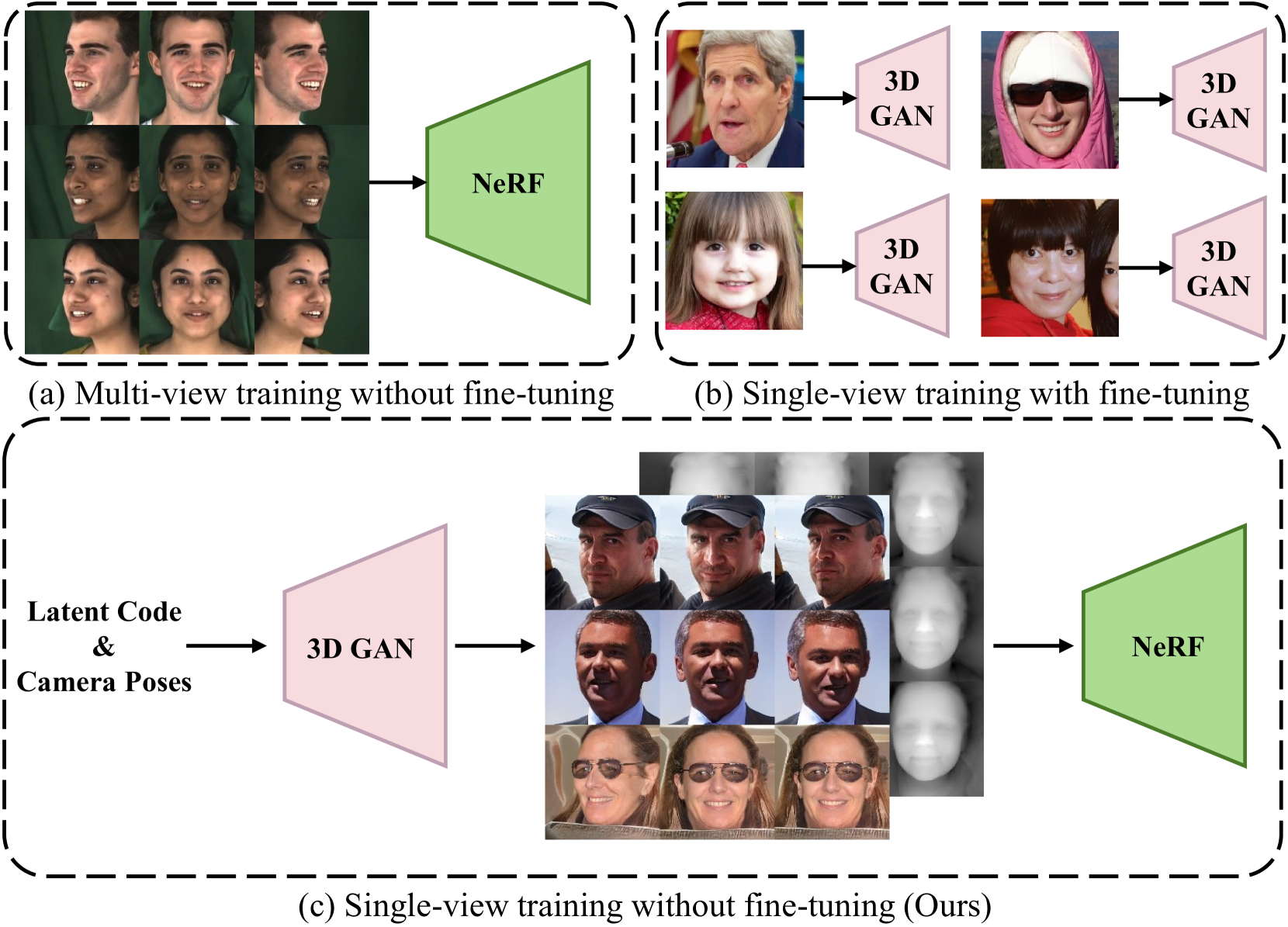
0
G-NeRF: Geometry-enhanced Novel View Synthesis from Single-View Images
Zixiong Huang, Qi Chen, Libo Sun, Yifan Yang, Naizhou Wang, Mingkui Tan, Qi Wu
Novel view synthesis aims to generate new view images of a given view image collection. Recent attempts address this problem relying on 3D geometry priors (e.g., shapes, sizes, and positions) learned from multi-view images. However, such methods encounter the following limitations: 1) they require a set of multi-view images as training data for a specific scene (e.g., face, car or chair), which is often unavailable in many real-world scenarios; 2) they fail to extract the geometry priors from single-view images due to the lack of multi-view supervision. In this paper, we propose a Geometry-enhanced NeRF (G-NeRF), which seeks to enhance the geometry priors by a geometry-guided multi-view synthesis approach, followed by a depth-aware training. In the synthesis process, inspired that existing 3D GAN models can unconditionally synthesize high-fidelity multi-view images, we seek to adopt off-the-shelf 3D GAN models, such as EG3D, as a free source to provide geometry priors through synthesizing multi-view data. Simultaneously, to further improve the geometry quality of the synthetic data, we introduce a truncation method to effectively sample latent codes within 3D GAN models. To tackle the absence of multi-view supervision for single-view images, we design the depth-aware training approach, incorporating a depth-aware discriminator to guide geometry priors through depth maps. Experiments demonstrate the effectiveness of our method in terms of both qualitative and quantitative results.
Read more4/12/2024