Knowledge NeRF: Few-shot Novel View Synthesis for Dynamic Articulated Objects
2404.00674
0
0

Abstract
We present Knowledge NeRF to synthesize novel views for dynamic scenes. Reconstructing dynamic 3D scenes from few sparse views and rendering them from arbitrary perspectives is a challenging problem with applications in various domains. Previous dynamic NeRF methods learn the deformation of articulated objects from monocular videos. However, qualities of their reconstructed scenes are limited. To clearly reconstruct dynamic scenes, we propose a new framework by considering two frames at a time.We pretrain a NeRF model for an articulated object.When articulated objects moves, Knowledge NeRF learns to generate novel views at the new state by incorporating past knowledge in the pretrained NeRF model with minimal observations in the present state. We propose a projection module to adapt NeRF for dynamic scenes, learning the correspondence between pretrained knowledge base and current states. Experimental results demonstrate the effectiveness of our method in reconstructing dynamic 3D scenes with 5 input images in one state. Knowledge NeRF is a new pipeline and promising solution for novel view synthesis in dynamic articulated objects. The data and implementation are publicly available at https://github.com/RussRobin/Knowledge_NeRF.
Create account to get full access
Overview
- This paper presents "Knowledge NeRF," a novel approach for few-shot novel view synthesis of dynamic articulated objects.
- The key ideas are to leverage prior knowledge about object structure and dynamics to enable fast and accurate novel view synthesis from sparse input views.
- The method integrates this prior knowledge with a neural radiance field (NeRF) model to achieve high-quality novel view synthesis with fewer input views than traditional NeRF approaches.
Plain English Explanation
"Knowledge NeRF" is a new technique that can create realistic 3D images of complex, moving objects from just a few example views. Traditional methods for this task, called "neural radiance fields" (NeRFs), often require dozens or hundreds of input views to work well. In contrast, Knowledge NeRF can produce high-quality novel views of articulated objects like robots or animated characters using only a handful of example images.
The key is that Knowledge NeRF incorporates prior knowledge about the structure and motion of the object. For example, it might know that a robot's arm can only bend at certain joints, or that a character's limbs move in coordinated ways. This additional knowledge helps the model fill in the gaps and generate accurate novel views from sparse input data. Link to NVINS: Robust Visual-Inertial Navigation with Fused NeRF
The result is a more efficient and effective approach to novel view synthesis for dynamic 3D scenes, with potential applications in areas like AR/VR, robotics, and digital content creation. Link to Unifying Correspondence and Pose with NeRF for Pose-Free Novel View Synthesis
Technical Explanation
The core idea of Knowledge NeRF is to integrate prior knowledge about an object's structure and dynamics into a NeRF model to enable few-shot novel view synthesis. The authors leverage this prior knowledge in two key ways:
-
Structured NeRF Encoding: The model encodes the object's 3D structure and articulation using a set of learnable "structure codes." These codes describe the object's kinematic skeleton and how different parts move relative to each other.
-
Dynamic NeRF Rendering: The model uses the structure codes to dynamically deform and update the NeRF representation as the object moves, allowing it to generate accurate novel views from sparse input data. Link to DateNeRF: Depth-Aware Text-Based Editing of Neural Radiance Fields
The authors evaluate Knowledge NeRF on a range of articulated object datasets, demonstrating significant improvements in novel view synthesis quality and efficiency compared to state-of-the-art NeRF baselines. Link to Uncertainty-Aware Active Learning for NeRF-based Object Detection
Critical Analysis
The Knowledge NeRF approach represents an important step forward in enabling effective novel view synthesis for dynamic 3D scenes. By incorporating prior knowledge about object structure and motion, the model can produce high-quality results from much sparser input data than traditional NeRF methods.
However, the paper does not address some potential limitations of the approach. For example, the reliance on detailed prior knowledge about the object's kinematics may limit the technique's applicability to more complex or less well-understood objects. Additionally, the authors do not explore the generalization capabilities of the model - it's unclear how well Knowledge NeRF would perform on novel object instances or classes beyond those seen during training. Link to CodecNeRF: Toward Fast Encoding and Decoding of Compact Neural Radiance Fields
Further research is needed to address these types of challenges and expand the capabilities of knowledge-driven approaches to neural rendering. Nonetheless, this work represents an important contribution to the field of 3D scene understanding and generation. Link to Unifying Correspondence and Pose with NeRF for Pose-Free Novel View Synthesis
Conclusion
The Knowledge NeRF paper introduces a novel approach to few-shot novel view synthesis for dynamic articulated objects. By integrating prior knowledge about object structure and motion, the model can generate high-quality novel views from sparse input data, overcoming the limitations of traditional NeRF techniques.
This work has significant implications for a range of applications, from augmented reality and robotics to digital content creation. By enabling more efficient and accurate 3D scene generation, Knowledge NeRF could help unlock new opportunities for interactive and immersive experiences. Further research in this area has the potential to push the boundaries of what's possible in neural rendering and 3D scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Sync-NeRF: Generalizing Dynamic NeRFs to Unsynchronized Videos
Seoha Kim, Jeongmin Bae, Youngsik Yun, Hahyun Lee, Gun Bang, Youngjung Uh
0
0
Recent advancements in 4D scene reconstruction using neural radiance fields (NeRF) have demonstrated the ability to represent dynamic scenes from multi-view videos. However, they fail to reconstruct the dynamic scenes and struggle to fit even the training views in unsynchronized settings. It happens because they employ a single latent embedding for a frame while the multi-view images at the same frame were actually captured at different moments. To address this limitation, we introduce time offsets for individual unsynchronized videos and jointly optimize the offsets with NeRF. By design, our method is applicable for various baselines and improves them with large margins. Furthermore, finding the offsets naturally works as synchronizing the videos without manual effort. Experiments are conducted on the common Plenoptic Video Dataset and a newly built Unsynchronized Dynamic Blender Dataset to verify the performance of our method. Project page: https://seoha-kim.github.io/sync-nerf
5/22/2024

Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-aware Spatio-Temporal Sampling
Xinhang Liu, Yu-Wing Tai, Chi-Keung Tang, Pedro Miraldo, Suhas Lohit, Moitreya Chatterjee
0
0
Extensions of Neural Radiance Fields (NeRFs) to model dynamic scenes have enabled their near photo-realistic, free-viewpoint rendering. Although these methods have shown some potential in creating immersive experiences, two drawbacks limit their ubiquity: (i) a significant reduction in reconstruction quality when the computing budget is limited, and (ii) a lack of semantic understanding of the underlying scenes. To address these issues, we introduce Gear-NeRF, which leverages semantic information from powerful image segmentation models. Our approach presents a principled way for learning a spatio-temporal (4D) semantic embedding, based on which we introduce the concept of gears to allow for stratified modeling of dynamic regions of the scene based on the extent of their motion. Such differentiation allows us to adjust the spatio-temporal sampling resolution for each region in proportion to its motion scale, achieving more photo-realistic dynamic novel view synthesis. At the same time, almost for free, our approach enables free-viewpoint tracking of objects of interest - a functionality not yet achieved by existing NeRF-based methods. Empirical studies validate the effectiveness of our method, where we achieve state-of-the-art rendering and tracking performance on multiple challenging datasets.
6/7/2024
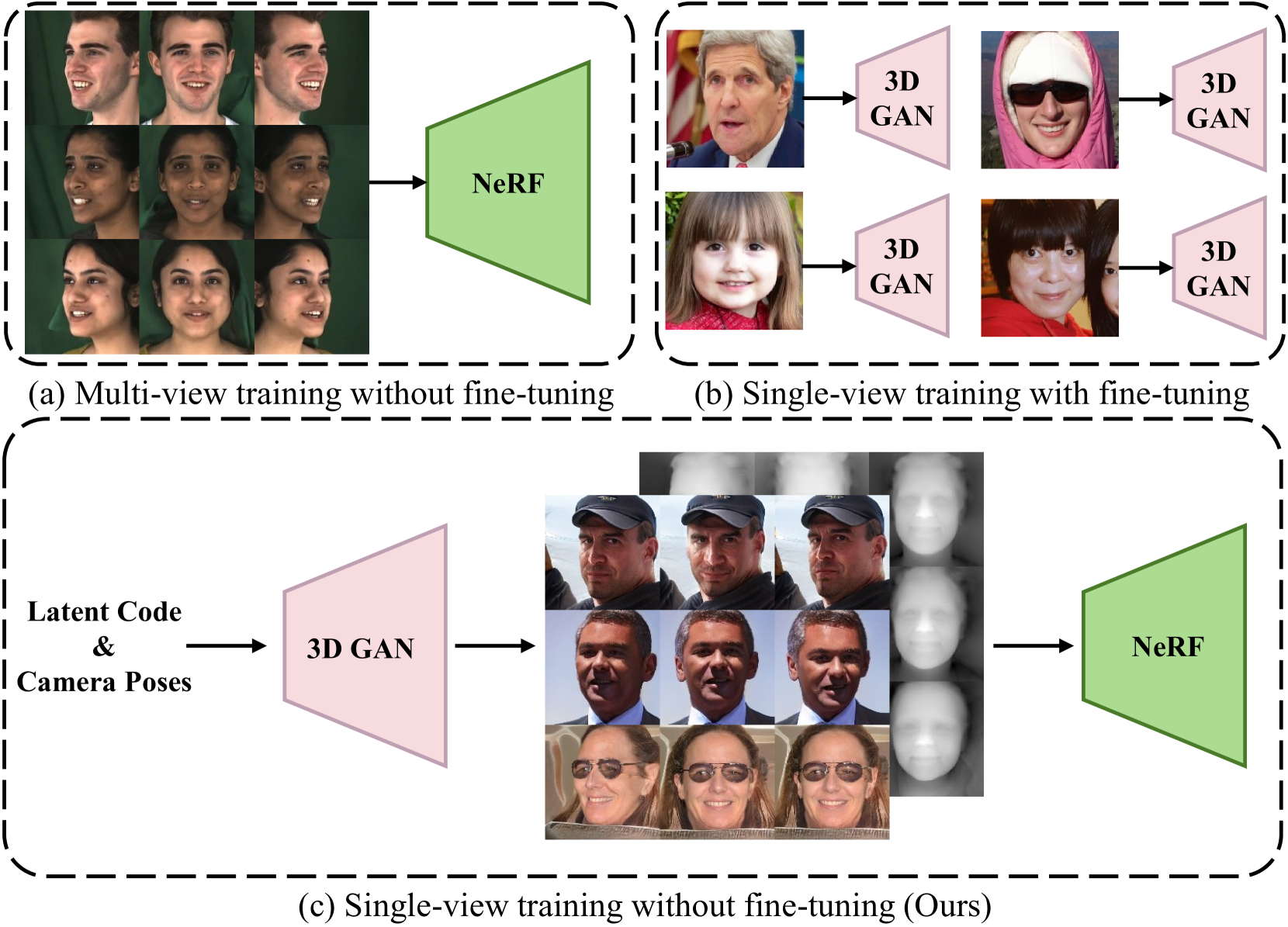
G-NeRF: Geometry-enhanced Novel View Synthesis from Single-View Images
Zixiong Huang, Qi Chen, Libo Sun, Yifan Yang, Naizhou Wang, Mingkui Tan, Qi Wu
0
0
Novel view synthesis aims to generate new view images of a given view image collection. Recent attempts address this problem relying on 3D geometry priors (e.g., shapes, sizes, and positions) learned from multi-view images. However, such methods encounter the following limitations: 1) they require a set of multi-view images as training data for a specific scene (e.g., face, car or chair), which is often unavailable in many real-world scenarios; 2) they fail to extract the geometry priors from single-view images due to the lack of multi-view supervision. In this paper, we propose a Geometry-enhanced NeRF (G-NeRF), which seeks to enhance the geometry priors by a geometry-guided multi-view synthesis approach, followed by a depth-aware training. In the synthesis process, inspired that existing 3D GAN models can unconditionally synthesize high-fidelity multi-view images, we seek to adopt off-the-shelf 3D GAN models, such as EG3D, as a free source to provide geometry priors through synthesizing multi-view data. Simultaneously, to further improve the geometry quality of the synthetic data, we introduce a truncation method to effectively sample latent codes within 3D GAN models. To tackle the absence of multi-view supervision for single-view images, we design the depth-aware training approach, incorporating a depth-aware discriminator to guide geometry priors through depth maps. Experiments demonstrate the effectiveness of our method in terms of both qualitative and quantitative results.
4/12/2024

NeRF-Feat: 6D Object Pose Estimation using Feature Rendering
Shishir Reddy Vutukur, Heike Brock, Benjamin Busam, Tolga Birdal, Andreas Hutter, Slobodan Ilic
0
0
Object Pose Estimation is a crucial component in robotic grasping and augmented reality. Learning based approaches typically require training data from a highly accurate CAD model or labeled training data acquired using a complex setup. We address this by learning to estimate pose from weakly labeled data without a known CAD model. We propose to use a NeRF to learn object shape implicitly which is later used to learn view-invariant features in conjunction with CNN using a contrastive loss. While NeRF helps in learning features that are view-consistent, CNN ensures that the learned features respect symmetry. During inference, CNN is used to predict view-invariant features which can be used to establish correspondences with the implicit 3d model in NeRF. The correspondences are then used to estimate the pose in the reference frame of NeRF. Our approach can also handle symmetric objects unlike other approaches using a similar training setup. Specifically, we learn viewpoint invariant, discriminative features using NeRF which are later used for pose estimation. We evaluated our approach on LM, LM-Occlusion, and T-Less dataset and achieved benchmark accuracy despite using weakly labeled data.
6/21/2024