MAFA: Managing False Negatives for Vision-Language Pre-training
2312.06112
0
0
👀
Abstract
We consider a critical issue of false negatives in Vision-Language Pre-training (VLP), a challenge that arises from the inherent many-to-many correspondence of image-text pairs in large-scale web-crawled datasets. The presence of false negatives can impede achieving optimal performance and even lead to a significant performance drop. To address this challenge, we propose MAFA (MAnaging FAlse negatives), which consists of two pivotal components building upon the recently developed GRouped mIni-baTch sampling (GRIT) strategy: 1) an efficient connection mining process that identifies and converts false negatives into positives, and 2) label smoothing for the image-text contrastive (ITC) loss. Our comprehensive experiments verify the effectiveness of MAFA across multiple downstream tasks, emphasizing the crucial role of addressing false negatives in VLP, potentially even surpassing the importance of addressing false positives. In addition, the compatibility of MAFA with the recent BLIP-family model is also demonstrated. Code is available at https://github.com/jaeseokbyun/MAFA.
Create account to get full access
Overview
- This paper proposes a method called COSMO (Converting and Smoothing False Negatives for Vision-Language Pre-training) to improve the performance of vision-language pre-training models.
- The key idea is to address the problem of false negatives during pre-training, where visually similar images are incorrectly labeled as negatives.
- COSMO converts these false negatives into positive pairs and smooths the training signal, leading to better model performance on downstream tasks.
Plain English Explanation
Vision-language pre-training models, such as VECAF and FineMATCH, aim to learn robust representations by jointly training on image and text data. However, these models can sometimes struggle with false negatives during pre-training - cases where visually similar images are incorrectly labeled as negatives, making it harder for the model to learn effectively.
The COSMO method proposed in this paper aims to address this issue. It works by first identifying these false negative pairs and then converting them into positive pairs, which means the model will learn to associate these similar images together. Additionally, COSMO smooths the training signal, which helps the model learn more stable and generalizable representations.
By addressing the false negative problem, COSMO can lead to significant performance improvements on downstream tasks, such as image-text retrieval and visual question answering. This is an important contribution, as it helps make vision-language models more robust and effective, with potential applications in areas like multimodal AI systems and contrastive pre-training.
Technical Explanation
The key technical contributions of this paper are:
-
False Negative Identification: The authors propose a method to automatically identify false negative pairs during pre-training. This involves using visual similarity metrics to find visually similar image pairs that are incorrectly labeled as negatives.
-
False Negative Conversion: Once identified, these false negative pairs are converted into positive pairs, meaning the model will learn to associate these similar images together during pre-training.
-
Training Signal Smoothing: In addition to the false negative conversion, the authors also smooth the training signal to make the model more robust and less sensitive to outliers or noisy data.
The authors evaluate COSMO on several benchmark vision-language tasks, including image-text retrieval and visual question answering. They show that COSMO can lead to significant performance improvements compared to standard pre-training approaches, particularly on datasets with more visual ambiguity or fine-grained distinctions.
Critical Analysis
One potential limitation of this work is that the false negative identification relies on visual similarity metrics, which may not always be accurate or reliable. There could be cases where visually similar images are actually semantically distinct, and the model should not learn to associate them. The authors acknowledge this issue and suggest that more sophisticated techniques for false negative identification could be explored in future work.
Additionally, the training signal smoothing approach used in COSMO may have some tradeoffs. While it can help the model become more robust, it could also potentially lead to a loss of fine-grained discrimination ability. The authors do not provide a comprehensive analysis of this potential tradeoff, which could be an area for further investigation.
Overall, the COSMO method represents a valuable contribution to the field of vision-language pre-training, but there are still opportunities to refine and build upon this work to address its potential limitations.
Conclusion
The COSMO method proposed in this paper is a significant advancement in vision-language pre-training. By addressing the problem of false negatives and smoothing the training signal, COSMO can lead to substantial performance improvements on a variety of downstream tasks. This work has important implications for the development of more robust and effective multimodal AI systems, with potential applications in areas like image-text retrieval, visual question answering, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
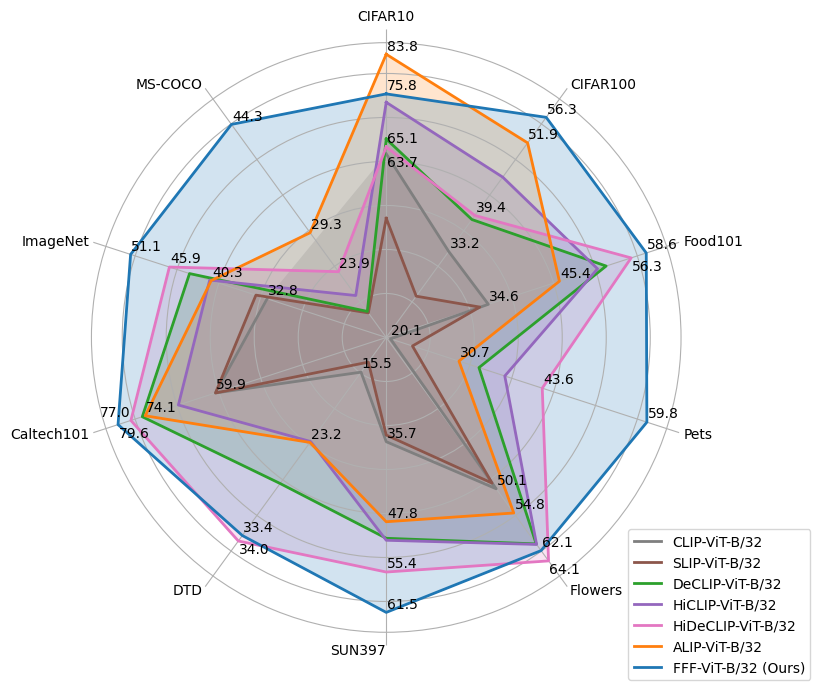
FFF: Fixing Flawed Foundations in contrastive pre-training results in very strong Vision-Language models
Adrian Bulat, Yassine Ouali, Georgios Tzimiropoulos
0
0
Despite noise and caption quality having been acknowledged as important factors impacting vision-language contrastive pre-training, in this paper, we show that the full potential of improving the training process by addressing such issues is yet to be realized. Specifically, we firstly study and analyze two issues affecting training: incorrect assignment of negative pairs, and low caption quality and diversity. Then, we devise effective solutions for addressing both problems, which essentially require training with multiple true positive pairs. Finally, we propose training with sigmoid loss to address such a requirement. We show very large gains over the current state-of-the-art for both image recognition ($sim +6%$ on average over 11 datasets) and image retrieval ($sim +19%$ on Flickr30k and $sim +15%$ on MSCOCO).
5/17/2024
🏋️
VeCAF: Vision-language Collaborative Active Finetuning with Training Objective Awareness
Rongyu Zhang, Zefan Cai, Huanrui Yang, Zidong Liu, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, Baobao Chang, Yuan Du, Li Du, Shanghang Zhang
0
0
Finetuning a pretrained vision model (PVM) is a common technique for learning downstream vision tasks. However, the conventional finetuning process with randomly sampled data points results in diminished training efficiency. To address this drawback, we propose a novel approach, Vision-language Collaborative Active Finetuning (VeCAF). With the emerging availability of labels and natural language annotations of images through web-scale crawling or controlled generation, VeCAF makes use of these information to perform parametric data selection for PVM finetuning. VeCAF incorporates the finetuning objective to select significant data points that effectively guide the PVM towards faster convergence to meet the performance goal. This process is assisted by the inherent semantic richness of the text embedding space which we use to augment image features. Furthermore, the flexibility of text-domain augmentation allows VeCAF to handle out-of-distribution scenarios without external data. Extensive experiments show the leading performance and high computational efficiency of VeCAF that is superior to baselines in both in-distribution and out-of-distribution image classification tasks. On ImageNet, VeCAF uses up to 3.3x less training batches to reach the target performance compared to full finetuning, and achieves an accuracy improvement of 2.7% over the state-of-the-art active finetuning method with the same number of batches.
4/16/2024
🛸
Connecting the Dots: Collaborative Fine-tuning for Black-Box Vision-Language Models
Zhengbo Wang, Jian Liang, Ran He, Zilei Wang, Tieniu Tan
0
0
With the emergence of pretrained vision-language models (VLMs), considerable efforts have been devoted to fine-tuning them for downstream tasks. Despite the progress made in designing efficient fine-tuning methods, such methods require access to the model's parameters, which can be challenging as model owners often opt to provide their models as a black box to safeguard model ownership. This paper proposes a textbf{C}ollabotextbf{ra}tive textbf{F}ine-textbf{T}uning (textbf{CraFT}) approach for fine-tuning black-box VLMs to downstream tasks, where one only has access to the input prompts and the output predictions of the model. CraFT comprises two modules, a prompt generation module for learning text prompts and a prediction refinement module for enhancing output predictions in residual style. Additionally, we introduce an auxiliary prediction-consistent loss to promote consistent optimization across these modules. These modules are optimized by a novel collaborative training algorithm. Extensive experiments on few-shot classification over 15 datasets demonstrate the superiority of CraFT. The results show that CraFT achieves a decent gain of about 12% with 16-shot datasets and only 8,000 queries. Moreover, CraFT trains faster and uses only about 1/80 of the memory footprint for deployment, while sacrificing only 1.62% compared to the white-box method. Our code is publicly available at https://github.com/mrflogs/CraFT .
6/4/2024
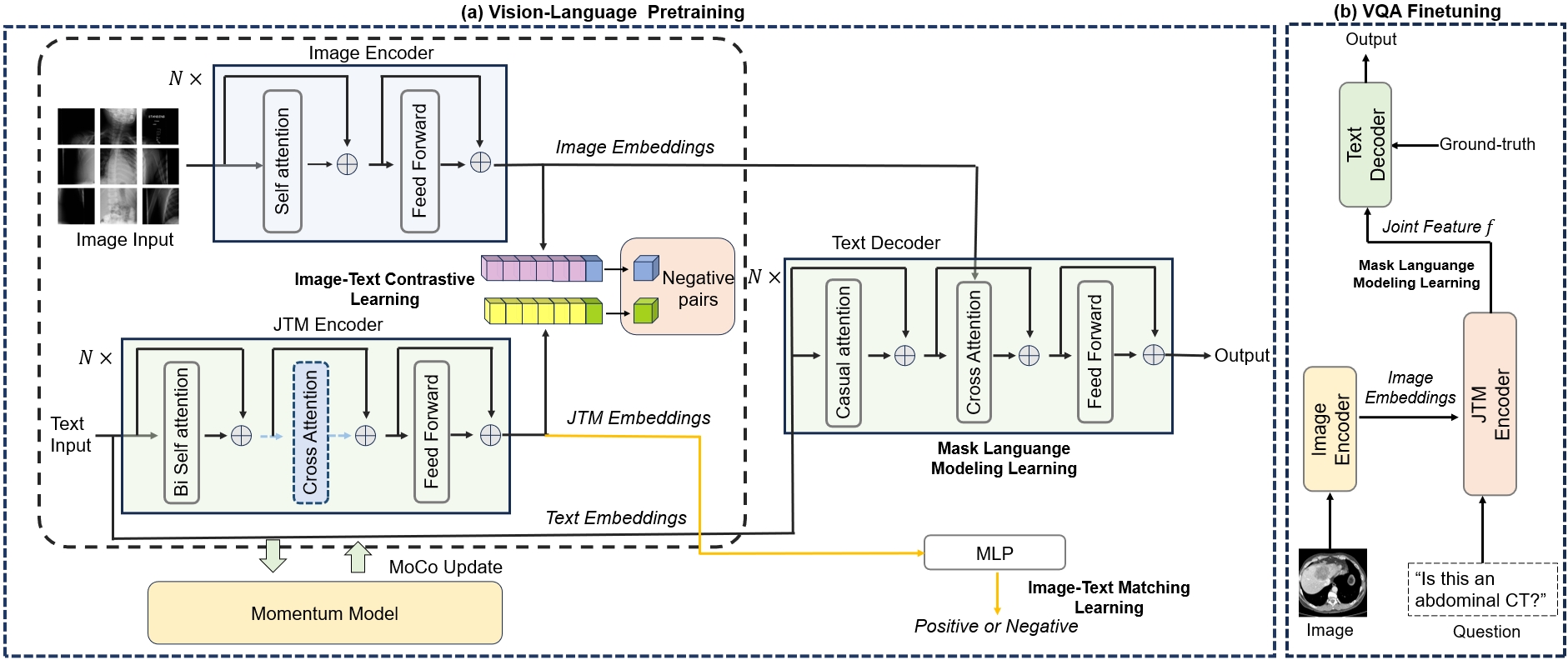
MISS: A Generative Pretraining and Finetuning Approach for Med-VQA
Jiawei Chen, Dingkang Yang, Yue Jiang, Yuxuan Lei, Lihua Zhang
0
0
Medical visual question answering (VQA) is a challenging multimodal task, where Vision-Language Pre-training (VLP) models can effectively improve the generalization performance. However, most methods in the medical field treat VQA as an answer classification task which is difficult to transfer to practical application scenarios. Additionally, due to the privacy of medical images and the expensive annotation process, large-scale medical image-text pairs datasets for pretraining are severely lacking. In this paper, we propose a large-scale MultI-task Self-Supervised learning based framework (MISS) for medical VQA tasks. Unlike existing methods, we treat medical VQA as a generative task. We unify the text encoder and multimodal encoder and align image-text features through multi-task learning. Furthermore, we propose a Transfer-and-Caption method that extends the feature space of single-modal image datasets using Large Language Models (LLMs), enabling those traditional medical vision field task data to be applied to VLP. Experiments show that our method achieves excellent results with fewer multimodal datasets and demonstrates the advantages of generative VQA models.
6/21/2024