LASER: Learning by Aligning Self-supervised Representations of Speech for Improving Content-related Tasks
2406.09153
0
0

Abstract
Self-supervised learning (SSL)-based speech models are extensively used for full-stack speech processing. However, it has been observed that improving SSL-based speech representations using unlabeled speech for content-related tasks is challenging and computationally expensive. Recent attempts have been made to address this issue with cost-effective self-supervised fine-tuning (SSFT) approaches. Continuing in this direction, a cost-effective SSFT method named LASER: Learning by Aligning Self-supervised Representations is presented. LASER is based on the soft-DTW alignment loss with temporal regularisation term. Experiments are conducted with HuBERT and WavLM models and evaluated on the SUPERB benchmark for two content-related tasks: automatic speech recognition (ASR) and phoneme recognition (PR). A relative improvement of 3.7% and 8.2% for HuBERT, and 4.1% and 11.7% for WavLM are observed, for the ASR and PR tasks respectively, with only < 3 hours of fine-tuning on a single GPU.
Create account to get full access
Overview
- The paper introduces LASER, a method for improving the performance of content-related tasks by aligning self-supervised representations of speech.
- LASER leverages self-supervised learning to extract useful features from speech data, and then aligns these representations across different speech domains to improve overall performance.
- The approach is evaluated on several content-related tasks, including speaker verification, emotion recognition, and language identification, demonstrating improved results compared to existing methods.
Plain English Explanation
The researchers developed a new technique called LASER (Learning by Aligning Self-supervised Representations of Speech) to help machines better understand and process speech data. The key idea is to first use self-supervised learning to extract useful features from speech samples, without needing any manually labeled data. This allows the system to discover important patterns and characteristics of speech on its own.
Next, LASER aligns these self-supervised speech representations across different types of speech data, such as speech from different speakers, emotions, or languages. By finding the underlying connections between these representations, the system can learn more comprehensive and generalizable features that improve performance on a variety of content-related tasks.
For example, TOWARDS SUPERVISED PERFORMANCE IN SPEAKER VERIFICATION FROM SELF-SUPERVISED REPRESENTATIONS showed how self-supervised representations can be used for speaker verification. Similarly, EFFICIENT INFUSION OF SELF-SUPERVISED REPRESENTATIONS FOR AUTOMATIC SPEECH RECOGNITION demonstrated the benefits of incorporating self-supervised features into speech recognition systems.
The researchers evaluate LASER on tasks like speaker verification, emotion recognition, and language identification, and find that it outperforms existing methods. By leveraging the power of self-supervised learning and cross-domain alignment, LASER is able to extract more meaningful and generalizable features from speech data, leading to improved performance on a range of content-related applications.
Technical Explanation
The core of the LASER approach is to first learn self-supervised representations of speech using techniques like EXPLORING SELF-SUPERVISED MULTI-VIEW CONTRASTIVE LEARNING and STAR: DISTILLING SPEECH TEMPORAL RELATION FOR LIGHTWEIGHT SPEECH RECOGNITION. These self-supervised models are trained to discover useful features from speech data without any manually labeled information.
The researchers then propose a novel alignment strategy to bring these self-supervised representations from different speech domains (e.g., different speakers, emotions, languages) into a common feature space. This is done by training a set of alignment modules that map the domain-specific representations into a shared latent space, where similarities and connections between the representations can be leveraged.
The aligned representations are then used as inputs to downstream content-related tasks, such as speaker verification, emotion recognition, and language identification. By incorporating the rich, cross-domain features learned by LASER, the researchers demonstrate significant performance improvements over baselines that use only task-specific labeled data or simpler self-supervised representations.
Critical Analysis
One potential limitation of the LASER approach is that the alignment process may not be able to fully capture all the nuanced differences between speech domains. While the shared latent space helps to find common patterns, there may still be some domain-specific information that is lost in the alignment. The paper does not extensively explore the impact of imperfect alignment on downstream task performance.
Additionally, the computational and memory requirements of training the alignment modules may be non-trivial, especially as the number of speech domains increases. The researchers mention that they use lightweight alignment modules, but the scalability of the approach to very large-scale, diverse speech datasets is not thoroughly investigated.
It would also be interesting to see how LASER compares to approaches that FILL THE GAP: COMBINING SELF-SUPERVISED REPRESENTATION LEARNING AND TASK-SPECIFIC FINE-TUNING for speech processing tasks. Combining self-supervised representations with task-specific fine-tuning may offer a complementary perspective to the cross-domain alignment strategy used in LASER.
Overall, the LASER framework represents a promising direction for leveraging self-supervised learning to improve the performance of content-related speech tasks. The researchers have demonstrated the effectiveness of the approach on several benchmarks, and the core ideas could likely be extended to other modalities beyond speech as well.
Conclusion
The LASER method introduced in this paper offers a novel approach to improving the performance of content-related speech tasks by aligning self-supervised representations across different speech domains. By first learning useful features in a self-supervised manner and then finding the connections between these representations, LASER is able to extract more generalizable and informative features that lead to better results on downstream applications.
The promising results on tasks like speaker verification, emotion recognition, and language identification suggest that LASER could be a valuable tool for a wide range of speech-based systems. As the field of self-supervised learning continues to advance, techniques like LASER will likely play an increasingly important role in unlocking the full potential of speech data for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
0
0
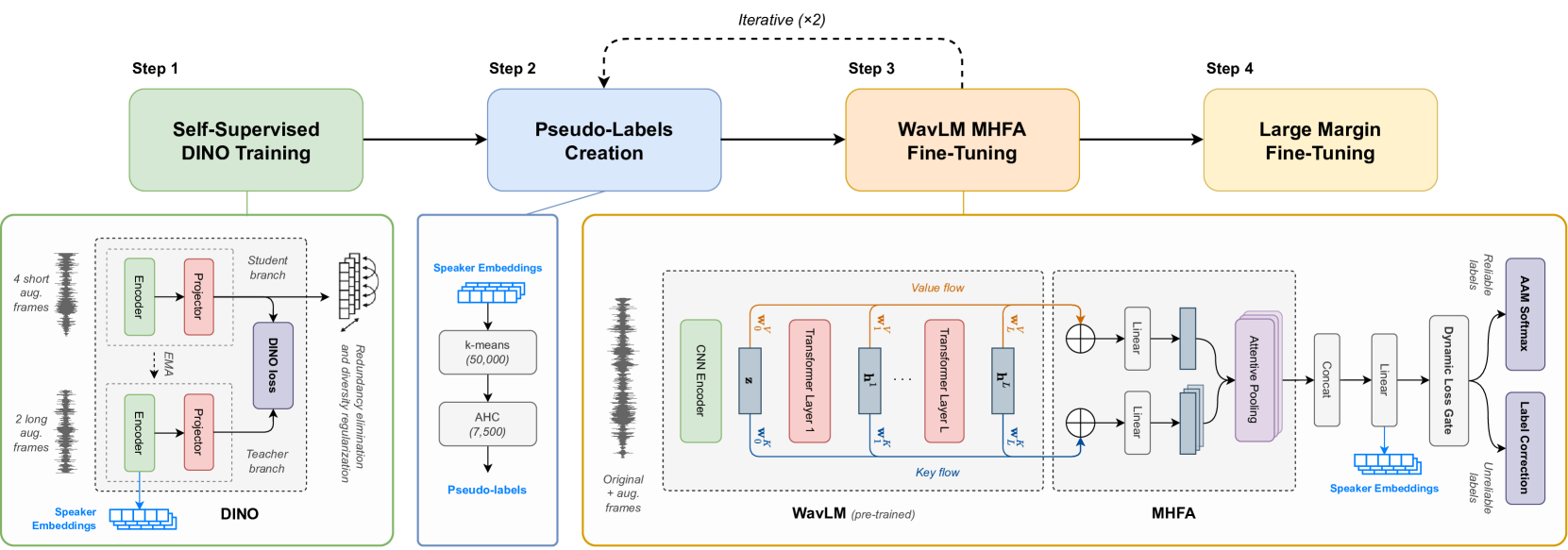
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
6/5/2024

Efficient infusion of self-supervised representations in Automatic Speech Recognition
Darshan Prabhu, Sai Ganesh Mirishkar, Pankaj Wasnik
0
0
Self-supervised learned (SSL) models such as Wav2vec and HuBERT yield state-of-the-art results on speech-related tasks. Given the effectiveness of such models, it is advantageous to use them in conventional ASR systems. While some approaches suggest incorporating these models as a trainable encoder or a learnable frontend, training such systems is extremely slow and requires a lot of computation cycles. In this work, we propose two simple approaches that use (1) framewise addition and (2) cross-attention mechanisms to efficiently incorporate the representations from the SSL model(s) into the ASR architecture, resulting in models that are comparable in size with standard encoder-decoder conformer systems while also avoiding the usage of SSL models during training. Our approach results in faster training and yields significant performance gains on the Librispeech and Tedlium datasets compared to baselines. We further provide detailed analysis and ablation studies that demonstrate the effectiveness of our approach.
4/22/2024

Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
0
0
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
6/13/2024
Fill in the Gap! Combining Self-supervised Representation Learning with Neural Audio Synthesis for Speech Inpainting
Ihab Asaad, Maxime Jacquelin, Olivier Perrotin, Laurent Girin, Thomas Hueber
0
0
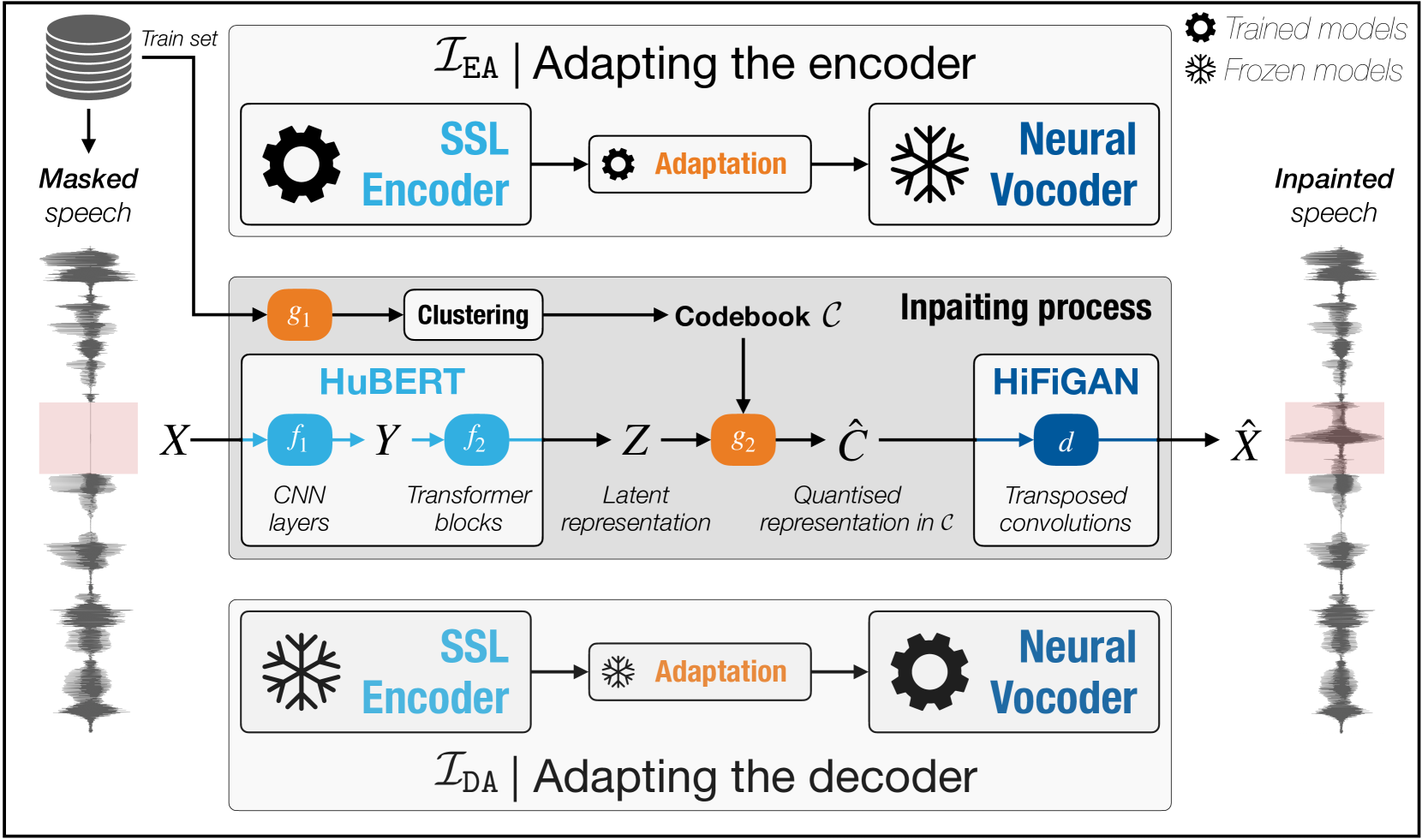
Most speech self-supervised learning (SSL) models are trained with a pretext task which consists in predicting missing parts of the input signal, either future segments (causal prediction) or segments masked anywhere within the input (non-causal prediction). Learned speech representations can then be efficiently transferred to downstream tasks (e.g., automatic speech or speaker recognition). In the present study, we investigate the use of a speech SSL model for speech inpainting, that is reconstructing a missing portion of a speech signal from its surrounding context, i.e., fulfilling a downstream task that is very similar to the pretext task. To that purpose, we combine an SSL encoder, namely HuBERT, with a neural vocoder, namely HiFiGAN, playing the role of a decoder. In particular, we propose two solutions to match the HuBERT output with the HiFiGAN input, by freezing one and fine-tuning the other, and vice versa. Performance of both approaches was assessed in single- and multi-speaker settings, for both informed and blind inpainting configurations (i.e., the position of the mask is known or unknown, respectively), with different objective metrics and a perceptual evaluation. Performances show that if both solutions allow to correctly reconstruct signal portions up to the size of 200ms (and even 400ms in some cases), fine-tuning the SSL encoder provides a more accurate signal reconstruction in the single-speaker setting case, while freezing it (and training the neural vocoder instead) is a better strategy when dealing with multi-speaker data.
5/31/2024