FILS: Self-Supervised Video Feature Prediction In Semantic Language Space
2406.03447
0
0

Abstract
This paper demonstrates a self-supervised approach for learning semantic video representations. Recent vision studies show that a masking strategy for vision and natural language supervision has contributed to developing transferable visual pretraining. Our goal is to achieve a more semantic video representation by leveraging the text related to the video content during the pretraining in a fully self-supervised manner. To this end, we present FILS, a novel self-supervised video Feature prediction In semantic Language Space (FILS). The vision model can capture valuable structured information by correctly predicting masked feature semantics in language space. It is learned using a patch-wise video-text contrastive strategy, in which the text representations act as prototypes for transforming vision features into a language space, which are then used as targets for semantically meaningful feature prediction using our masked encoder-decoder structure. FILS demonstrates remarkable transferability on downstream action recognition tasks, achieving state-of-the-art on challenging egocentric datasets, like Epic-Kitchens, Something-SomethingV2, Charades-Ego, and EGTEA, using ViT-Base. Our efficient method requires less computation and smaller batches compared to previous works.
Create account to get full access
Overview
- This paper introduces FILS, a self-supervised video feature prediction model that learns visual representations by predicting future video features in a semantic language space.
- FILS aims to capture the temporal dynamics and semantic information in videos, which can be useful for various video understanding tasks.
- The model is trained to predict future video features based on the current frame and a language-based representation of the video's semantics.
Plain English Explanation
FILS is a new AI model that tries to understand videos in a more intelligent way. It's like when you watch a video, you can often predict what's going to happen next based on what you've seen so far and what you know about the topic. FILS works a bit like that - it looks at the current frame of a video and uses the meaning of the video (like what objects, actions, and events are happening) to try to guess what the next frame will look like.
By learning to make these predictions, FILS can build up a deeper understanding of the structure and semantics of videos. This could be really useful for all kinds of video-related tasks, like automatically summarizing videos, describing what's happening in a video, or figuring out the layout of a scene from a video.
The key idea is that by learning to predict future video features based on the current frame and the video's meaning, FILS can develop a more sophisticated understanding of the visual representations in the video. This could lead to better performance on a wide range of video-related tasks.
Technical Explanation
FILS is a self-supervised video feature prediction model that learns visual representations by forecasting future video features in a semantic language space. The model takes the current frame of a video and a language-based encoding of the video's semantics as input, and uses this information to predict the features of the next frame.
By learning to make these predictions, FILS aims to capture the temporal dynamics and semantic information present in videos. The model is trained in a self-supervised manner, meaning it learns from the video data itself without the need for manual annotations.
The FILS architecture consists of two main components: a visual encoder that processes the current video frame, and a prediction head that generates the future video features based on the current frame and the semantic encoding. The semantic encoding is obtained by feeding the video's text description (e.g., captions or titles) into a language model.
During training, FILS is tasked with minimizing the error between the predicted future video features and the actual features of the next frame. By optimizing this objective, the model learns to extract meaningful visual representations that are aligned with the video's semantic information.
The authors evaluate FILS on a range of video understanding tasks, including action recognition, video retrieval, and video summarization. The results demonstrate that the self-supervised learning approach used by FILS can lead to improved performance compared to models trained on manual annotations or other self-supervised techniques.
Critical Analysis
The FILS paper presents a novel approach to learning visual representations from videos by predicting future video features in a semantic language space. The key strengths of this work are its ability to capture temporal dynamics and semantic information, which are crucial for many video understanding tasks.
One potential limitation of FILS is the reliance on text-based semantic encodings, which may not always be available or accurately capture the full semantics of a video. The authors acknowledge this and suggest exploring other modalities, such as audio, to further enrich the semantic representations.
Additionally, the paper does not deeply explore the generalization capabilities of FILS beyond the specific tasks evaluated. Further research is needed to understand how well the learned representations transfer to other video-related applications, such as learning spatial features from audio-visual correspondence.
Another area for future work could be investigating the interpretability of the FILS model, as understanding the reasoning behind its predictions could lead to further insights and improvements.
Overall, the FILS paper presents an interesting and promising approach to self-supervised video representation learning, with potential for significant impact on a wide range of video understanding problems.
Conclusion
The FILS model introduces a novel self-supervised approach to learning visual representations from videos by predicting future video features in a semantic language space. By capturing the temporal dynamics and semantic information present in videos, FILS demonstrates improved performance on various video understanding tasks compared to other self-supervised and supervised methods.
The key strength of FILS lies in its ability to learn rich visual representations that are aligned with the semantics of the video content, which could have far-reaching implications for video-related applications. As the authors suggest, exploring the integration of additional modalities and further investigating the generalization and interpretability of the FILS model are promising directions for future research.
Overall, the FILS paper represents an important step forward in the field of self-supervised video representation learning, and its findings could inspire new approaches to understanding and utilizing the wealth of video data available in the digital world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
Unsupervised Open-Vocabulary Object Localization in Videos
Ke Fan, Zechen Bai, Tianjun Xiao, Dominik Zietlow, Max Horn, Zixu Zhao, Carl-Johann Simon-Gabriel, Mike Zheng Shou, Francesco Locatello, Bernt Schiele, Thomas Brox, Zheng Zhang, Yanwei Fu, Tong He
0
0
In this paper, we show that recent advances in video representation learning and pre-trained vision-language models allow for substantial improvements in self-supervised video object localization. We propose a method that first localizes objects in videos via an object-centric approach with slot attention and then assigns text to the obtained slots. The latter is achieved by an unsupervised way to read localized semantic information from the pre-trained CLIP model. The resulting video object localization is entirely unsupervised apart from the implicit annotation contained in CLIP, and it is effectively the first unsupervised approach that yields good results on regular video benchmarks.
6/27/2024

Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, Nicolas Ballas
0
0
This paper explores feature prediction as a stand-alone objective for unsupervised learning from video and introduces V-JEPA, a collection of vision models trained solely using a feature prediction objective, without the use of pretrained image encoders, text, negative examples, reconstruction, or other sources of supervision. The models are trained on 2 million videos collected from public datasets and are evaluated on downstream image and video tasks. Our results show that learning by predicting video features leads to versatile visual representations that perform well on both motion and appearance-based tasks, without adaption of the model's parameters; e.g., using a frozen backbone. Our largest model, a ViT-H/16 trained only on videos, obtains 81.9% on Kinetics-400, 72.2% on Something-Something-v2, and 77.9% on ImageNet1K.
4/15/2024
🌀
Language-Guided Self-Supervised Video Summarization Using Text Semantic Matching Considering the Diversity of the Video
Tomoya Sugihara, Shuntaro Masuda, Ling Xiao, Toshihiko Yamasaki
0
0
Current video summarization methods primarily depend on supervised computer vision techniques, which demands time-consuming manual annotations. Further, the annotations are always subjective which make this task more challenging. To address these issues, we analyzed the feasibility in transforming the video summarization into a text summary task and leverage Large Language Models (LLMs) to boost video summarization. This paper proposes a novel self-supervised framework for video summarization guided by LLMs. Our method begins by generating captions for video frames, which are then synthesized into text summaries by LLMs. Subsequently, we measure semantic distance between the frame captions and the text summary. It's worth noting that we propose a novel loss function to optimize our model according to the diversity of the video. Finally, the summarized video can be generated by selecting the frames whose captions are similar with the text summary. Our model achieves competitive results against other state-of-the-art methods and paves a novel pathway in video summarization.
5/16/2024
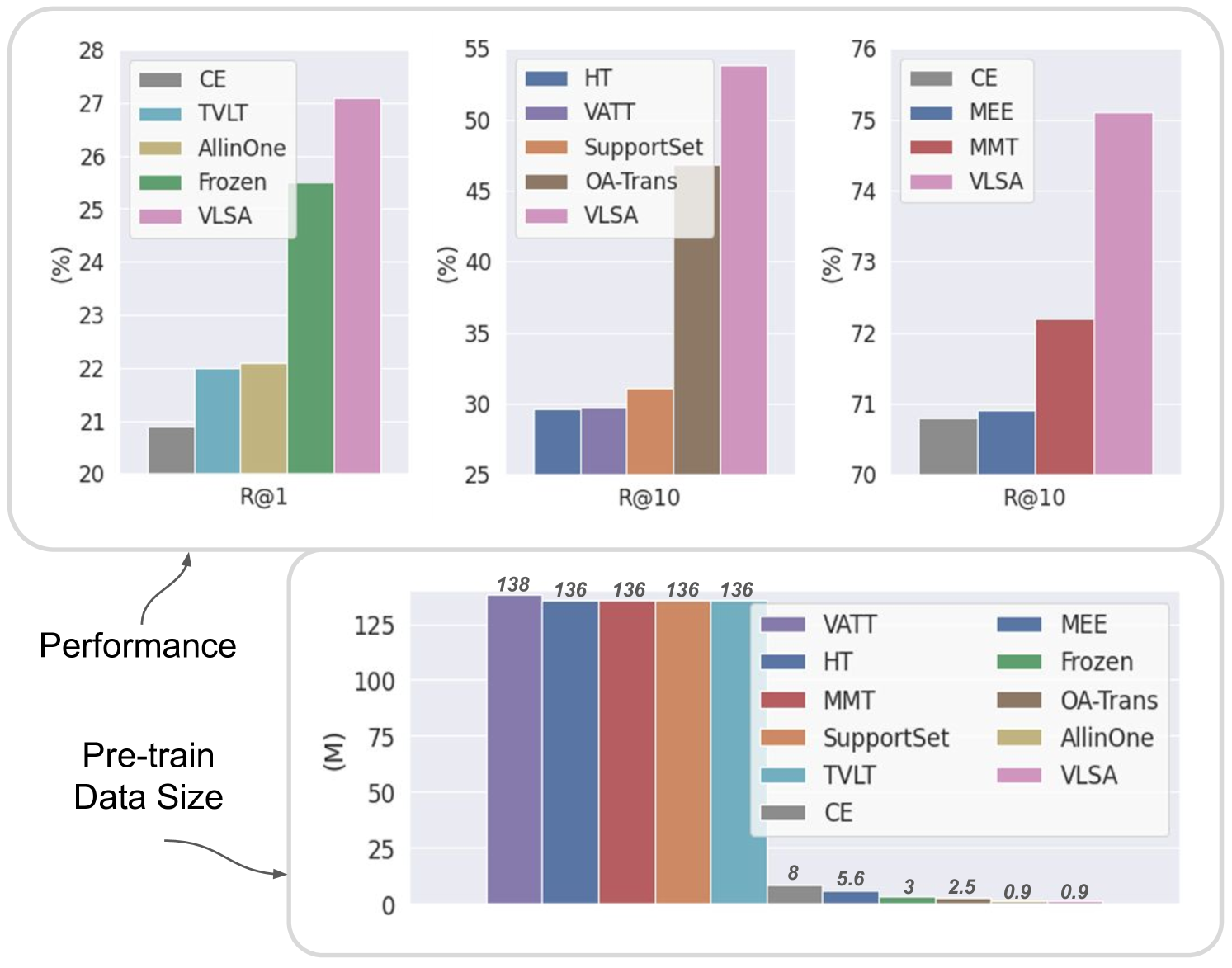
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
0
0
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
5/14/2024