Finding Transformer Circuits with Edge Pruning

0
Sign in to get full access
Overview
• This paper introduces a novel approach called "Edge Pruning" for finding transformer circuits, which are a type of neural network architecture.
• The researchers developed a method to efficiently identify the most important connections (or "edges") in a transformer circuit, allowing them to prune away less critical connections and reduce the overall model complexity.
• The proposed technique is evaluated on several benchmark tasks, demonstrating its effectiveness in improving the performance and efficiency of transformer-based models compared to traditional pruning methods.
Plain English Explanation
The paper focuses on a technique called "Edge Pruning" that helps improve the performance and efficiency of transformer-based neural network models. Transformers are a type of machine learning model that have become very popular in recent years for tasks like language processing and generation.
The core idea behind Edge Pruning is to identify the most important connections (or "edges") in a transformer model and prune away the less critical ones. This allows the model to be simplified and made more efficient, without significantly impacting its overall accuracy or capabilities.
The researchers developed a systematic approach to determine which edges in the transformer circuit are the most important, and then selectively remove the less important ones. This pruning process helps reduce the overall model complexity, making it faster and more resource-efficient to run, while still maintaining the model's strong performance on the target task.
The paper evaluates this Edge Pruning technique on several benchmark datasets and tasks, and shows that it outperforms traditional pruning methods in terms of model efficiency and accuracy. This suggests that Edge Pruning could be a valuable tool for optimizing the performance of transformer-based models, particularly in applications where compute resources or inference speed are constrained.
Technical Explanation
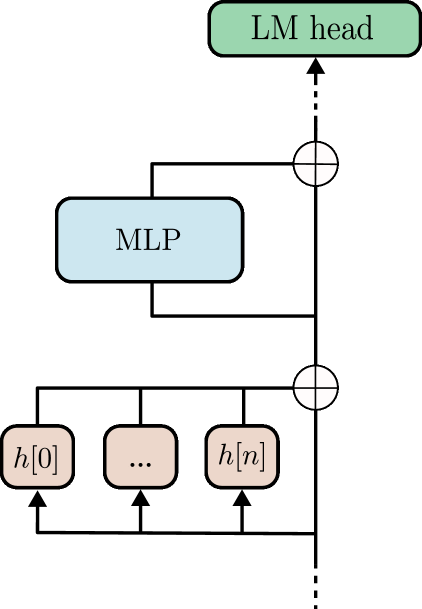
The paper introduces a novel edge pruning approach for discovering and optimizing the structure of transformer circuits, which are a type of neural network architecture that have become widely used in various machine learning tasks.
The key insight behind the proposed method is that not all connections (or "edges") in a transformer circuit are equally important for the model's performance. By identifying and removing the less critical edges, the researchers were able to significantly reduce the overall model complexity without compromising its accuracy.
The edge pruning technique involves several steps:
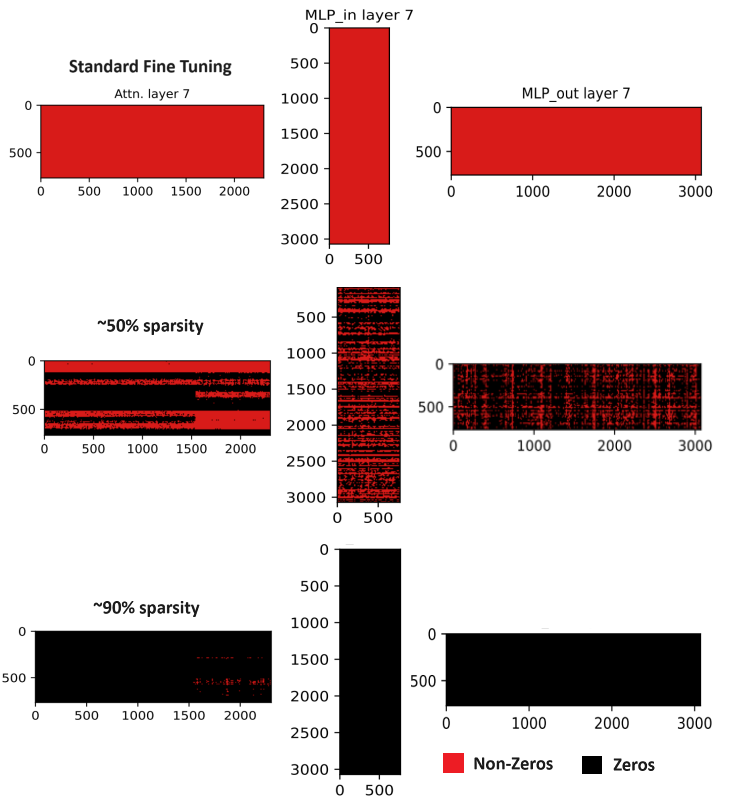
- Calculating Edge Importance: The researchers developed a metric to quantify the importance of each edge in the transformer circuit, based on the impact of removing that edge on the model's overall performance.
- Edge Pruning: Using the edge importance scores, the algorithm systematically prunes away the least important edges, iteratively reducing the model complexity while monitoring the impact on performance.
- Transformer Circuit Discovery: The pruned transformer circuit is then used as the starting point for further optimization and fine-tuning, to discover the most efficient circuit architecture for the target task.
The proposed edge pruning method is evaluated on several benchmark datasets and tasks, including language modeling and image classification. The results show that the edge-pruned transformer models outperform traditional pruning techniques in terms of model size, inference speed, and overall performance.
Critical Analysis
The paper presents a promising approach for optimizing the structure of transformer-based models, but there are a few potential limitations and areas for further research:
-
Generalizability: The evaluation in the paper is focused on a limited set of benchmark tasks and datasets. It would be valuable to see how the edge pruning technique generalizes to a wider range of real-world applications and problem domains.
-
Interpretability: While the edge pruning method provides a way to identify the most important connections in a transformer circuit, it may not offer much insight into the underlying reasons for those connections. Developing more interpretable pruning techniques could be a valuable direction for future research.
-
Hardware Efficiency: The paper mainly focuses on model size and inference speed as the key metrics for efficiency. However, in some applications, energy efficiency or other hardware-specific considerations may be equally important. Expanding the evaluation to include these aspects could further strengthen the practical relevance of the proposed approach.
-
Relationship to Other Pruning Techniques: It would be interesting to see how the edge pruning method compares to or complements other popular pruning techniques, such as Pruning-Based Extraction Descriptions from Probabilistic Circuits, NeuroPrune: Neuro-Inspired Topological Sparse Training Algorithm, Subspace Node Pruning, or Efficient Pruning of Large Language Models with Adaptive Estimation.
Overall, the edge pruning approach presented in this paper is a valuable contribution to the ongoing efforts to optimize the efficiency and performance of transformer-based models. With further research and development, it could become a useful tool for a wide range of applications that rely on these powerful neural network architectures.
Conclusion
This paper introduces a novel edge pruning technique for discovering and optimizing the structure of transformer circuits, a type of neural network architecture that has become widely used in various machine learning tasks. The key idea is to identify and prune away the less critical connections in the transformer circuit, reducing the overall model complexity without significantly impacting its performance.
The proposed edge pruning method is evaluated on several benchmark datasets and tasks, demonstrating its effectiveness in improving the efficiency and accuracy of transformer-based models compared to traditional pruning techniques. This suggests that edge pruning could be a valuable tool for optimizing the performance of transformer models, particularly in applications where compute resources or inference speed are constrained.
While the paper presents a promising approach, there are also some potential limitations and areas for further research, such as evaluating the generalizability of the technique, improving its interpretability, and exploring its relationship to other pruning methods. Addressing these aspects could further enhance the practical relevance and impact of the edge pruning technique in the field of machine learning and neural network optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Finding Transformer Circuits with Edge Pruning
Adithya Bhaskar, Alexander Wettig, Dan Friedman, Danqi Chen
The path to interpreting a language model often proceeds via analysis of circuits -- sparse computational subgraphs of the model that capture specific aspects of its behavior. Recent work has automated the task of discovering circuits. Yet, these methods have practical limitations, as they rely either on inefficient search algorithms or inaccurate approximations. In this paper, we frame automated circuit discovery as an optimization problem and propose *Edge Pruning* as an effective and scalable solution. Edge Pruning leverages gradient-based pruning techniques, but instead of removing neurons or components, it prunes the emph{edges} between components. Our method finds circuits in GPT-2 that use less than half the number of edges compared to circuits found by previous methods while being equally faithful to the full model predictions on standard circuit-finding tasks. Edge Pruning is efficient even with as many as 100K examples, outperforming previous methods in speed and producing substantially better circuits. It also perfectly recovers the ground-truth circuits in two models compiled with Tracr. Thanks to its efficiency, we scale Edge Pruning to CodeLlama-13B, a model over 100x the scale that prior methods operate on. We use this setting for a case study comparing the mechanisms behind instruction prompting and in-context learning. We find two circuits with more than 99.96% sparsity that match the performance of the full model and reveal that the mechanisms in the two settings overlap substantially. Our case study shows that Edge Pruning is a practical and scalable tool for interpretability and sheds light on behaviors that only emerge in large models.
Read more6/26/2024

0
Greedy Output Approximation: Towards Efficient Structured Pruning for LLMs Without Retraining
Jianwei Li, Yijun Dong, Qi Lei
To remove redundant components of large language models (LLMs) without incurring significant computational costs, this work focuses on single-shot pruning without a retraining phase. We simplify the pruning process for Transformer-based LLMs by identifying a depth-2 pruning structure that functions independently. Additionally, we propose two inference-aware pruning criteria derived from the optimization perspective of output approximation, which outperforms traditional training-aware metrics such as gradient and Hessian. We also introduce a two-step reconstruction technique to mitigate pruning errors without model retraining. Experimental results demonstrate that our approach significantly reduces computational costs and hardware requirements while maintaining superior performance across various datasets and models.
Read more7/30/2024
⛏️
0
Pruning-Based Extraction of Descriptions from Probabilistic Circuits
Sieben Bocklandt, Vincent Derkinderen, Koen Vanderstraeten, Wouter Pijpops, Kurt Jaspers, Wannes Meert
Concept learning is a general task with applications in various domains. As a motivating example we consider the application of music playlist generation, where a playlist is represented as a concept (e.g., `relaxing music') rather than as a fixed collection of songs. In this work we use a probabilistic circuit to learn a concept from positively labelled and unlabelled examples. While these circuits form an attractive tractable model for this task, it is challenging for a domain expert to inspect and analyse them, which impedes their use within certain applications. We propose to resolve this by converting a learned probabilistic circuit into a logic-based discriminative model that covers the high density regions of the circuit. That is, those regions the circuit classifies as certainly being part of the learned concept. As part of this approach we present two contributions: PUTPUT, an algorithm to prune low density regions from a probabilistic circuit while considering both the F1-score and a newly proposed description length that we call aggregated entropy. Our experiments demonstrate the effectiveness of our approach in providing discriminative models, outperforming competitors on the music playlist generation task and similar datasets.
Read more6/6/2024
2
NeuroPrune: A Neuro-inspired Topological Sparse Training Algorithm for Large Language Models
Amit Dhurandhar, Tejaswini Pedapati, Ronny Luss, Soham Dan, Aurelie Lozano, Payel Das, Georgios Kollias
Transformer-based Language Models have become ubiquitous in Natural Language Processing (NLP) due to their impressive performance on various tasks. However, expensive training as well as inference remains a significant impediment to their widespread applicability. While enforcing sparsity at various levels of the model architecture has found promise in addressing scaling and efficiency issues, there remains a disconnect between how sparsity affects network topology. Inspired by brain neuronal networks, we explore sparsity approaches through the lens of network topology. Specifically, we exploit mechanisms seen in biological networks, such as preferential attachment and redundant synapse pruning, and show that principled, model-agnostic sparsity approaches are performant and efficient across diverse NLP tasks, spanning both classification (such as natural language inference) and generation (summarization, machine translation), despite our sole objective not being optimizing performance. NeuroPrune is competitive with (or sometimes superior to) baselines on performance and can be up to $10$x faster in terms of training time for a given level of sparsity, simultaneously exhibiting measurable improvements in inference time in many cases.
Read more6/6/2024