Greedy Output Approximation: Towards Efficient Structured Pruning for LLMs Without Retraining

0

Sign in to get full access
Overview
- The paper proposes a novel approach called Greedy Output Approximation (GOA) for efficiently pruning large language models (LLMs) without retraining.
- GOA aims to identify the most important model parameters to preserve, allowing for significant model compression while maintaining performance.
- The method involves a greedy algorithm that iteratively prunes the least important model outputs, approximating the original model's behavior.
Plain English Explanation
The researchers have developed a new technique called Greedy Output Approximation (GOA) that can significantly reduce the size of large language models without having to retrain them from scratch. Large language models, like the ones used in chatbots and other AI assistants, can be very complex and take a long time to train. This makes them expensive to deploy, especially on devices with limited computational power.
GOA aims to address this by identifying the most important parts of the model and removing the less important ones. The key idea is to use a greedy algorithm that iteratively prunes the model's outputs, one by one, while trying to keep the model's overall behavior as close as possible to the original. This allows for substantial model compression without having to retrain the entire model, which can be a very time-consuming process.
By using this approach, the researchers were able to reduce the size of large language models by up to 90% while maintaining a high level of performance on various tasks. This could make it much more feasible to deploy these powerful AI models on a wider range of devices, from smartphones to edge computing systems, opening up new possibilities for real-world applications.
Technical Explanation
The paper introduces a novel pruning technique called Greedy Output Approximation (GOA) for efficiently compressing large language models without requiring retraining. The key idea behind GOA is to iteratively prune the model's output neurons in a greedy fashion, while attempting to preserve the original model's behavior as closely as possible.
The method works by first ranking the output neurons based on their importance, determined by the sensitivity of the model's output to changes in each neuron's value. The least important neurons are then removed in a greedy fashion, with the model's behavior approximated at each step using a novel objective function that balances output approximation and model compression.
The researchers demonstrate the effectiveness of GOA through extensive experiments on various large language models, including GPT-2 and BERT. They show that GOA can achieve up to 90% model compression while maintaining high performance on a range of NLP tasks, significantly outperforming traditional pruning approaches that require expensive retraining.
The paper also provides theoretical analysis to justify the effectiveness of the greedy pruning strategy, and discusses several practical considerations, such as the impact of pruning on model robustness and the transferability of pruned models to different tasks.
Critical Analysis
The Greedy Output Approximation (GOA) approach presented in the paper represents a promising step towards efficient structured pruning of large language models without retraining. By focusing on preserving the model's output behavior rather than its internal parameters, the researchers have developed a practical and scalable method for model compression that could have significant real-world implications.
One potential limitation of the approach is that it may not capture more complex dependencies or interactions within the model's internal structure, which could impact the model's generalization or robustness. The authors acknowledge this and suggest that combining GOA with other pruning techniques, such as sensitivity-aware pruning, could be a fruitful area for future research.
Additionally, the paper does not extensively explore the impact of GOA on the model's performance on out-of-distribution or adversarial inputs. It would be valuable to investigate the effects of pruning on the model's robustness and generalization, especially as these properties are crucial for real-world deployment of large language models.
Overall, the Greedy Output Approximation technique represents an exciting development in the field of model compression, and the authors' insights and findings could inspire further advancements in efficient and practical pruning methods for large language models.
Conclusion
The Greedy Output Approximation (GOA) approach proposed in this paper offers a novel and efficient way to prune large language models without the need for costly retraining. By focusing on preserving the model's output behavior rather than its internal structure, the researchers have developed a practical technique that can achieve up to 90% model compression while maintaining high performance on a range of NLP tasks.
This breakthrough could have significant implications for the real-world deployment of large language models, making it more feasible to run these powerful AI systems on devices with limited computational resources, such as smartphones or edge computing systems. As the field of natural language processing continues to advance, techniques like GOA will be crucial for unlocking the full potential of large language models and enabling their widespread adoption across a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Greedy Output Approximation: Towards Efficient Structured Pruning for LLMs Without Retraining
Jianwei Li, Yijun Dong, Qi Lei
To remove redundant components of large language models (LLMs) without incurring significant computational costs, this work focuses on single-shot pruning without a retraining phase. We simplify the pruning process for Transformer-based LLMs by identifying a depth-2 pruning structure that functions independently. Additionally, we propose two inference-aware pruning criteria derived from the optimization perspective of output approximation, which outperforms traditional training-aware metrics such as gradient and Hessian. We also introduce a two-step reconstruction technique to mitigate pruning errors without model retraining. Experimental results demonstrate that our approach significantly reduces computational costs and hardware requirements while maintaining superior performance across various datasets and models.
Read more7/30/2024

0
Optimization-based Structural Pruning for Large Language Models without Back-Propagation
Yuan Gao, Zujing Liu, Weizhong Zhang, Bo Du, Gui-Song Xia
Compared to the moderate size of neural network models, structural weight pruning on the Large-Language Models (LLMs) imposes a novel challenge on the efficiency of the pruning algorithms, due to the heavy computation/memory demands of the LLMs. Recent efficient LLM pruning methods typically operate at the post-training phase without the expensive weight finetuning, however, their pruning criteria often rely on heuristically designed metrics, potentially leading to suboptimal performance. We instead propose a novel optimization-based structural pruning that learns the pruning masks in a probabilistic space directly by optimizing the loss of the pruned model. To preserve the efficiency, our method 1) works at post-training phase} and 2) eliminates the back-propagation through the LLM per se during the optimization (i.e., only requires the forward pass of the LLM). We achieve this by learning an underlying Bernoulli distribution to sample binary pruning masks, where we decouple the Bernoulli parameters from the LLM loss, thus facilitating an efficient optimization via a policy gradient estimator without back-propagation. As a result, our method is able to 1) operate at structural granularities of channels, heads, and layers, 2) support global and heterogeneous pruning (i.e., our method automatically determines different redundancy for different layers), and 3) optionally use a metric-based method as initialization (of our Bernoulli distributions). Extensive experiments on LLaMA, LLaMA-2, and Vicuna using the C4 and WikiText2 datasets demonstrate that our method operates for 2.7 hours with around 35GB memory for the 13B models on a single A100 GPU, and our pruned models outperform the state-of-the-arts w.r.t. perplexity. Codes will be released.
Read more6/18/2024

0
Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Jun Liu, Chao Wu, Changdi Yang, Hao Tang, Zhenglun Kong, Geng Yuan, Wei Niu, Dong Huang, Yanzhi Wang
Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
Read more5/16/2024
0
Reconstruct the Pruned Model without Any Retraining
Pingjie Wang, Ziqing Fan, Shengchao Hu, Zhe Chen, Yanfeng Wang, Yu Wang
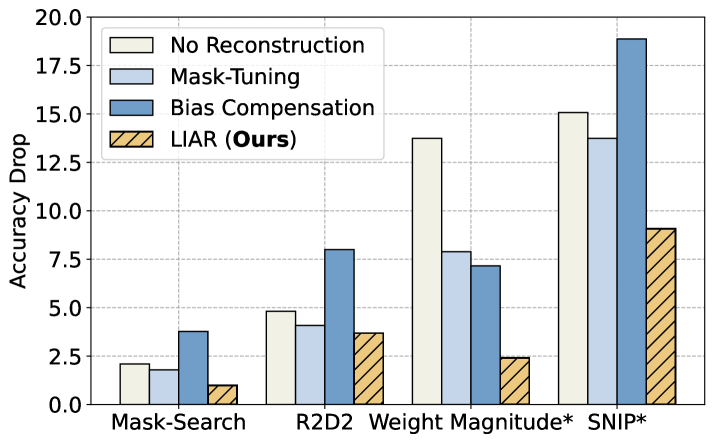
Structured pruning is a promising hardware-friendly compression technique for large language models (LLMs), which is expected to be retraining-free to avoid the enormous retraining cost. This retraining-free paradigm involves (1) pruning criteria to define the architecture and (2) distortion reconstruction to restore performance. However, existing methods often emphasize pruning criteria while using reconstruction techniques that are specific to certain modules or criteria, resulting in limited generalizability. To address this, we introduce the Linear Interpolation-based Adaptive Reconstruction (LIAR) framework, which is both efficient and effective. LIAR does not require back-propagation or retraining and is compatible with various pruning criteria and modules. By applying linear interpolation to the preserved weights, LIAR minimizes reconstruction error and effectively reconstructs the pruned output. Our evaluations on benchmarks such as GLUE, SQuAD, WikiText, and common sense reasoning show that LIAR enables a BERT model to maintain 98% accuracy even after removing 50% of its parameters and achieves top performance for LLaMA in just a few minutes.
Read more7/19/2024