LOGO: A Long-Form Video Dataset for Group Action Quality Assessment

0

Sign in to get full access
Overview
- The paper presents LOGO, a new long-form video dataset for assessing the quality of group actions.
- The dataset contains high-quality, long-duration videos of various group activities, with detailed annotations for action quality.
- The authors aim to address the lack of large-scale, real-world datasets for evaluating group action understanding models.
Plain English Explanation
The researchers have created a new video dataset called LOGO that could help improve artificial intelligence (AI) systems for analyzing group activities. Previously, there haven't been many large, real-world video datasets available for training and testing AI models that assess the quality of group actions, like sports teams working together or groups of people collaborating on a task.
The LOGO dataset includes high-quality, lengthy videos of different group activities, along with detailed annotations that rate the quality of the group's performance. This could be very useful for developing more advanced AI models that can accurately evaluate how well groups of people work together, which has applications in areas like sports, education, and business.
By providing a large, diverse set of example videos with quality ratings, the LOGO dataset aims to help AI researchers and developers create systems that can better understand and assess group dynamics and collaboration. This could lead to AI assistants that can provide more meaningful feedback to teams or groups trying to improve their collective performance.
Technical Explanation
The paper introduces the LOGO dataset, which was created to address the lack of large-scale, real-world video datasets for evaluating group action understanding models. LOGO contains high-quality, long-duration videos of various group activities, such as sports, games, and collaborative tasks, along with detailed annotations for assessing the quality of the group's performance.
The dataset includes over 1,000 videos with an average length of 5 minutes, covering a diverse range of group activities. Each video was annotated by multiple human raters to provide a comprehensive assessment of the group's action quality across several dimensions, including coordination, teamwork, and overall effectiveness.
The authors designed the dataset to support the development and evaluation of advanced AI models for understanding and assessing group dynamics and collaboration. By providing a large, real-world collection of annotated videos, LOGO can be used to train and benchmark group action quality assessment models, which could have applications in areas like sports analytics, workforce management, and educational evaluation.
The paper also discusses the potential limitations of the LOGO dataset, such as the subjective nature of the quality annotations and the diversity of the group activities represented. The authors suggest that future work could explore ways to further expand and refine the dataset to address these challenges.
Critical Analysis
The LOGO dataset represents an important contribution to the field of group action understanding, as it provides a large-scale, real-world resource for training and evaluating AI models in this area. The detailed quality annotations and the diversity of the video content make LOGO a valuable tool for researchers and developers working on group action assessment systems.
However, the authors acknowledge some potential limitations of the dataset, such as the subjectivity of the quality ratings and the possibility that certain group activities may be underrepresented. Additionally, the paper does not provide a comprehensive analysis of the dataset's characteristics, such as the distribution of quality scores or the level of agreement among raters.
Further research could explore ways to refine the annotation process, perhaps by incorporating more objective measures of group performance or by investigating the factors that influence human raters' assessments. Additionally, the dataset could be expanded to include a wider range of group activities, such as those found in workplace or educational settings, to better reflect the diverse range of real-world group dynamics.
Overall, the LOGO dataset represents an important step forward in the development of group action understanding models, and the authors' efforts to create a large-scale, high-quality resource for this task are commendable. As the field of AI continues to advance, datasets like LOGO will play a crucial role in driving progress and enabling the creation of more sophisticated systems for evaluating and improving group performance.
Conclusion
The LOGO dataset presented in this paper is a significant contribution to the field of group action understanding. By providing a large-scale, real-world collection of annotated videos covering a diverse range of group activities, LOGO offers a valuable resource for training and evaluating AI models that can assess the quality of group performance.
The detailed annotations and the dataset's size and diversity make it a promising tool for advancing the state of the art in group action understanding. As AI systems become increasingly capable of analyzing complex human behaviors, datasets like LOGO will be essential for developing models that can provide meaningful feedback and support for improving group collaboration and effectiveness.
While the paper acknowledges some potential limitations of the dataset, the authors' efforts to create this resource are an important step forward in the field. Future research can build upon the LOGO dataset to further refine group action assessment techniques and expand their applicability to a wider range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LOGO: A Long-Form Video Dataset for Group Action Quality Assessment
Shiyi Zhang, Wenxun Dai, Sujia Wang, Xiangwei Shen, Jiwen Lu, Jie Zhou, Yansong Tang
Action quality assessment (AQA) has become an emerging topic since it can be extensively applied in numerous scenarios. However, most existing methods and datasets focus on single-person short-sequence scenes, hindering the application of AQA in more complex situations. To address this issue, we construct a new multi-person long-form video dataset for action quality assessment named LOGO. Distinguished in scenario complexity, our dataset contains 200 videos from 26 artistic swimming events with 8 athletes in each sample along with an average duration of 204.2 seconds. As for richness in annotations, LOGO includes formation labels to depict group information of multiple athletes and detailed annotations on action procedures. Furthermore, we propose a simple yet effective method to model relations among athletes and reason about the potential temporal logic in long-form videos. Specifically, we design a group-aware attention module, which can be easily plugged into existing AQA methods, to enrich the clip-wise representations based on contextual group information. To benchmark LOGO, we systematically conduct investigations on the performance of several popular methods in AQA and action segmentation. The results reveal the challenges our dataset brings. Extensive experiments also show that our approach achieves state-of-the-art on the LOGO dataset. The dataset and code will be released at url{https://github.com/shiyi-zh0408/LOGO }.
Read more4/9/2024

0
Interpretable Long-term Action Quality Assessment
Xu Dong, Xinran Liu, Wanqing Li, Anthony Adeyemi-Ejeye, Andrew Gilbert
Long-term Action Quality Assessment (AQA) evaluates the execution of activities in videos. However, the length presents challenges in fine-grained interpretability, with current AQA methods typically producing a single score by averaging clip features, lacking detailed semantic meanings of individual clips. Long-term videos pose additional difficulty due to the complexity and diversity of actions, exacerbating interpretability challenges. While query-based transformer networks offer promising long-term modeling capabilities, their interpretability in AQA remains unsatisfactory due to a phenomenon we term Temporal Skipping, where the model skips self-attention layers to prevent output degradation. To address this, we propose an attention loss function and a query initialization method to enhance performance and interpretability. Additionally, we introduce a weight-score regression module designed to approximate the scoring patterns observed in human judgments and replace conventional single-score regression, improving the rationality of interpretability. Our approach achieves state-of-the-art results on three real-world, long-term AQA benchmarks. Our code is available at: https://github.com/dx199771/Interpretability-AQA
Read more8/22/2024

0
Hierarchical NeuroSymbolic Approach for Comprehensive and Explainable Action Quality Assessment
Lauren Okamoto, Paritosh Parmar
Action quality assessment (AQA) applies computer vision to quantitatively assess the performance or execution of a human action. Current AQA approaches are end-to-end neural models, which lack transparency and tend to be biased because they are trained on subjective human judgements as ground-truth. To address these issues, we introduce a neuro-symbolic paradigm for AQA, which uses neural networks to abstract interpretable symbols from video data and makes quality assessments by applying rules to those symbols. We take diving as the case study. We found that domain experts prefer our system and find it more informative than purely neural approaches to AQA in diving. Our system also achieves state-of-the-art action recognition and temporal segmentation, and automatically generates a detailed report that breaks the dive down into its elements and provides objective scoring with visual evidence. As verified by a group of domain experts, this report may be used to assist judges in scoring, help train judges, and provide feedback to divers. Annotated training data and code: https://github.com/laurenok24/NSAQA.
Read more5/27/2024
0
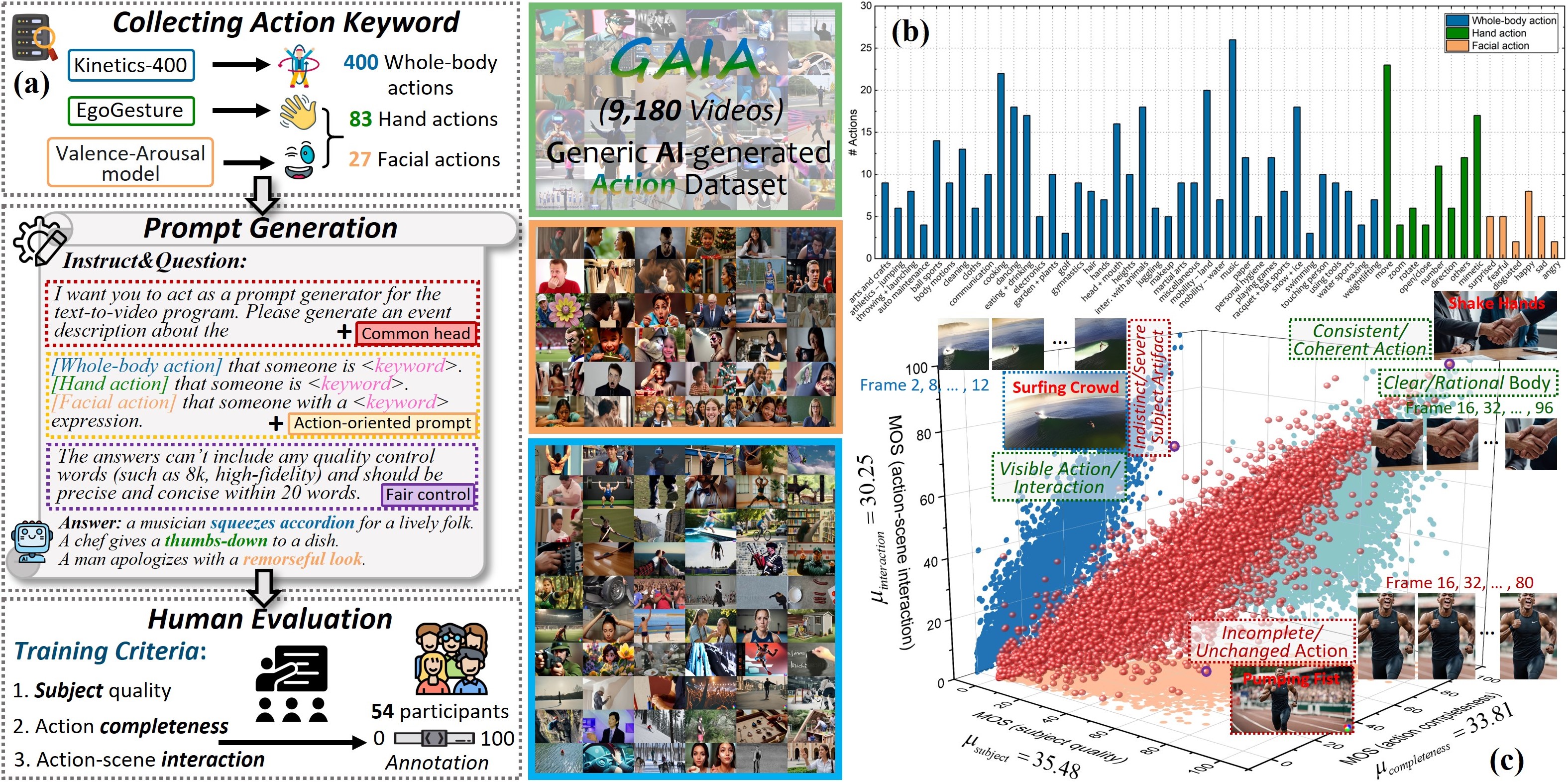
GAIA: Rethinking Action Quality Assessment for AI-Generated Videos
Zijian Chen, Wei Sun, Yuan Tian, Jun Jia, Zicheng Zhang, Jiarui Wang, Ru Huang, Xiongkuo Min, Guangtao Zhai, Wenjun Zhang
Assessing action quality is both imperative and challenging due to its significant impact on the quality of AI-generated videos, further complicated by the inherently ambiguous nature of actions within AI-generated video (AIGV). Current action quality assessment (AQA) algorithms predominantly focus on actions from real specific scenarios and are pre-trained with normative action features, thus rendering them inapplicable in AIGVs. To address these problems, we construct GAIA, a Generic AI-generated Action dataset, by conducting a large-scale subjective evaluation from a novel causal reasoning-based perspective, resulting in 971,244 ratings among 9,180 video-action pairs. Based on GAIA, we evaluate a suite of popular text-to-video (T2V) models on their ability to generate visually rational actions, revealing their pros and cons on different categories of actions. We also extend GAIA as a testbed to benchmark the AQA capacity of existing automatic evaluation methods. Results show that traditional AQA methods, action-related metrics in recent T2V benchmarks, and mainstream video quality methods correlate poorly with human opinions, indicating a sizable gap between current models and human action perception patterns in AIGVs. Our findings underscore the significance of action quality as a unique perspective for studying AIGVs and can catalyze progress towards methods with enhanced capacities for AQA in AIGVs.
Read more6/11/2024