Fine-grained large-scale content recommendations for MSX sellers

0

Sign in to get full access
Overview
- This paper presents a large-scale content recommendation system for MSX sellers, which aims to provide fine-grained recommendations to help sellers identify the most relevant content to promote their products.
- The key innovation is a large-scale semantic matching approach that can efficiently match seller content with a vast catalog of potential recommendation content.
- The system was evaluated on a real-world dataset and shown to outperform several baseline recommendation methods.
Plain English Explanation
The paper describes a recommendation system designed to help MSX sellers (an online marketplace) find the most relevant content to promote their products. The core idea is to use advanced language models and semantic matching techniques to automatically identify the best content recommendations for each seller's specific products and offerings.
This is a challenging task because the recommendation catalog can be extremely large, potentially containing millions of articles, videos, or other content pieces. The paper cites relevant research on using large language models for recommendation systems.
To address this, the researchers developed a scalable semantic matching approach that can efficiently compare seller content to the full recommendation catalog and surface the most relevant items. This allows the system to provide highly personalized and fine-grained recommendations, going beyond simple category-based or popularity-based approaches.
The paper also discusses how this work relates to other research on using large language models for content recommendations, such as in the news domain.
Technical Explanation
The paper presents a large-scale content recommendation system for MSX sellers. The key components are:
-
Seller Content Encoder: This module takes the seller's product descriptions, images, and other content as input and encodes them into a high-dimensional semantic representation using a large language model.
-
Recommendation Catalog Encoder: The full catalog of potential recommendation content (e.g., articles, videos) is also encoded into semantic representations using the same language model approach.
-
Semantic Matching: The system then performs efficient similarity matching between the seller content and the recommendation catalog to identify the most relevant content for each seller.
The authors evaluate this approach on a real-world dataset of MSX sellers and content, comparing it to several baseline recommendation methods. The results show that the semantic matching approach significantly outperforms the baselines in terms of recommendation relevance and user engagement metrics.
The paper notes that this work builds on recent advancements in using large language models for recommendation systems, which have shown promising results in a variety of domains.
Critical Analysis
The paper presents a well-designed and rigorously evaluated content recommendation system that addresses an important real-world problem for MSX sellers. The semantic matching approach seems well-justified and the results demonstrate its effectiveness.
One potential limitation is that the system relies on the quality and coverage of the underlying language model, which could introduce biases or gaps in the semantic representations. The paper acknowledges this challenge and discusses how further research on large language model robustness and personalization could help address it.
Additionally, the paper does not explore the potential privacy or ethical implications of deploying such a large-scale content recommendation system, which could raise concerns around data privacy, algorithmic bias, or the societal impact of hyper-personalized content recommendations. Further research in these areas would be valuable.
Conclusion
This paper presents a novel large-scale content recommendation system for MSX sellers that leverages advanced language modeling and semantic matching techniques. The system is shown to outperform traditional recommendation approaches, highlighting the potential of these methods to provide highly personalized and relevant content recommendations at scale.
While the technical implementation is impressive, the paper also raises important questions about the broader implications of such recommendation systems, particularly around data privacy, algorithmic fairness, and the societal impact of hyper-personalized content curation. As these technologies continue to advance, it will be crucial for researchers and practitioners to carefully consider these ethical and societal considerations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fine-grained large-scale content recommendations for MSX sellers
Manpreet Singh, Ravdeep Pasricha, Ravi Prasad Kondapalli, Kiran R, Nitish Singh, Akshita Agarwalla, Manoj R, Manish Prabhakar, Laurent Bou'e
One of the most critical tasks of Microsoft sellers is to meticulously track and nurture potential business opportunities through proactive engagement and tailored solutions. Recommender systems play a central role to help sellers achieve their goals. In this paper, we present a content recommendation model which surfaces various types of content (technical documentation, comparison with competitor products, customer success stories etc.) that sellers can share with their customers or use for their own self-learning. The model operates at the opportunity level which is the lowest possible granularity and the most relevant one for sellers. It is based on semantic matching between metadata from the contents and carefully selected attributes of the opportunities. Considering the volume of seller-managed opportunities in organizations such as Microsoft, we show how to perform efficient semantic matching over a very large number of opportunity-content combinations. The main challenge is to ensure that the top-5 relevant contents for each opportunity are recommended out of a total of $approx 40,000$ published contents. We achieve this target through an extensive comparison of different model architectures and feature selection. Finally, we further examine the quality of the recommendations in a quantitative manner using a combination of human domain experts as well as by using the recently proposed LLM as a judge framework.
Read more7/10/2024
🤖
0
Smart E-commerce Recommendations with Semantic AI
M. Badouch, M. Boutaounte
In e-commerce, web mining for page recommendations is widely used but often fails to meet user needs. To address this, we propose a novel solution combining semantic web mining with BP neural networks. We process user search logs to extract five key features: content priority, time spent, user feedback, recommendation semantics, and input deviation. These features are then fed into a BP neural network to classify and prioritize web pages. The prioritized pages are recommended to users. Using book sales pages for testing, our results demonstrate that this solution can quickly and accurately identify the pages users need. Our approach ensures that recommendations are more relevant and tailored to individual preferences, enhancing the online shopping experience. By leveraging advanced semantic analysis and neural network techniques, we bridge the gap between user expectations and actual recommendations. This innovative method not only improves accuracy but also speeds up the recommendation process, making it a valuable tool for e-commerce platforms aiming to boost user satisfaction and engagement. Additionally, our system ability to handle large datasets and provide real-time recommendations makes it a scalable and efficient solution for modern e-commerce challenges.
Read more9/14/2024
0
Learn by Selling: Equipping Large Language Models with Product Knowledge for Context-Driven Recommendations
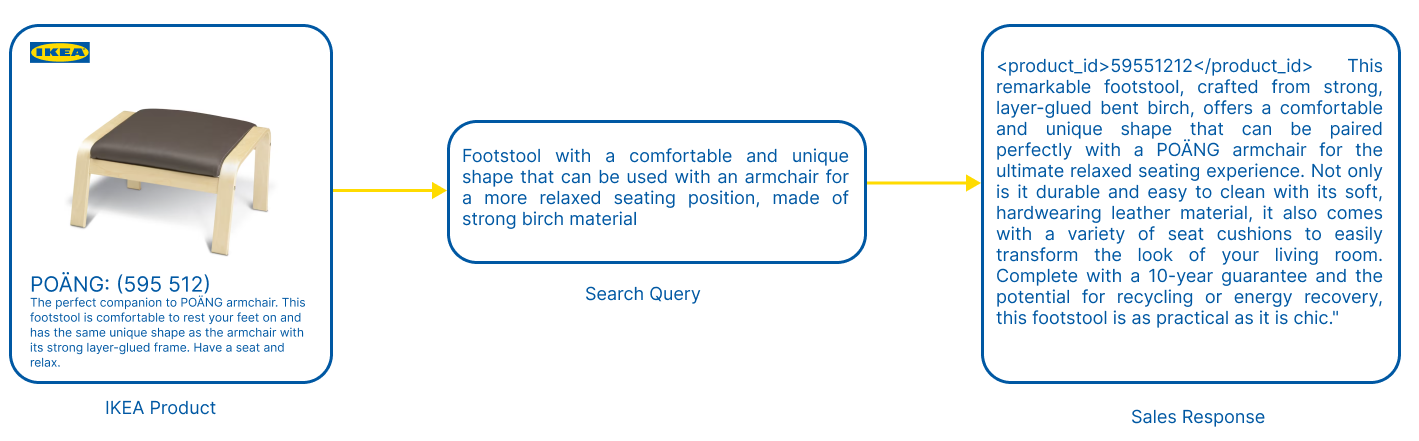
Sarthak Anand, Yutong Jiang, Giorgi Kokaia
The rapid evolution of large language models (LLMs) has opened up new possibilities for applications such as context-driven product recommendations. However, the effectiveness of these models in this context is heavily reliant on their comprehensive understanding of the product inventory. This paper presents a novel approach to equipping LLMs with product knowledge by training them to respond contextually to synthetic search queries that include product IDs. We delve into an extensive analysis of this method, evaluating its effectiveness, outlining its benefits, and highlighting its constraints. The paper also discusses the potential improvements and future directions for this approach, providing a comprehensive understanding of the role of LLMs in product recommendations.
Read more7/31/2024
0
Large Language Model Driven Recommendation
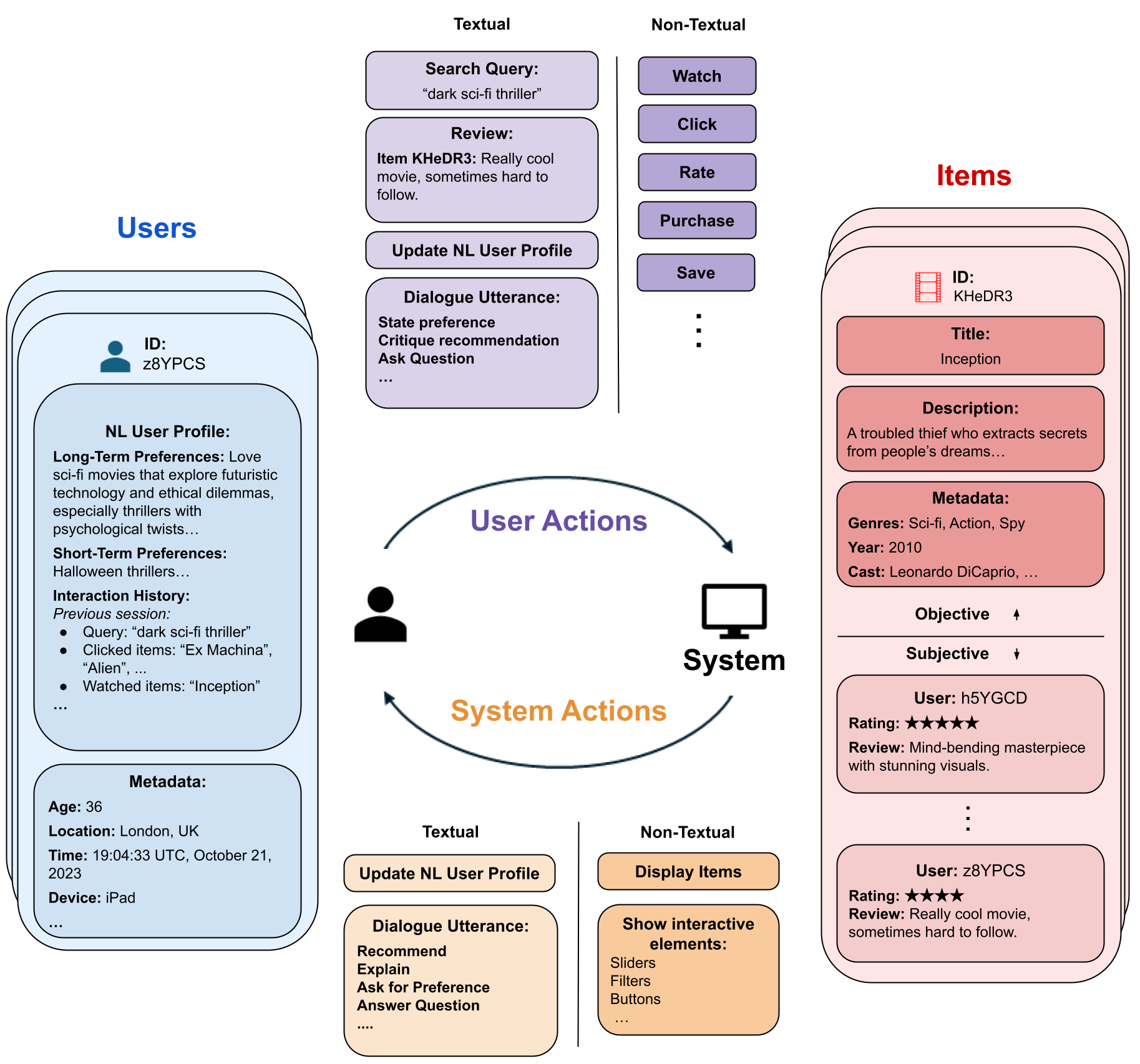
Anton Korikov, Scott Sanner, Yashar Deldjoo, Zhankui He, Julian McAuley, Arnau Ramisa, Rene Vidal, Mahesh Sathiamoorthy, Atoosa Kasrizadeh, Silvia Milano, Francesco Ricci
While previous chapters focused on recommendation systems (RSs) based on standardized, non-verbal user feedback such as purchases, views, and clicks -- the advent of LLMs has unlocked the use of natural language (NL) interactions for recommendation. This chapter discusses how LLMs' abilities for general NL reasoning present novel opportunities to build highly personalized RSs -- which can effectively connect nuanced and diverse user preferences to items, potentially via interactive dialogues. To begin this discussion, we first present a taxonomy of the key data sources for language-driven recommendation, covering item descriptions, user-system interactions, and user profiles. We then proceed to fundamental techniques for LLM recommendation, reviewing the use of encoder-only and autoregressive LLM recommendation in both tuned and untuned settings. Afterwards, we move to multi-module recommendation architectures in which LLMs interact with components such as retrievers and RSs in multi-stage pipelines. This brings us to architectures for conversational recommender systems (CRSs), in which LLMs facilitate multi-turn dialogues where each turn presents an opportunity not only to make recommendations, but also to engage with the user in interactive preference elicitation, critiquing, and question-answering.
Read more8/21/2024