Should We Fine-Tune or RAG? Evaluating Different Techniques to Adapt LLMs for Dialogue
2406.06399
0
0
Abstract
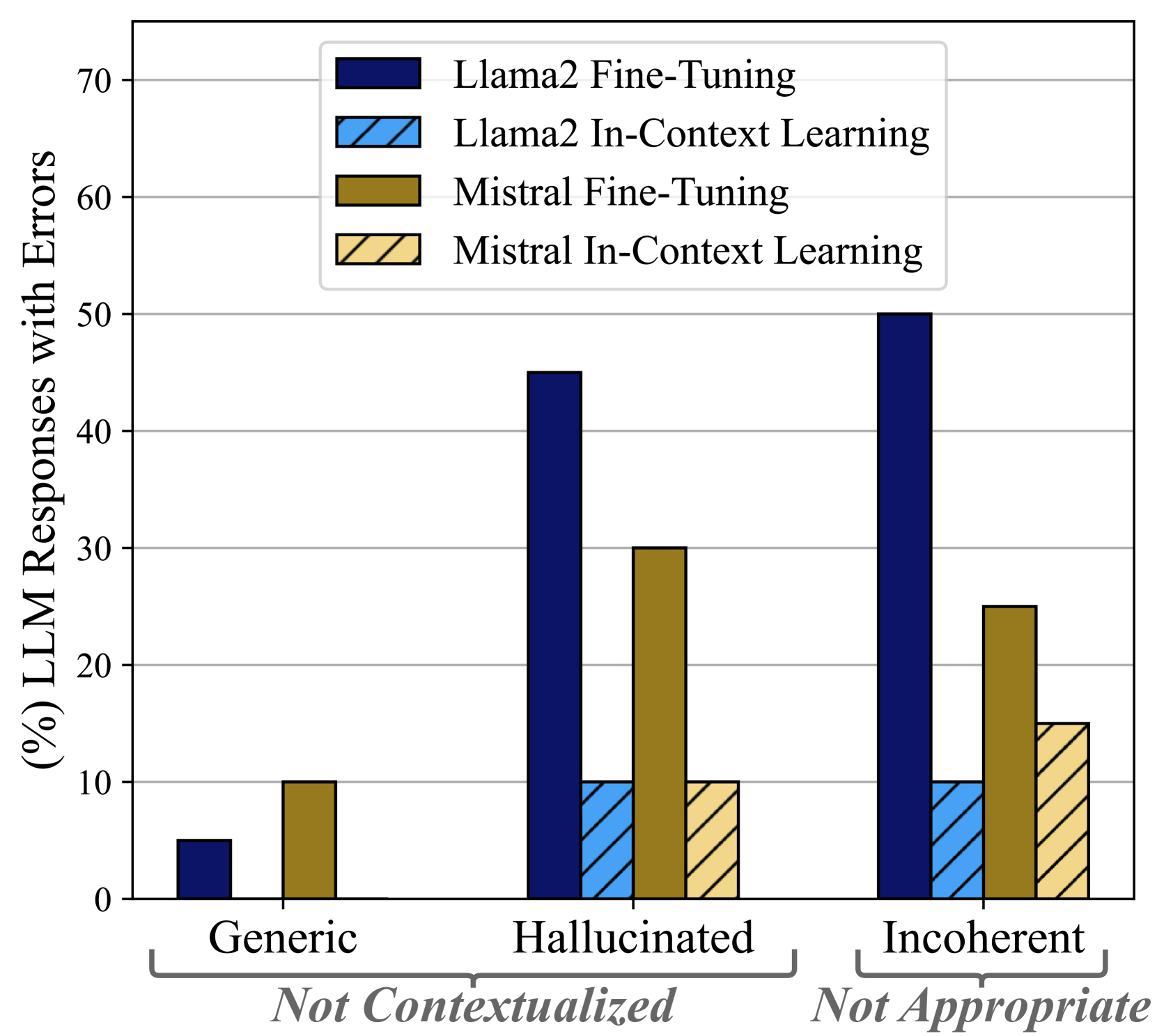
We study the limitations of Large Language Models (LLMs) for the task of response generation in human-machine dialogue. Several techniques have been proposed in the literature for different dialogue types (e.g., Open-Domain). However, the evaluations of these techniques have been limited in terms of base LLMs, dialogue types and evaluation metrics. In this work, we extensively analyze different LLM adaptation techniques when applied to different dialogue types. We have selected two base LLMs, Llama-2 and Mistral, and four dialogue types Open-Domain, Knowledge-Grounded, Task-Oriented, and Question Answering. We evaluate the performance of in-context learning and fine-tuning techniques across datasets selected for each dialogue type. We assess the impact of incorporating external knowledge to ground the generation in both scenarios of Retrieval-Augmented Generation (RAG) and gold knowledge. We adopt consistent evaluation and explainability criteria for automatic metrics and human evaluation protocols. Our analysis shows that there is no universal best-technique for adapting large language models as the efficacy of each technique depends on both the base LLM and the specific type of dialogue. Last but not least, the assessment of the best adaptation technique should include human evaluation to avoid false expectations and outcomes derived from automatic metrics.
Create account to get full access
Overview
- This paper explores different techniques for adapting large language models (LLMs) for dialogue tasks, comparing fine-tuning and retrieval-augmented generation (RAG).
- The researchers evaluate these approaches on several open-ended dialogue benchmarks to understand their strengths and weaknesses.
- The findings provide insights into how to effectively leverage LLMs for interactive conversational AI systems.
Plain English Explanation
The paper examines two main ways to adapt powerful language models, known as large language models (LLMs), so they can engage in open-ended conversations:
-
Fine-tuning: This involves taking an LLM and training it further on dialogue data to specialize its capabilities for conversation.
-
Retrieval-Augmented Generation (RAG): This approach combines an LLM with an information retrieval system, allowing the model to dynamically gather relevant information to include in its responses.
The researchers compare these two techniques by evaluating them on several benchmark datasets designed to test open-ended dialogue abilities. This allows them to understand the strengths and limitations of each approach and provide guidance on how to effectively use LLMs for building interactive conversational AI systems.
Technical Explanation
The paper explores two main techniques for adapting large language models (LLMs) for open-ended dialogue tasks:
-
Fine-Tuning: The researchers fine-tune GPT-3 on dialogue data to specialize the model for conversational abilities.
-
Retrieval-Augmented Generation (RAG): The team combines an LLM with a retrieval system, as in T-RAG, allowing the model to dynamically incorporate relevant information from an external knowledge source.
They evaluate these approaches on several open-ended dialogue benchmarks, including Empathetic Dialogues and Wizard of Wikipedia, to understand their strengths and limitations.
Critical Analysis
The paper provides a thorough evaluation of fine-tuning and RAG techniques for adapting LLMs for open-ended dialogue. However, the authors acknowledge several limitations:
- The experiments are primarily conducted on English language datasets, so the findings may not generalize well to other languages.
- The benchmarks used focus on specific types of dialogue, such as empathetic conversations or knowledge-grounded discussions. More diverse dialogue tasks should be explored.
- The RAG model used is a relatively simple implementation, and more advanced retrieval-augmented approaches, like those discussed in I Learn Better If You Speak My, could potentially yield better performance.
Further research is needed to fully understand the tradeoffs between fine-tuning and RAG for different dialogue use cases and to explore more sophisticated techniques for leveraging LLMs in conversational AI systems.
Conclusion
This paper provides a valuable comparison of fine-tuning and retrieval-augmented generation (RAG) as methods for adapting large language models (LLMs) for open-ended dialogue tasks. The findings offer insights into the strengths and limitations of each approach, informing the development of more effective conversational AI systems. While the research has some limitations, it represents an important step in understanding how to best utilize the capabilities of LLMs for interactive and contextual dialogue.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Fine-Tuning or Fine-Failing? Debunking Performance Myths in Large Language Models
Scott Barnett, Zac Brannelly, Stefanus Kurniawan, Sheng Wong
0
0
Large Language Models (LLMs) have the unique capability to understand and generate human-like text from input queries. When fine-tuned, these models show enhanced performance on domain-specific queries. OpenAI highlights the process of fine-tuning, stating: To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples, but the right number varies greatly based on the exact use case. This study extends this concept to the integration of LLMs within Retrieval-Augmented Generation (RAG) pipelines, which aim to improve accuracy and relevance by leveraging external corpus data for information retrieval. However, RAG's promise of delivering optimal responses often falls short in complex query scenarios. This study aims to specifically examine the effects of fine-tuning LLMs on their ability to extract and integrate contextual data to enhance the performance of RAG systems across multiple domains. We evaluate the impact of fine-tuning on the LLMs' capacity for data extraction and contextual understanding by comparing the accuracy and completeness of fine-tuned models against baseline performances across datasets from multiple domains. Our findings indicate that fine-tuning resulted in a decline in performance compared to the baseline models, contrary to the improvements observed in standalone LLM applications as suggested by OpenAI. This study highlights the need for vigorous investigation and validation of fine-tuned models for domain-specific tasks.
6/18/2024

Enhancing Q&A with Domain-Specific Fine-Tuning and Iterative Reasoning: A Comparative Study
Zooey Nguyen, Anthony Annunziata, Vinh Luong, Sang Dinh, Quynh Le, Anh Hai Ha, Chanh Le, Hong An Phan, Shruti Raghavan, Christopher Nguyen
0
0
This paper investigates the impact of domain-specific model fine-tuning and of reasoning mechanisms on the performance of question-answering (Q&A) systems powered by large language models (LLMs) and Retrieval-Augmented Generation (RAG). Using the FinanceBench SEC financial filings dataset, we observe that, for RAG, combining a fine-tuned embedding model with a fine-tuned LLM achieves better accuracy than generic models, with relatively greater gains attributable to fine-tuned embedding models. Additionally, employing reasoning iterations on top of RAG delivers an even bigger jump in performance, enabling the Q&A systems to get closer to human-expert quality. We discuss the implications of such findings, propose a structured technical design space capturing major technical components of Q&A AI, and provide recommendations for making high-impact technical choices for such components. We plan to follow up on this work with actionable guides for AI teams and further investigations into the impact of domain-specific augmentation in RAG and into agentic AI capabilities such as advanced planning and reasoning.
4/23/2024
↗️
T-RAG: Lessons from the LLM Trenches
Masoomali Fatehkia, Ji Kim Lucas, Sanjay Chawla
0
0
Large Language Models (LLM) have shown remarkable language capabilities fueling attempts to integrate them into applications across a wide range of domains. An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, limited computational resources and the need for a robust application that correctly responds to queries. Retrieval-Augmented Generation (RAG) has emerged as the most prominent framework for building LLM-based applications. While building a RAG is relatively straightforward, making it robust and a reliable application requires extensive customization and relatively deep knowledge of the application domain. We share our experiences building and deploying an LLM application for question answering over private organizational documents. Our application combines the use of RAG with a finetuned open-source LLM. Additionally, our system, which we call Tree-RAG (T-RAG), uses a tree structure to represent entity hierarchies within the organization. This is used to generate a textual description to augment the context when responding to user queries pertaining to entities within the organization's hierarchy. Our evaluations, including a Needle in a Haystack test, show that this combination performs better than a simple RAG or finetuning implementation. Finally, we share some lessons learned based on our experiences building an LLM application for real-world use.
6/7/2024
🏋️
Evaluating Students' Open-ended Written Responses with LLMs: Using the RAG Framework for GPT-3.5, GPT-4, Claude-3, and Mistral-Large
Jussi S. Jauhiainen, Agust'in Garagorry Guerra
0
0
Evaluating open-ended written examination responses from students is an essential yet time-intensive task for educators, requiring a high degree of effort, consistency, and precision. Recent developments in Large Language Models (LLMs) present a promising opportunity to balance the need for thorough evaluation with efficient use of educators' time. In our study, we explore the effectiveness of LLMs ChatGPT-3.5, ChatGPT-4, Claude-3, and Mistral-Large in assessing university students' open-ended answers to questions made about reference material they have studied. Each model was instructed to evaluate 54 answers repeatedly under two conditions: 10 times (10-shot) with a temperature setting of 0.0 and 10 times with a temperature of 0.5, expecting a total of 1,080 evaluations per model and 4,320 evaluations across all models. The RAG (Retrieval Augmented Generation) framework was used as the framework to make the LLMs to process the evaluation of the answers. As of spring 2024, our analysis revealed notable variations in consistency and the grading outcomes provided by studied LLMs. There is a need to comprehend strengths and weaknesses of LLMs in educational settings for evaluating open-ended written responses. Further comparative research is essential to determine the accuracy and cost-effectiveness of using LLMs for educational assessments.
5/10/2024