FinePseudo: Improving Pseudo-Labelling through Temporal-Alignablity for Semi-Supervised Fine-Grained Action Recognition

0

Sign in to get full access
Overview
- Proposes FinePseudo, a semi-supervised approach for fine-grained action recognition
- Leverages pseudo-labeling and temporal alignment to boost performance with limited labeled data
- Outperforms state-of-the-art semi-supervised methods on challenging fine-grained action datasets
Plain English Explanation
Fine-grained action recognition is the task of identifying very specific human actions, like 'brushing teeth' or 'pouring coffee', rather than just broad categories like 'walking' or 'jumping'. This is a challenging problem, especially when there is limited labeled training data available.
The FinePseudo method addresses this by using a semi-supervised approach. Instead of relying only on the scarce labeled data, it generates 'pseudo-labels' for the unlabeled samples using a trained model. However, these pseudo-labels can often be inaccurate.
To improve the quality of the pseudo-labels, FinePseudo introduces a novel 'temporal-alignability' concept. This aligns the predictions for each unlabeled sample with the ground truth labels of the labeled samples, ensuring the pseudo-labels better match the true action sequences.
By incorporating this temporal alignment, FinePseudo is able to generate higher quality pseudo-labels and use them effectively to boost the performance of the fine-grained action recognition model, even when only a small amount of labeled data is available.
Technical Explanation
The key technical components of FinePseudo are:
-
Pseudo-Labeling: The model is first trained on the limited labeled data. It then generates 'pseudo-labels' for the unlabeled samples by making predictions on them.
-
Temporal Alignment: To improve the quality of the pseudo-labels, FinePseudo aligns the predicted action sequences for each unlabeled sample with the ground truth labels of the labeled samples. This ensures the pseudo-labels better match the true temporal dynamics of the actions.
-
Semi-Supervised Training: The model is then fine-tuned using both the labeled data and the temporally-aligned pseudo-labeled data. This allows it to learn richer representations and make more accurate fine-grained action predictions.
The paper demonstrates the effectiveness of FinePseudo on several challenging fine-grained action recognition datasets, where it outperforms other state-of-the-art semi-supervised approaches.
Critical Analysis
The paper provides a thorough evaluation of FinePseudo and compares it to existing methods. However, a few potential limitations and areas for future work are worth noting:
- The temporal alignment process assumes the availability of some labeled samples with ground truth action sequences. In scenarios with even sparser labeled data, this assumption may not hold.
- The paper does not deeply investigate the impact of different pseudo-labeling strategies or the sensitivity of the method to the quality of the pseudo-labels.
- Extending FinePseudo to leverage additional modalities beyond just video, such as audio or text, could further improve performance on fine-grained action recognition.
Overall, FinePseudo presents a promising approach for boosting fine-grained action recognition with limited labeled data through the use of pseudo-labeling and temporal alignment.
Conclusion
The FinePseudo method addresses the challenge of fine-grained action recognition by leveraging semi-supervised learning. It generates high-quality pseudo-labels for unlabeled samples by aligning their predicted action sequences with the ground truth of labeled data. This allows FinePseudo to effectively utilize both labeled and unlabeled data to train a more accurate fine-grained action recognition model, outperforming state-of-the-art approaches. While there are some potential limitations, FinePseudo represents an important step forward in making fine-grained action recognition more practical and accessible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FinePseudo: Improving Pseudo-Labelling through Temporal-Alignablity for Semi-Supervised Fine-Grained Action Recognition
Ishan Rajendrakumar Dave, Mamshad Nayeem Rizve, Mubarak Shah
Real-life applications of action recognition often require a fine-grained understanding of subtle movements, e.g., in sports analytics, user interactions in AR/VR, and surgical videos. Although fine-grained actions are more costly to annotate, existing semi-supervised action recognition has mainly focused on coarse-grained action recognition. Since fine-grained actions are more challenging due to the absence of scene bias, classifying these actions requires an understanding of action-phases. Hence, existing coarse-grained semi-supervised methods do not work effectively. In this work, we for the first time thoroughly investigate semi-supervised fine-grained action recognition (FGAR). We observe that alignment distances like dynamic time warping (DTW) provide a suitable action-phase-aware measure for comparing fine-grained actions, a concept previously unexploited in FGAR. However, since regular DTW distance is pairwise and assumes strict alignment between pairs, it is not directly suitable for classifying fine-grained actions. To utilize such alignment distances in a limited-label setting, we propose an Alignability-Verification-based Metric learning technique to effectively discriminate between fine-grained action pairs. Our learnable alignability score provides a better phase-aware measure, which we use to refine the pseudo-labels of the primary video encoder. Our collaborative pseudo-labeling-based framework `textit{FinePseudo}' significantly outperforms prior methods on four fine-grained action recognition datasets: Diving48, FineGym99, FineGym288, and FineDiving, and shows improvement on existing coarse-grained datasets: Kinetics400 and Something-SomethingV2. We also demonstrate the robustness of our collaborative pseudo-labeling in handling novel unlabeled classes in open-world semi-supervised setups. Project Page: https://daveishan.github.io/finepsuedo-webpage/.
Read more9/4/2024

0
Towards Adaptive Pseudo-label Learning for Semi-Supervised Temporal Action Localization
Feixiang Zhou, Bryan Williams, Hossein Rahmani
Alleviating noisy pseudo labels remains a key challenge in Semi-Supervised Temporal Action Localization (SS-TAL). Existing methods often filter pseudo labels based on strict conditions, but they typically assess classification and localization quality separately, leading to suboptimal pseudo-label ranking and selection. In particular, there might be inaccurate pseudo labels within selected positives, alongside reliable counterparts erroneously assigned to negatives. To tackle these problems, we propose a novel Adaptive Pseudo-label Learning (APL) framework to facilitate better pseudo-label selection. Specifically, to improve the ranking quality, Adaptive Label Quality Assessment (ALQA) is proposed to jointly learn classification confidence and localization reliability, followed by dynamically selecting pseudo labels based on the joint score. Additionally, we propose an Instance-level Consistency Discriminator (ICD) for eliminating ambiguous positives and mining potential positives simultaneously based on inter-instance intrinsic consistency, thereby leading to a more precise selection. We further introduce a general unsupervised Action-aware Contrastive Pre-training (ACP) to enhance the discrimination both within actions and between actions and backgrounds, which benefits SS-TAL. Extensive experiments on THUMOS14 and ActivityNet v1.3 demonstrate that our method achieves state-of-the-art performance under various semi-supervised settings.
Read more7/26/2024
👁️
0
Fine-grained Knowledge Graph-driven Video-Language Learning for Action Recognition
Rui Zhang, Yafen Lu, Pengli Ji, Junxiao Xue, Xiaoran Yan
Recent work has explored video action recognition as a video-text matching problem and several effective methods have been proposed based on large-scale pre-trained vision-language models. However, these approaches primarily operate at a coarse-grained level without the detailed and semantic understanding of action concepts by exploiting fine-grained semantic connections between actions and body movements. To address this gap, we propose a contrastive video-language learning framework guided by a knowledge graph, termed KG-CLIP, which incorporates structured information into the CLIP model in the video domain. Specifically, we construct a multi-modal knowledge graph composed of multi-grained concepts by parsing actions based on compositional learning. By implementing a triplet encoder and deviation compensation to adaptively optimize the margin in the entity distance function, our model aims to improve alignment of entities in the knowledge graph to better suit complex relationship learning. This allows for enhanced video action recognition capabilities by accommodating nuanced associations between graph components. We comprehensively evaluate KG-CLIP on Kinetics-TPS, a large-scale action parsing dataset, demonstrating its effectiveness compared to competitive baselines. Especially, our method excels at action recognition with few sample frames or limited training data, which exhibits excellent data utilization and learning capabilities.
Read more7/22/2024
0
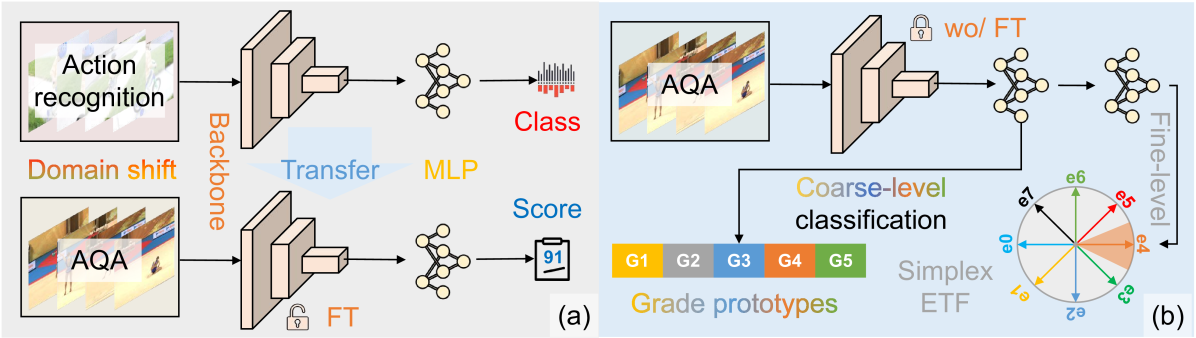
CoFInAl: Enhancing Action Quality Assessment with Coarse-to-Fine Instruction Alignment
Kanglei Zhou, Junlin Li, Ruizhi Cai, Liyuan Wang, Xingxing Zhang, Xiaohui Liang
Action Quality Assessment (AQA) is pivotal for quantifying actions across domains like sports and medical care. Existing methods often rely on pre-trained backbones from large-scale action recognition datasets to boost performance on smaller AQA datasets. However, this common strategy yields suboptimal results due to the inherent struggle of these backbones to capture the subtle cues essential for AQA. Moreover, fine-tuning on smaller datasets risks overfitting. To address these issues, we propose Coarse-to-Fine Instruction Alignment (CoFInAl). Inspired by recent advances in large language model tuning, CoFInAl aligns AQA with broader pre-trained tasks by reformulating it as a coarse-to-fine classification task. Initially, it learns grade prototypes for coarse assessment and then utilizes fixed sub-grade prototypes for fine-grained assessment. This hierarchical approach mirrors the judging process, enhancing interpretability within the AQA framework. Experimental results on two long-term AQA datasets demonstrate CoFInAl achieves state-of-the-art performance with significant correlation gains of 5.49% and 3.55% on Rhythmic Gymnastics and Fis-V, respectively. Our code is available at https://github.com/ZhouKanglei/CoFInAl_AQA.
Read more4/23/2024