CoFInAl: Enhancing Action Quality Assessment with Coarse-to-Fine Instruction Alignment

0
Sign in to get full access
Overview
- The paper introduces CoFInAl, a method for enhancing action quality assessment by aligning instructions with video frames in a coarse-to-fine manner.
- It builds on previous research on fine-grained action analysis and balancing speciality and versatility using a coarse-to-fine framework.
- The proposed approach aims to improve the assessment of the quality of actions performed in videos by closely aligning the instructions given to the performer with the observed video frames.
Plain English Explanation
The paper presents a new method called CoFInAl that can help assess the quality of actions performed in videos. The key idea is to carefully match the instructions given to the person performing the action with the actual video footage frame-by-frame.
Imagine you're learning a new dance move and you're following along with a video tutorial. The instructions might say "raise your right arm," and you want to make sure your movement matches that exactly. CoFInAl does this alignment in two stages - first it looks at the overall instructions and the video to get a rough sense of how well they match, and then it does a more fine-grained comparison to really nail down the details.
This is an important problem to solve because being able to accurately evaluate the quality of actions is crucial for things like training people on new skills, providing feedback, and even automating the assessment of complex tasks. By tightly coupling the instructions with the video, CoFInAl aims to provide a more reliable and insightful way to judge how well someone is performing a particular action.
Technical Explanation
The CoFInAl method operates in a coarse-to-fine manner to align instructions with video frames for enhanced action quality assessment. It builds on previous work on fine-grained action analysis and balancing speciality and versatility using a coarse-to-fine framework.
First, at a coarse level, CoFInAl aligns the high-level semantics of the instructions with the overall video content to get a rough sense of how well they match. This provides a global understanding of the correspondence between the instructions and the observed actions.
Then, at a finer level, CoFInAl performs a more detailed alignment, precisely matching the individual steps or components of the instructions with the relevant video frames. This allows for a more granular assessment of the quality of the performed actions.
By combining these coarse and fine-grained alignment stages, CoFInAl is able to provide a comprehensive and nuanced evaluation of how closely the executed actions align with the given instructions. This can help improve the accuracy and reliability of action quality assessment for applications such as skill training, feedback provision, and task automation.
Critical Analysis
The paper presents a compelling approach to enhancing action quality assessment, but there are a few aspects that could be further explored or addressed:
-
The authors acknowledge that the performance of CoFInAl may be sensitive to the quality and clarity of the provided instructions. Further research is needed to understand how the method handles ambiguous, incomplete, or potentially biased instructions.
-
The paper focuses on a specific dataset and task, so it would be valuable to evaluate the generalizability of CoFInAl across a wider range of action domains and instruction types. Extending the approach to long-form video datasets could also be an interesting direction for future work.
-
While the technical details of the CoFInAl architecture are well-explained, the paper could benefit from a more thorough discussion of the potential limitations and failure modes of the approach. Understanding these edge cases could inform future improvements and applications of the method.
-
The authors mention the potential for CoFInAl to enable automated assessment of complex tasks, but the paper does not delve into the practical implications or societal impacts of such technology. Careful consideration of ethical implications and potential misuse would be prudent.
Overall, the CoFInAl method presents a promising step forward in enhancing action quality assessment, but continued research and thoughtful consideration of its limitations and broader implications will be important as the field progresses.
Conclusion
The CoFInAl method introduced in this paper offers a novel approach to improving the assessment of action quality by closely aligning instructions with video frames in a coarse-to-fine manner. By combining global and local alignment, the technique can provide a more comprehensive and nuanced evaluation of how well performed actions match the given instructions.
This work builds on previous research on fine-grained action analysis and balancing speciality and versatility, and has the potential to enhance a variety of applications, such as skill training, feedback provision, and task automation. As the field continues to evolve, further exploration of the method's generalizability, limitations, and societal implications will be important to fully realize its benefits.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CoFInAl: Enhancing Action Quality Assessment with Coarse-to-Fine Instruction Alignment
Kanglei Zhou, Junlin Li, Ruizhi Cai, Liyuan Wang, Xingxing Zhang, Xiaohui Liang
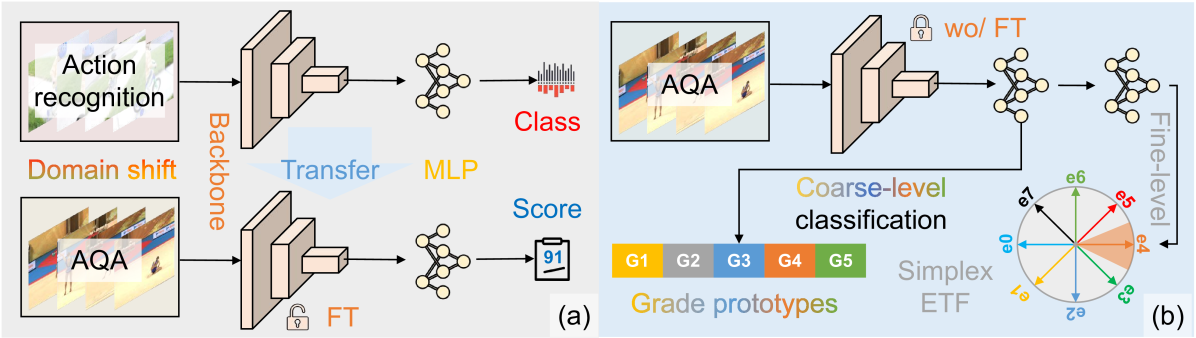
Action Quality Assessment (AQA) is pivotal for quantifying actions across domains like sports and medical care. Existing methods often rely on pre-trained backbones from large-scale action recognition datasets to boost performance on smaller AQA datasets. However, this common strategy yields suboptimal results due to the inherent struggle of these backbones to capture the subtle cues essential for AQA. Moreover, fine-tuning on smaller datasets risks overfitting. To address these issues, we propose Coarse-to-Fine Instruction Alignment (CoFInAl). Inspired by recent advances in large language model tuning, CoFInAl aligns AQA with broader pre-trained tasks by reformulating it as a coarse-to-fine classification task. Initially, it learns grade prototypes for coarse assessment and then utilizes fixed sub-grade prototypes for fine-grained assessment. This hierarchical approach mirrors the judging process, enhancing interpretability within the AQA framework. Experimental results on two long-term AQA datasets demonstrate CoFInAl achieves state-of-the-art performance with significant correlation gains of 5.49% and 3.55% on Rhythmic Gymnastics and Fis-V, respectively. Our code is available at https://github.com/ZhouKanglei/CoFInAl_AQA.
Read more4/23/2024
✨
0
Continual Action Assessment via Task-Consistent Score-Discriminative Feature Distribution Modeling
Yuan-Ming Li, Ling-An Zeng, Jing-Ke Meng, Wei-Shi Zheng
Action Quality Assessment (AQA) is a task that tries to answer how well an action is carried out. While remarkable progress has been achieved, existing works on AQA assume that all the training data are visible for training at one time, but do not enable continual learning on assessing new technical actions. In this work, we address such a Continual Learning problem in AQA (Continual-AQA), which urges a unified model to learn AQA tasks sequentially without forgetting. Our idea for modeling Continual-AQA is to sequentially learn a task-consistent score-discriminative feature distribution, in which the latent features express a strong correlation with the score labels regardless of the task or action types.From this perspective, we aim to mitigate the forgetting in Continual-AQA from two aspects. Firstly, to fuse the features of new and previous data into a score-discriminative distribution, a novel Feature-Score Correlation-Aware Rehearsal is proposed to store and reuse data from previous tasks with limited memory size. Secondly, an Action General-Specific Graph is developed to learn and decouple the action-general and action-specific knowledge so that the task-consistent score-discriminative features can be better extracted across various tasks. Extensive experiments are conducted to evaluate the contributions of proposed components. The comparisons with the existing continual learning methods additionally verify the effectiveness and versatility of our approach. Data and code are available at https://github.com/iSEE-Laboratory/Continual-AQA.
Read more5/3/2024
0
FineParser: A Fine-grained Spatio-temporal Action Parser for Human-centric Action Quality Assessment
Jinglin Xu, Sibo Yin, Guohao Zhao, Zishuo Wang, Yuxin Peng
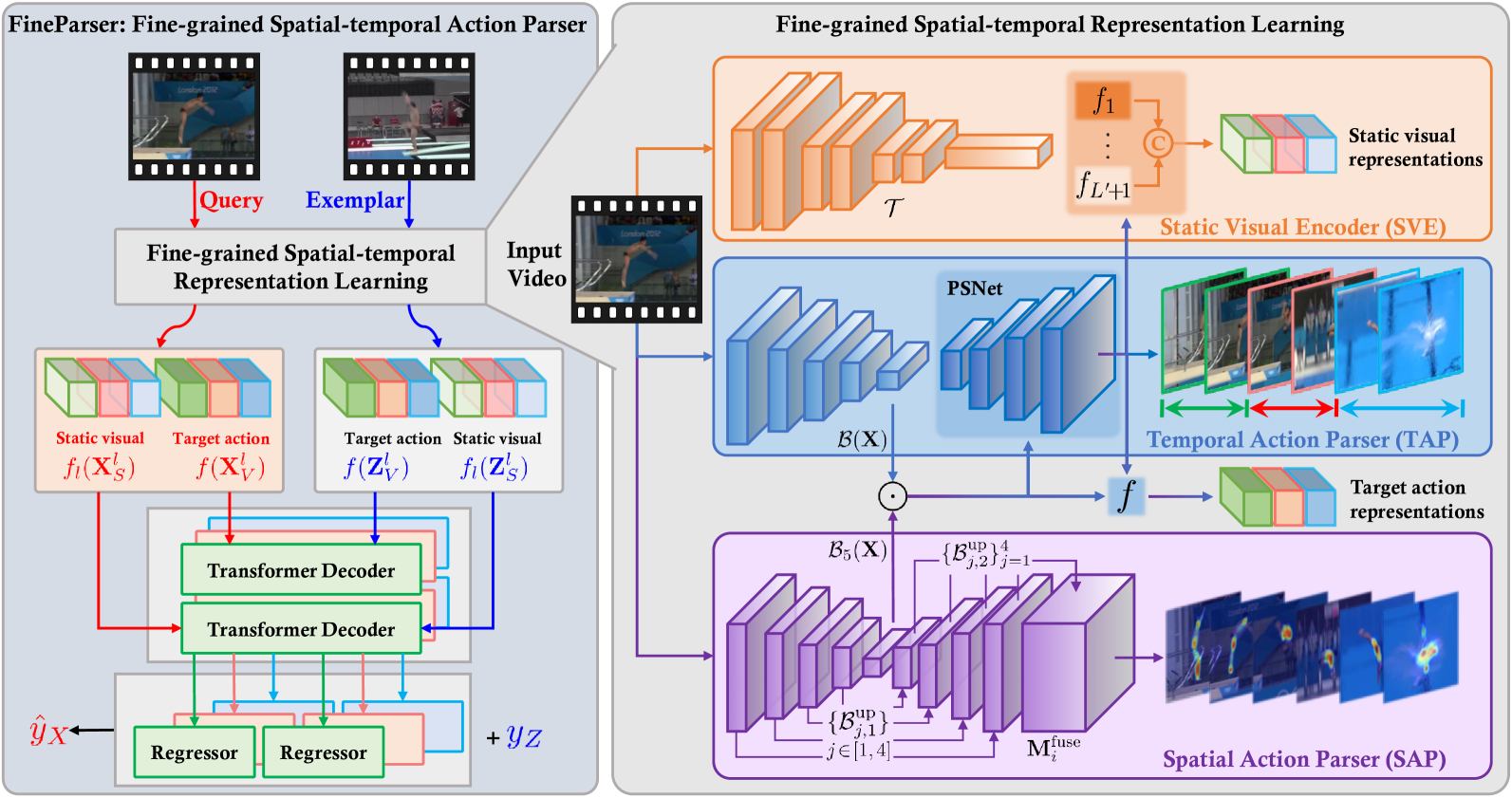
Existing action quality assessment (AQA) methods mainly learn deep representations at the video level for scoring diverse actions. Due to the lack of a fine-grained understanding of actions in videos, they harshly suffer from low credibility and interpretability, thus insufficient for stringent applications, such as Olympic diving events. We argue that a fine-grained understanding of actions requires the model to perceive and parse actions in both time and space, which is also the key to the credibility and interpretability of the AQA technique. Based on this insight, we propose a new fine-grained spatial-temporal action parser named textbf{FineParser}. It learns human-centric foreground action representations by focusing on target action regions within each frame and exploiting their fine-grained alignments in time and space to minimize the impact of invalid backgrounds during the assessment. In addition, we construct fine-grained annotations of human-centric foreground action masks for the FineDiving dataset, called textbf{FineDiving-HM}. With refined annotations on diverse target action procedures, FineDiving-HM can promote the development of real-world AQA systems. Through extensive experiments, we demonstrate the effectiveness of FineParser, which outperforms state-of-the-art methods while supporting more tasks of fine-grained action understanding. Data and code are available at url{https://github.com/PKU-ICST-MIPL/FineParser_CVPR2024}.
Read more5/14/2024

0
Interpretable Long-term Action Quality Assessment
Xu Dong, Xinran Liu, Wanqing Li, Anthony Adeyemi-Ejeye, Andrew Gilbert
Long-term Action Quality Assessment (AQA) evaluates the execution of activities in videos. However, the length presents challenges in fine-grained interpretability, with current AQA methods typically producing a single score by averaging clip features, lacking detailed semantic meanings of individual clips. Long-term videos pose additional difficulty due to the complexity and diversity of actions, exacerbating interpretability challenges. While query-based transformer networks offer promising long-term modeling capabilities, their interpretability in AQA remains unsatisfactory due to a phenomenon we term Temporal Skipping, where the model skips self-attention layers to prevent output degradation. To address this, we propose an attention loss function and a query initialization method to enhance performance and interpretability. Additionally, we introduce a weight-score regression module designed to approximate the scoring patterns observed in human judgments and replace conventional single-score regression, improving the rationality of interpretability. Our approach achieves state-of-the-art results on three real-world, long-term AQA benchmarks. Our code is available at: https://github.com/dx199771/Interpretability-AQA
Read more8/22/2024