FinTextQA: A Dataset for Long-form Financial Question Answering
2405.09980
0
0

Abstract
Accurate evaluation of financial question answering (QA) systems necessitates a comprehensive dataset encompassing diverse question types and contexts. However, current financial QA datasets lack scope diversity and question complexity. This work introduces FinTextQA, a novel dataset for long-form question answering (LFQA) in finance. FinTextQA comprises 1,262 high-quality, source-attributed QA pairs extracted and selected from finance textbooks and government agency websites.Moreover, we developed a Retrieval-Augmented Generation (RAG)-based LFQA system, comprising an embedder, retriever, reranker, and generator. A multi-faceted evaluation approach, including human ranking, automatic metrics, and GPT-4 scoring, was employed to benchmark the performance of different LFQA system configurations under heightened noisy conditions. The results indicate that: (1) Among all compared generators, Baichuan2-7B competes closely with GPT-3.5-turbo in accuracy score; (2) The most effective system configuration on our dataset involved setting the embedder, retriever, reranker, and generator as Ada2, Automated Merged Retrieval, Bge-Reranker-Base, and Baichuan2-7B, respectively; (3) models are less susceptible to noise after the length of contexts reaching a specific threshold.
Create account to get full access
Overview
• This paper introduces FinTextQA, a new dataset for long-form financial question answering. • The dataset consists of over 4,000 real-world financial questions and their corresponding answers, which are extracted from financial reports and other long-form text. • The authors present baseline models for the task of answering these financial questions, demonstrating the challenges and opportunities in this domain.
Plain English Explanation
The researchers have created a new dataset called FinTextQA that is designed to help computers better understand and answer questions about financial information. The dataset includes thousands of real questions that people might ask about financial topics, along with the correct answers to those questions. These questions and answers were extracted from long financial documents, such as reports and articles.
The goal is to develop machine learning models that can read through financial texts and then accurately answer questions about the information in those texts. This could be very useful for tasks like automated financial analysis or question-answering chatbots that help people understand complex financial topics.
The researchers provide some initial baseline models as a starting point, but they acknowledge that accurately answering long-form financial questions is a significant challenge that will require further research and innovation.
Technical Explanation
The FinTextQA dataset consists of over 4,000 real-world financial questions and their corresponding answers, extracted from a variety of long-form financial texts such as earnings reports, analyst reports, and news articles. The questions cover a wide range of financial topics, including accounting, investing, corporate finance, and macroeconomics.
To create the dataset, the authors used a combination of crowdsourcing and automated techniques to identify relevant questions and answers within the source texts. They then manually validated the quality of the question-answer pairs to ensure they were accurate and relevant.
The authors provide several baseline models for the task of answering the FinTextQA questions, including retrieval-based and generative approaches. These models leverage large language models and financial domain knowledge to generate relevant answers.
The results show that while the baseline models can achieve reasonable performance, there is significant room for improvement, particularly on questions that require deep reasoning about financial concepts and principles. The authors suggest that multimodal approaches and specialized financial question-answering architectures may be promising directions for future research.
Critical Analysis
The FinTextQA dataset represents an important step forward in the field of financial natural language processing. By providing a large, high-quality dataset of real-world financial questions and answers, the authors have created a valuable resource for researchers and developers working on applications in this domain.
However, the paper also acknowledges several limitations and challenges. The dataset is limited to English-language texts, and the authors note that extending it to other languages would be an important area for future work. Additionally, the questions and answers in the dataset may not fully capture the nuance and complexity of real-world financial decision-making, which often involves qualitative factors and contextual knowledge that may be difficult to encode in a dataset.
The baseline models presented in the paper also have room for improvement. While they demonstrate the feasibility of applying large language models and retrieval-based techniques to financial question answering, their performance is still relatively low compared to human-level understanding. Developing more sophisticated specialized architectures and incorporating multimodal inputs may be necessary to achieve significant breakthroughs in this domain.
Overall, the FinTextQA dataset and the associated baseline models represent an important contribution to the field of financial natural language processing. However, the challenges inherent in accurately answering long-form financial questions suggest that continued research and innovation will be necessary to realize the full potential of AI-powered financial assistants and analytical tools.
Conclusion
The FinTextQA dataset introduces a new benchmark for long-form financial question answering, providing researchers with a valuable resource for developing more advanced natural language processing models in this domain. While the baseline models presented in the paper demonstrate the feasibility of applying existing techniques to this task, the results also highlight the significant challenges involved in accurately answering complex financial questions.
Addressing these challenges will likely require a combination of specialized architectures, multimodal inputs, and deeper financial reasoning capabilities. As such, the FinTextQA dataset represents an important stepping stone towards the development of more sophisticated AI-powered financial analysis and decision-support tools that can truly understand and reason about the nuances of the financial world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SEC-QA: A Systematic Evaluation Corpus for Financial QA
Viet Dac Lai, Michael Krumdick, Charles Lovering, Varshini Reddy, Craig Schmidt, Chris Tanner
0
0
The financial domain frequently deals with large numbers of long documents that are essential for daily operations. Significant effort is put towards automating financial data analysis. However, a persistent challenge, not limited to the finance domain, is the scarcity of datasets that accurately reflect real-world tasks for model evaluation. Existing datasets are often constrained by size, context, or relevance to practical applications. Moreover, LLMs are currently trained on trillions of tokens of text, limiting access to novel data or documents that models have not encountered during training for unbiased evaluation. We propose SEC-QA, a continuous dataset generation framework with two key features: 1) the semi-automatic generation of Question-Answer (QA) pairs spanning multiple long context financial documents, which better represent real-world financial scenarios; 2) the ability to continually refresh the dataset using the most recent public document collections, not yet ingested by LLMs. Our experiments show that current retrieval augmented generation methods systematically fail to answer these challenging multi-document questions. In response, we introduce a QA system based on program-of-thought that improves the ability to perform complex information retrieval and quantitative reasoning pipelines, thereby increasing QA accuracy.
6/21/2024

FinTruthQA: A Benchmark Dataset for Evaluating the Quality of Financial Information Disclosure
Ziyue Xu, Peilin Zhou, Xinyu Shi, Jiageng Wu, Yikang Jiang, Bin Ke, Jie Yang
0
0
Accurate and transparent financial information disclosure is crucial in the fields of accounting and finance, ensuring market efficiency and investor confidence. Among many information disclosure platforms, the Chinese stock exchanges' investor interactive platform provides a novel and interactive way for listed firms to disclose information of interest to investors through an online question-and-answer (Q&A) format. However, it is common for listed firms to respond to questions with limited or no substantive information, and automatically evaluating the quality of financial information disclosure on large amounts of Q&A pairs is challenging. This paper builds a benchmark FinTruthQA, that can evaluate advanced natural language processing (NLP) techniques for the automatic quality assessment of information disclosure in financial Q&A data. FinTruthQA comprises 6,000 real-world financial Q&A entries and each Q&A was manually annotated based on four conceptual dimensions of accounting. We benchmarked various NLP techniques on FinTruthQA, including statistical machine learning models, pre-trained language model and their fine-tuned versions, as well as the large language model GPT-4. Experiments showed that existing NLP models have strong predictive ability for real question identification and question relevance tasks, but are suboptimal for answer relevance and answer readability tasks. By establishing this benchmark, we provide a robust foundation for the automatic evaluation of information disclosure, significantly enhancing the transparency and quality of financial reporting. FinTruthQA can be used by auditors, regulators, and financial analysts for real-time monitoring and data-driven decision-making, as well as by researchers for advanced studies in accounting and finance, ultimately fostering greater trust and efficiency in the financial markets.
6/19/2024
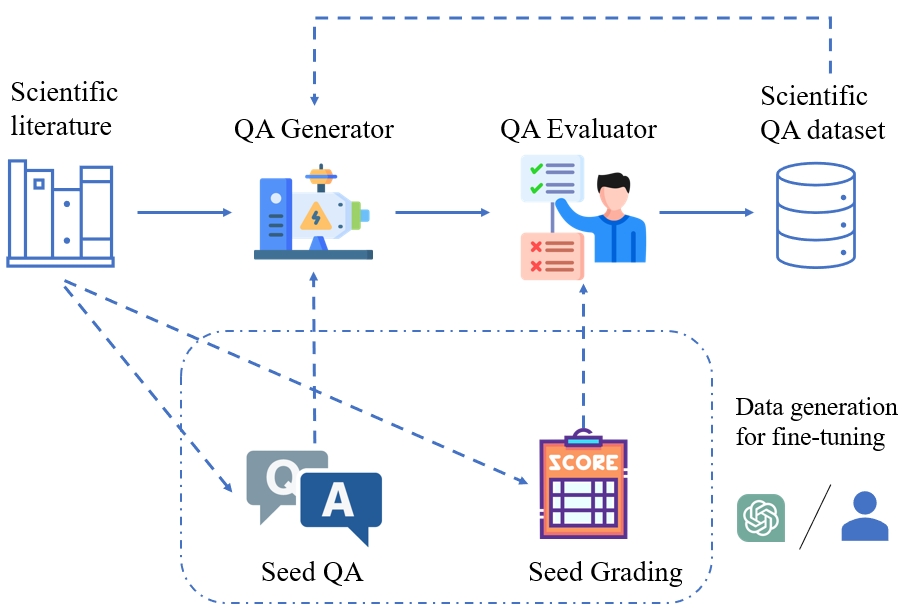
SciQAG: A Framework for Auto-Generated Scientific Question Answering Dataset with Fine-grained Evaluation
Yuwei Wan, Aswathy Ajith, Yixuan Liu, Ke Lu, Clara Grazian, Bram Hoex, Wenjie Zhang, Chunyu Kit, Tong Xie, Ian Foster
0
0
The use of question-answer (QA) pairs for training and evaluating large language models (LLMs) has attracted considerable attention. Yet few available QA datasets are based on knowledge from the scientific literature. Here we bridge this gap by presenting Automatic Generation of Scientific Question Answers (SciQAG), a framework for automatic generation and evaluation of scientific QA pairs sourced from published scientific literature. We fine-tune an open-source LLM to generate num{960000} scientific QA pairs from full-text scientific papers and propose a five-dimensional metric to evaluate the quality of the generated QA pairs. We show via LLM-based evaluation that the generated QA pairs consistently achieve an average score of 2.5 out of 3 across five dimensions, indicating that our framework can distill key knowledge from papers into high-quality QA pairs at scale. We make the dataset, models, and evaluation codes publicly available.
5/17/2024
💬
LibriSQA: A Novel Dataset and Framework for Spoken Question Answering with Large Language Models
Zihan Zhao, Yiyang Jiang, Heyang Liu, Yanfeng Wang, Yu Wang
0
0
While Large Language Models (LLMs) have demonstrated commendable performance across a myriad of domains and tasks, existing LLMs still exhibit a palpable deficit in handling multimodal functionalities, especially for the Spoken Question Answering (SQA) task which necessitates precise alignment and deep interaction between speech and text features. To address the SQA challenge on LLMs, we initially curated the free-form and open-ended LibriSQA dataset from Librispeech, comprising Part I with natural conversational formats and Part II encompassing multiple-choice questions followed by answers and analytical segments. Both parts collectively include 107k SQA pairs that cover various topics. Given the evident paucity of existing speech-text LLMs, we propose a lightweight, end-to-end framework to execute the SQA task on the LibriSQA, witnessing significant results. By reforming ASR into the SQA format, we further substantiate our framework's capability in handling ASR tasks. Our empirical findings bolster the LLMs' aptitude for aligning and comprehending multimodal information, paving the way for the development of universal multimodal LLMs. The dataset and demo can be found at https://github.com/ZihanZhaoSJTU/LibriSQA.
4/19/2024