SEC-QA: A Systematic Evaluation Corpus for Financial QA
2406.14394
0
0

Abstract
The financial domain frequently deals with large numbers of long documents that are essential for daily operations. Significant effort is put towards automating financial data analysis. However, a persistent challenge, not limited to the finance domain, is the scarcity of datasets that accurately reflect real-world tasks for model evaluation. Existing datasets are often constrained by size, context, or relevance to practical applications. Moreover, LLMs are currently trained on trillions of tokens of text, limiting access to novel data or documents that models have not encountered during training for unbiased evaluation. We propose SEC-QA, a continuous dataset generation framework with two key features: 1) the semi-automatic generation of Question-Answer (QA) pairs spanning multiple long context financial documents, which better represent real-world financial scenarios; 2) the ability to continually refresh the dataset using the most recent public document collections, not yet ingested by LLMs. Our experiments show that current retrieval augmented generation methods systematically fail to answer these challenging multi-document questions. In response, we introduce a QA system based on program-of-thought that improves the ability to perform complex information retrieval and quantitative reasoning pipelines, thereby increasing QA accuracy.
Create account to get full access
Overview
- This paper introduces SEC-QA, a new dataset for evaluating financial question answering systems.
- SEC-QA contains over 10,000 questions and answers based on U.S. Securities and Exchange Commission (SEC) filings.
- The dataset covers a wide range of financial topics and is designed to serve as a benchmark for assessing the performance of financial QA models.
Plain English Explanation
The researchers behind this paper have created a new dataset called SEC-QA to help evaluate and improve financial question-answering systems. Financial QA systems are computer programs that can answer questions about financial topics, like stocks, earnings reports, and regulations.
SEC-QA contains over 10,000 sample questions and answers based on real financial documents filed with the U.S. Securities and Exchange Commission (SEC). These documents, called SEC filings, provide important information about public companies. The questions in SEC-QA cover a wide range of financial concepts, from basic accounting to complex investment strategies.
By providing this standardized dataset, the researchers aim to give researchers and developers a way to systematically test how well their financial QA systems perform. This will help drive progress in automating financial question answering and make it easier for people to get reliable answers to their financial questions.
Technical Explanation
The SEC-QA dataset was constructed by first collecting a corpus of SEC filings, including annual reports (10-Ks), quarterly reports (10-Qs), and other regulatory documents. The researchers then used a combination of automated and manual techniques to generate relevant questions and answers from the content of these filings.
To do this, they leveraged prior work on question generation and financial text understanding. This included using techniques like named entity recognition, relation extraction, and question generation models to systematically extract salient information from the SEC filings and formulate corresponding questions.
The resulting SEC-QA dataset contains over 10,000 question-answer pairs spanning a wide range of financial topics, such as accounting, investing, corporate governance, and regulatory compliance. The researchers evaluated the quality of the dataset through human assessment and benchmarked several baseline QA models on the task.
Critical Analysis
The creation of SEC-QA represents an important advancement in financial text QA research. By providing a large-scale, high-quality dataset focused specifically on financial topics, the researchers have given the community a valuable tool for developing and evaluating financial QA systems.
One potential limitation of the dataset is the reliance on SEC filings as the sole source of content. While these documents are a rich source of financial information, they may not fully capture the breadth of questions and information needs that users have in real-world financial contexts. Expanding the dataset to include other types of financial texts, such as news articles or social media posts, could help broaden its applicability.
Additionally, the dataset focuses primarily on written, text-based questions and answers. Incorporating spoken question answering capabilities could make financial QA systems more accessible and user-friendly for a wider audience.
Overall, SEC-QA represents a valuable contribution to the field of financial text understanding and question answering. As the dataset is further refined and expanded, it has the potential to drive significant progress in automating financial information retrieval and analysis.
Conclusion
The SEC-QA dataset introduced in this paper provides a comprehensive, high-quality benchmark for evaluating financial question answering systems. By drawing on a large corpus of SEC filings, the dataset covers a wide range of financial topics and concepts, making it a valuable resource for researchers and developers working to advance the state of the art in this important domain.
While the dataset has some limitations, such as its exclusive focus on SEC filings, it represents a significant step forward in the quest to develop more intelligent and user-friendly financial information retrieval systems. As these technologies continue to evolve, resources like SEC-QA will be crucial in guiding their development and ensuring they meet the needs of investors, regulators, and the general public.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

FinTextQA: A Dataset for Long-form Financial Question Answering
Jian Chen, Peilin Zhou, Yining Hua, Yingxin Loh, Kehui Chen, Ziyuan Li, Bing Zhu, Junwei Liang
0
0
Accurate evaluation of financial question answering (QA) systems necessitates a comprehensive dataset encompassing diverse question types and contexts. However, current financial QA datasets lack scope diversity and question complexity. This work introduces FinTextQA, a novel dataset for long-form question answering (LFQA) in finance. FinTextQA comprises 1,262 high-quality, source-attributed QA pairs extracted and selected from finance textbooks and government agency websites.Moreover, we developed a Retrieval-Augmented Generation (RAG)-based LFQA system, comprising an embedder, retriever, reranker, and generator. A multi-faceted evaluation approach, including human ranking, automatic metrics, and GPT-4 scoring, was employed to benchmark the performance of different LFQA system configurations under heightened noisy conditions. The results indicate that: (1) Among all compared generators, Baichuan2-7B competes closely with GPT-3.5-turbo in accuracy score; (2) The most effective system configuration on our dataset involved setting the embedder, retriever, reranker, and generator as Ada2, Automated Merged Retrieval, Bge-Reranker-Base, and Baichuan2-7B, respectively; (3) models are less susceptible to noise after the length of contexts reaching a specific threshold.
5/17/2024
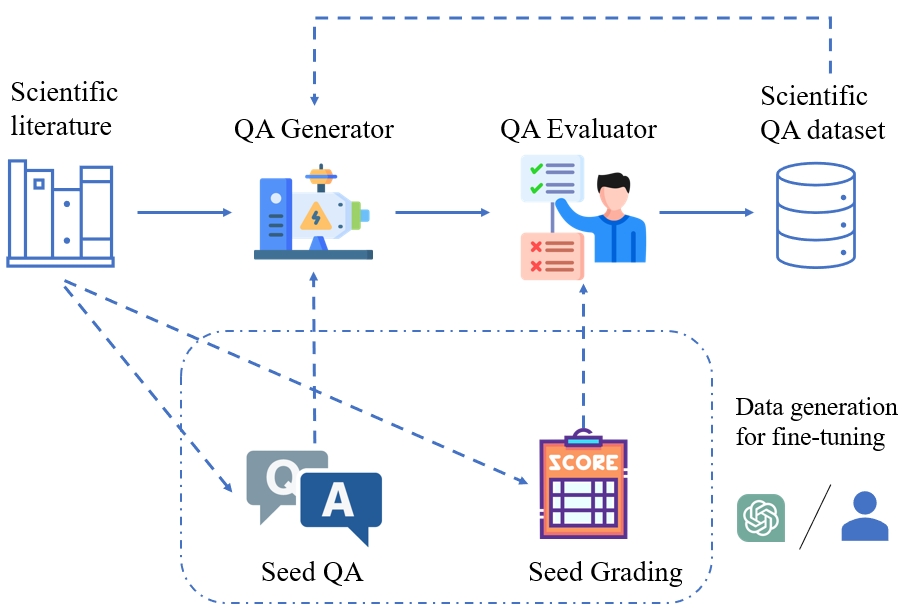
SciQAG: A Framework for Auto-Generated Scientific Question Answering Dataset with Fine-grained Evaluation
Yuwei Wan, Aswathy Ajith, Yixuan Liu, Ke Lu, Clara Grazian, Bram Hoex, Wenjie Zhang, Chunyu Kit, Tong Xie, Ian Foster
0
0
The use of question-answer (QA) pairs for training and evaluating large language models (LLMs) has attracted considerable attention. Yet few available QA datasets are based on knowledge from the scientific literature. Here we bridge this gap by presenting Automatic Generation of Scientific Question Answers (SciQAG), a framework for automatic generation and evaluation of scientific QA pairs sourced from published scientific literature. We fine-tune an open-source LLM to generate num{960000} scientific QA pairs from full-text scientific papers and propose a five-dimensional metric to evaluate the quality of the generated QA pairs. We show via LLM-based evaluation that the generated QA pairs consistently achieve an average score of 2.5 out of 3 across five dimensions, indicating that our framework can distill key knowledge from papers into high-quality QA pairs at scale. We make the dataset, models, and evaluation codes publicly available.
5/17/2024
🛸
Long-Span Question-Answering: Automatic Question Generation and QA-System Ranking via Side-by-Side Evaluation
Bernd Bohnet, Kevin Swersky, Rosanne Liu, Pranjal Awasthi, Azade Nova, Javier Snaider, Hanie Sedghi, Aaron T Parisi, Michael Collins, Angeliki Lazaridou, Orhan Firat, Noah Fiedel
0
0
We explore the use of long-context capabilities in large language models to create synthetic reading comprehension data from entire books. Previous efforts to construct such datasets relied on crowd-sourcing, but the emergence of transformers with a context size of 1 million or more tokens now enables entirely automatic approaches. Our objective is to test the capabilities of LLMs to analyze, understand, and reason over problems that require a detailed comprehension of long spans of text, such as questions involving character arcs, broader themes, or the consequences of early actions later in the story. We propose a holistic pipeline for automatic data generation including question generation, answering, and model scoring using an ``Evaluator''. We find that a relative approach, comparing answers between models in a pairwise fashion and ranking with a Bradley-Terry model, provides a more consistent and differentiating scoring mechanism than an absolute scorer that rates answers individually. We also show that LLMs from different model families produce moderate agreement in their ratings. We ground our approach using the manually curated NarrativeQA dataset, where our evaluator shows excellent agreement with human judgement and even finds errors in the dataset. Using our automatic evaluation approach, we show that using an entire book as context produces superior reading comprehension performance compared to baseline no-context (parametric knowledge only) and retrieval-based approaches.
6/4/2024

FinTruthQA: A Benchmark Dataset for Evaluating the Quality of Financial Information Disclosure
Ziyue Xu, Peilin Zhou, Xinyu Shi, Jiageng Wu, Yikang Jiang, Bin Ke, Jie Yang
0
0
Accurate and transparent financial information disclosure is crucial in the fields of accounting and finance, ensuring market efficiency and investor confidence. Among many information disclosure platforms, the Chinese stock exchanges' investor interactive platform provides a novel and interactive way for listed firms to disclose information of interest to investors through an online question-and-answer (Q&A) format. However, it is common for listed firms to respond to questions with limited or no substantive information, and automatically evaluating the quality of financial information disclosure on large amounts of Q&A pairs is challenging. This paper builds a benchmark FinTruthQA, that can evaluate advanced natural language processing (NLP) techniques for the automatic quality assessment of information disclosure in financial Q&A data. FinTruthQA comprises 6,000 real-world financial Q&A entries and each Q&A was manually annotated based on four conceptual dimensions of accounting. We benchmarked various NLP techniques on FinTruthQA, including statistical machine learning models, pre-trained language model and their fine-tuned versions, as well as the large language model GPT-4. Experiments showed that existing NLP models have strong predictive ability for real question identification and question relevance tasks, but are suboptimal for answer relevance and answer readability tasks. By establishing this benchmark, we provide a robust foundation for the automatic evaluation of information disclosure, significantly enhancing the transparency and quality of financial reporting. FinTruthQA can be used by auditors, regulators, and financial analysts for real-time monitoring and data-driven decision-making, as well as by researchers for advanced studies in accounting and finance, ultimately fostering greater trust and efficiency in the financial markets.
6/19/2024