Fixed Design Analysis of Regularization-Based Continual Learning
2303.10263
0
0
✨
Abstract
We consider a continual learning (CL) problem with two linear regression tasks in the fixed design setting, where the feature vectors are assumed fixed and the labels are assumed to be random variables. We consider an $ell_2$-regularized CL algorithm, which computes an Ordinary Least Squares parameter to fit the first dataset, then computes another parameter that fits the second dataset under an $ell_2$-regularization penalizing its deviation from the first parameter, and outputs the second parameter. For this algorithm, we provide tight bounds on the average risk over the two tasks. Our risk bounds reveal a provable trade-off between forgetting and intransigence of the $ell_2$-regularized CL algorithm: with a large regularization parameter, the algorithm output forgets less information about the first task but is intransigent to extract new information from the second task; and vice versa. Our results suggest that catastrophic forgetting could happen for CL with dissimilar tasks (under a precise similarity measurement) and that a well-tuned $ell_2$-regularization can partially mitigate this issue by introducing intransigence.
Create account to get full access
Overview
- This paper examines a continual learning (CL) problem with two linear regression tasks in a fixed design setting.
- The authors consider an ℓ2-regularized CL algorithm that computes an Ordinary Least Squares parameter to fit the first dataset, then computes another parameter that fits the second dataset under an ℓ2-regularization penalizing its deviation from the first parameter.
- The authors provide tight bounds on the average risk over the two tasks for this algorithm, revealing a trade-off between forgetting and intransigence.
Plain English Explanation
The paper explores a continual learning (CL) problem involving two linear regression tasks. In this setting, the feature vectors (inputs) are assumed to be fixed, while the labels (outputs) are random variables.
The authors consider a specific CL algorithm that uses ℓ2-regularization. This algorithm first computes a parameter that fits the first dataset using Ordinary Least Squares. It then computes another parameter for the second dataset, but this time it penalizes the deviation of the new parameter from the first one using ℓ2-regularization.
The key insight from the paper is that this ℓ2-regularized CL algorithm exhibits a trade-off between forgetting and intransigence. If the regularization parameter is large, the algorithm will forget less information about the first task, but it will also be less able to extract new information from the second task. Conversely, a smaller regularization parameter will allow the algorithm to learn more from the second task, but it will also be more prone to forgetting what it learned from the first task.
This trade-off suggests that catastrophic forgetting can happen when CL is applied to dissimilar tasks (as measured by a specific similarity metric). However, the authors show that a well-tuned ℓ2-regularization can partially mitigate this issue by introducing a degree of intransigence.
Technical Explanation
The paper analyzes an ℓ2-regularized CL algorithm in a fixed design linear regression setting. The algorithm first computes an Ordinary Least Squares parameter to fit the first dataset, then computes another parameter that fits the second dataset under an ℓ2-regularization penalty that discourages deviation from the first parameter.
The authors provide tight bounds on the average risk (a measure of performance) over the two tasks for this algorithm. These risk bounds reveal a fundamental trade-off between forgetting and intransigence. A larger regularization parameter leads to less forgetting of the first task but also less ability to extract new information from the second task. Conversely, a smaller regularization parameter allows for more learning from the second task but also more forgetting of the first task.
This trade-off suggests that catastrophic forgetting can occur when CL is applied to dissimilar tasks, as measured by a specific similarity metric. However, the authors show that a well-tuned ℓ2-regularization can partially mitigate this issue by introducing a degree of intransigence, preventing the algorithm from completely forgetting the first task.
The authors' results build on prior work in continual learning by spectral regularization and data-aware and parameter-aware robustness in continual learning.
Critical Analysis
The paper provides a thorough theoretical analysis of the ℓ2-regularized CL algorithm, but there are a few potential limitations and areas for further research:
-
The analysis is limited to the fixed design linear regression setting, and it's unclear how well the insights would translate to more complex machine learning tasks or settings with changing feature distributions.
-
The authors assume the feature vectors are fixed, which may not always be the case in real-world applications. Exploring CL algorithms that can handle changing feature distributions would be an interesting direction.
-
While the trade-off between forgetting and intransigence is well-characterized, the paper does not provide guidance on how to optimally tune the regularization parameter in practice. Further research into adaptive or dynamic regularization strategies could be beneficial.
-
The analysis focuses on average risk, but other performance metrics, such as task-specific performance or learning efficiency, may also be important considerations in continual learning.
Overall, the paper provides valuable theoretical insights into the behavior of ℓ2-regularized CL algorithms, but additional research is needed to understand the practical implications and applicability of these findings to more complex machine learning problems.
Conclusion
This paper presents a theoretical analysis of an ℓ2-regularized continual learning algorithm for linear regression tasks in a fixed design setting. The authors provide tight bounds on the average risk over the two tasks, revealing a fundamental trade-off between forgetting and intransigence.
The key insight is that while a larger regularization parameter can help mitigate catastrophic forgetting, it also makes the algorithm more resistant to extracting new information from the second task. Conversely, a smaller regularization parameter allows for more learning from the second task but also increased forgetting of the first task.
These findings suggest that careful tuning of the regularization parameter is crucial for balancing the conflicting goals of retaining knowledge from previous tasks and adapting to new information. The paper's theoretical analysis provides a solid foundation for further research into continual learning algorithms and their practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Statistical Theory of Regularization-Based Continual Learning
Xuyang Zhao, Huiyuan Wang, Weiran Huang, Wei Lin
0
0
We provide a statistical analysis of regularization-based continual learning on a sequence of linear regression tasks, with emphasis on how different regularization terms affect the model performance. We first derive the convergence rate for the oracle estimator obtained as if all data were available simultaneously. Next, we consider a family of generalized $ell_2$-regularization algorithms indexed by matrix-valued hyperparameters, which includes the minimum norm estimator and continual ridge regression as special cases. As more tasks are introduced, we derive an iterative update formula for the estimation error of generalized $ell_2$-regularized estimators, from which we determine the hyperparameters resulting in the optimal algorithm. Interestingly, the choice of hyperparameters can effectively balance the trade-off between forward and backward knowledge transfer and adjust for data heterogeneity. Moreover, the estimation error of the optimal algorithm is derived explicitly, which is of the same order as that of the oracle estimator. In contrast, our lower bounds for the minimum norm estimator and continual ridge regression show their suboptimality. A byproduct of our theoretical analysis is the equivalence between early stopping and generalized $ell_2$-regularization in continual learning, which may be of independent interest. Finally, we conduct experiments to complement our theory.
6/11/2024
Improving Data-aware and Parameter-aware Robustness for Continual Learning
Hanxi Xiao, Fan Lyu
0
0
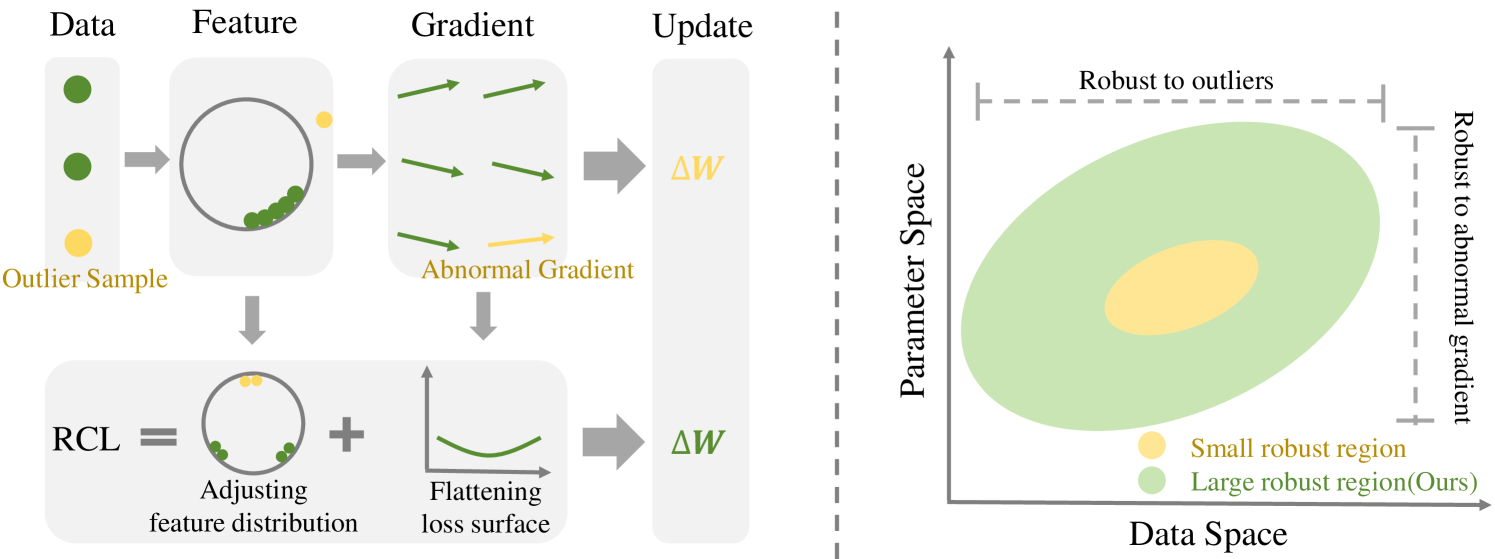
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
5/28/2024

Understanding Forgetting in Continual Learning with Linear Regression
Meng Ding, Kaiyi Ji, Di Wang, Jinhui Xu
0
0
Continual learning, focused on sequentially learning multiple tasks, has gained significant attention recently. Despite the tremendous progress made in the past, the theoretical understanding, especially factors contributing to catastrophic forgetting, remains relatively unexplored. In this paper, we provide a general theoretical analysis of forgetting in the linear regression model via Stochastic Gradient Descent (SGD) applicable to both underparameterized and overparameterized regimes. Our theoretical framework reveals some interesting insights into the intricate relationship between task sequence and algorithmic parameters, an aspect not fully captured in previous studies due to their restrictive assumptions. Specifically, we demonstrate that, given a sufficiently large data size, the arrangement of tasks in a sequence, where tasks with larger eigenvalues in their population data covariance matrices are trained later, tends to result in increased forgetting. Additionally, our findings highlight that an appropriate choice of step size will help mitigate forgetting in both underparameterized and overparameterized settings. To validate our theoretical analysis, we conducted simulation experiments on both linear regression models and Deep Neural Networks (DNNs). Results from these simulations substantiate our theoretical findings.
5/29/2024
Learning Continually by Spectral Regularization
Alex Lewandowski, Saurabh Kumar, Dale Schuurmans, Andr'as Gyorgy, Marlos C. Machado
0
0
Loss of plasticity is a phenomenon where neural networks become more difficult to train during the course of learning. Continual learning algorithms seek to mitigate this effect by sustaining good predictive performance while maintaining network trainability. We develop new techniques for improving continual learning by first reconsidering how initialization can ensure trainability during early phases of learning. From this perspective, we derive new regularization strategies for continual learning that ensure beneficial initialization properties are better maintained throughout training. In particular, we investigate two new regularization techniques for continual learning: (i) Wasserstein regularization toward the initial weight distribution, which is less restrictive than regularizing toward initial weights; and (ii) regularizing weight matrix singular values, which directly ensures gradient diversity is maintained throughout training. We present an experimental analysis that shows these alternative regularizers can improve continual learning performance across a range of supervised learning tasks and model architectures. The alternative regularizers prove to be less sensitive to hyperparameters while demonstrating better training in individual tasks, sustaining trainability as new tasks arrive, and achieving better generalization performance.
6/12/2024