Learning Continually by Spectral Regularization
2406.06811
0
0
Abstract
Loss of plasticity is a phenomenon where neural networks become more difficult to train during the course of learning. Continual learning algorithms seek to mitigate this effect by sustaining good predictive performance while maintaining network trainability. We develop new techniques for improving continual learning by first reconsidering how initialization can ensure trainability during early phases of learning. From this perspective, we derive new regularization strategies for continual learning that ensure beneficial initialization properties are better maintained throughout training. In particular, we investigate two new regularization techniques for continual learning: (i) Wasserstein regularization toward the initial weight distribution, which is less restrictive than regularizing toward initial weights; and (ii) regularizing weight matrix singular values, which directly ensures gradient diversity is maintained throughout training. We present an experimental analysis that shows these alternative regularizers can improve continual learning performance across a range of supervised learning tasks and model architectures. The alternative regularizers prove to be less sensitive to hyperparameters while demonstrating better training in individual tasks, sustaining trainability as new tasks arrive, and achieving better generalization performance.
Create account to get full access
Overview
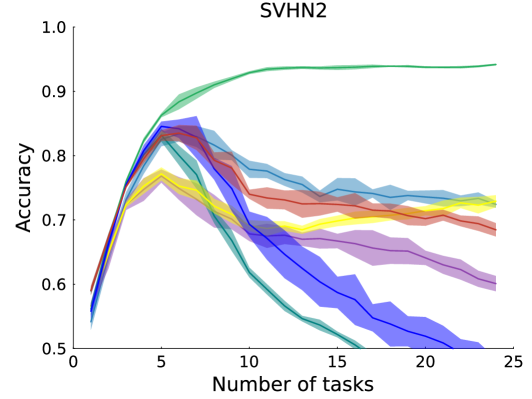
- This paper proposes a spectral regularization approach for continual learning, which aims to learn new tasks without forgetting previous ones.
- The authors analyze the spectral properties of neural networks and show how they can be leveraged to improve continual learning performance.
- The proposed method, called Spectral Regularization (SpR), regularizes the singular values of the network's weight matrices to maintain plasticity and prevent catastrophic forgetting.
Plain English Explanation
Continual learning is the ability of a machine learning model to learn new tasks or information without completely forgetting what it has learned before. This is an important challenge, as real-world applications often require models to adapt and expand their knowledge over time.
The paper introduces a new approach called Spectral Regularization (SpR) to address this problem. The key idea is to focus on the spectral properties of the neural network's weight matrices, which describe how the network transforms and amplifies different input signals.
By regularizing the singular values of these weight matrices, the authors show that the network can maintain plasticity - the ability to learn new tasks - while also preserving its previous knowledge. This helps prevent the catastrophic forgetting that often occurs when neural networks are trained on a sequence of tasks.
The paper provides a detailed analysis of how the spectral properties of the network relate to its continual learning performance. The authors demonstrate that their Spectral Regularization approach outperforms other state-of-the-art continual learning methods on various benchmark tasks.
Technical Explanation
The paper formulates the continual learning problem as a sequence of supervised learning tasks, where the model must learn to perform well on each new task without forgetting how to perform the previous tasks.
The authors analyze the spectral properties of the neural network's weight matrices, which describe how the network transforms and amplifies different input signals. They show that the singular values of these weight matrices are closely related to the network's ability to learn new tasks while retaining previous knowledge.
The proposed method, Spectral Regularization (SpR), explicitly regularizes the singular values of the weight matrices during training. This encourages the network to maintain an appropriate balance between plasticity (the ability to learn new tasks) and stability (the ability to retain previous knowledge), thereby mitigating catastrophic forgetting.
The authors evaluate their approach on several continual learning benchmarks and demonstrate that SpR outperforms other state-of-the-art continual learning methods in terms of both task accuracy and backward transfer (the ability to retain previous knowledge).
Critical Analysis
The paper provides a thorough analysis of the relationship between the spectral properties of neural networks and their continual learning performance. The authors make a convincing case for the importance of maintaining an appropriate balance between plasticity and stability, and show how their Spectral Regularization approach can effectively achieve this.
However, the paper does not address several important practical considerations. For example, the authors assume that the task boundaries are known in advance, which may not always be the case in real-world applications. Additionally, the proposed method may be computationally expensive, as it requires the singular value decomposition of the weight matrices at each training step.
Further research is needed to explore the scalability and robustness of Spectral Regularization in more challenging continual learning scenarios, such as those involving large-scale, real-world datasets and more complex task structures. It would also be interesting to investigate whether the insights from this paper could be combined with other continual learning techniques, such as weight interpolation or adversarial representation learning, to further improve performance.
Conclusion
The paper introduces a novel approach to continual learning based on spectral regularization of neural network weight matrices. The authors provide a compelling analysis of how the spectral properties of neural networks are related to their ability to learn new tasks while retaining previous knowledge.
The proposed Spectral Regularization method demonstrates strong performance on standard continual learning benchmarks, outperforming other state-of-the-art approaches. This work contributes important insights to the field of continual learning and offers a promising direction for further research and development of more robust and adaptable machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Statistical Theory of Regularization-Based Continual Learning
Xuyang Zhao, Huiyuan Wang, Weiran Huang, Wei Lin
0
0
We provide a statistical analysis of regularization-based continual learning on a sequence of linear regression tasks, with emphasis on how different regularization terms affect the model performance. We first derive the convergence rate for the oracle estimator obtained as if all data were available simultaneously. Next, we consider a family of generalized $ell_2$-regularization algorithms indexed by matrix-valued hyperparameters, which includes the minimum norm estimator and continual ridge regression as special cases. As more tasks are introduced, we derive an iterative update formula for the estimation error of generalized $ell_2$-regularized estimators, from which we determine the hyperparameters resulting in the optimal algorithm. Interestingly, the choice of hyperparameters can effectively balance the trade-off between forward and backward knowledge transfer and adjust for data heterogeneity. Moreover, the estimation error of the optimal algorithm is derived explicitly, which is of the same order as that of the oracle estimator. In contrast, our lower bounds for the minimum norm estimator and continual ridge regression show their suboptimality. A byproduct of our theoretical analysis is the equivalence between early stopping and generalized $ell_2$-regularization in continual learning, which may be of independent interest. Finally, we conduct experiments to complement our theory.
6/11/2024

Maintaining Plasticity in Deep Continual Learning
Shibhansh Dohare, J. Fernando Hernandez-Garcia, Parash Rahman, A. Rupam Mahmood, Richard S. Sutton
0
0
Modern deep-learning systems are specialized to problem settings in which training occurs once and then never again, as opposed to continual-learning settings in which training occurs continually. If deep-learning systems are applied in a continual learning setting, then it is well known that they may fail to remember earlier examples. More fundamental, but less well known, is that they may also lose their ability to learn on new examples, a phenomenon called loss of plasticity. We provide direct demonstrations of loss of plasticity using the MNIST and ImageNet datasets repurposed for continual learning as sequences of tasks. In ImageNet, binary classification performance dropped from 89% accuracy on an early task down to 77%, about the level of a linear network, on the 2000th task. Loss of plasticity occurred with a wide range of deep network architectures, optimizers, activation functions, batch normalization, dropout, but was substantially eased by L2-regularization, particularly when combined with weight perturbation. Further, we introduce a new algorithm -- continual backpropagation -- which slightly modifies conventional backpropagation to reinitialize a small fraction of less-used units after each example and appears to maintain plasticity indefinitely.
4/11/2024
✨
Fixed Design Analysis of Regularization-Based Continual Learning
Haoran Li, Jingfeng Wu, Vladimir Braverman
0
0
We consider a continual learning (CL) problem with two linear regression tasks in the fixed design setting, where the feature vectors are assumed fixed and the labels are assumed to be random variables. We consider an $ell_2$-regularized CL algorithm, which computes an Ordinary Least Squares parameter to fit the first dataset, then computes another parameter that fits the second dataset under an $ell_2$-regularization penalizing its deviation from the first parameter, and outputs the second parameter. For this algorithm, we provide tight bounds on the average risk over the two tasks. Our risk bounds reveal a provable trade-off between forgetting and intransigence of the $ell_2$-regularized CL algorithm: with a large regularization parameter, the algorithm output forgets less information about the first task but is intransigent to extract new information from the second task; and vice versa. Our results suggest that catastrophic forgetting could happen for CL with dissimilar tasks (under a precise similarity measurement) and that a well-tuned $ell_2$-regularization can partially mitigate this issue by introducing intransigence.
6/19/2024

Continual Learning with Weight Interpolation
Jk{e}drzej Kozal, Jan Wasilewski, Bartosz Krawczyk, Micha{l} Wo'zniak
0
0
Continual learning poses a fundamental challenge for modern machine learning systems, requiring models to adapt to new tasks while retaining knowledge from previous ones. Addressing this challenge necessitates the development of efficient algorithms capable of learning from data streams and accumulating knowledge over time. This paper proposes a novel approach to continual learning utilizing the weight consolidation method. Our method, a simple yet powerful technique, enhances robustness against catastrophic forgetting by interpolating between old and new model weights after each novel task, effectively merging two models to facilitate exploration of local minima emerging after arrival of new concepts. Moreover, we demonstrate that our approach can complement existing rehearsal-based replay approaches, improving their accuracy and further mitigating the forgetting phenomenon. Additionally, our method provides an intuitive mechanism for controlling the stability-plasticity trade-off. Experimental results showcase the significant performance enhancement to state-of-the-art experience replay algorithms the proposed weight consolidation approach offers. Our algorithm can be downloaded from https://github.com/jedrzejkozal/weight-interpolation-cl.
4/10/2024