Flash3D: Feed-Forward Generalisable 3D Scene Reconstruction from a Single Image

0

Sign in to get full access
Overview
• This paper presents a novel approach called Flash3D for feed-forward 3D scene reconstruction from a single input image.
• The proposed method leverages a divide-and-conquer strategy to overcome the challenges of generalizable 3D reconstruction and achieves real-time performance.
• The system outperforms state-of-the-art approaches on several 3D reconstruction benchmarks, demonstrating its effectiveness and efficiency.
Plain English Explanation
Reconstructing 3D scenes from 2D images is a challenging task, as the depth information is lost when converting a 3D world into a 2D image. Previous methods have struggled to generalize well to a wide range of scenes and often required complex, time-consuming computations.
Flash3D tackles this problem by using a divide-and-conquer strategy. The key idea is to break down the 3D reconstruction problem into smaller, more manageable sub-tasks, which can be solved more efficiently. This allows the system to quickly and accurately reconstruct 3D scenes from single input images, even for complex and diverse scenes.
The researchers demonstrate that their Flash3D approach outperforms other state-of-the-art 3D reconstruction methods on several benchmarks. This means that Flash3D can generate high-quality 3D models from 2D images more accurately and efficiently than existing techniques.
Technical Explanation
The Flash3D system uses a feed-forward neural network architecture to perform 3D scene reconstruction from a single input image. The key innovation is the divide-and-conquer strategy, where the network is divided into multiple sub-modules, each responsible for a specific aspect of the 3D reconstruction task.
These sub-modules include depth estimation, surface normal prediction, and geometry reconstruction. By breaking down the problem in this way, the system can leverage the strengths of different neural network components to achieve high accuracy and real-time performance.
The researchers also introduce several novel architectural designs and training techniques to further improve the system's performance. These include spatial attention mechanisms, multi-scale feature fusion, and self-supervised pre-training.
Experiments on popular 3D reconstruction benchmarks, such as Dig3D, 6-IMG-to-3D, and Guess, demonstrate the superior performance of Flash3D compared to state-of-the-art methods, both in terms of reconstruction accuracy and inference speed.
Critical Analysis
The Flash3D paper presents a promising approach to 3D scene reconstruction, but it also has some potential limitations and areas for further research.
One potential concern is the reliance on a single input image, which may limit the system's ability to handle complex scenes or dynamic environments. Incorporating additional information, such as multi-view images or sensor data, could potentially improve the reconstruction quality and robustness.
Additionally, the evaluation of Flash3D is primarily focused on static scenes, and it would be valuable to investigate its performance on more dynamic or challenging scenarios, such as scenes with occlusions, diverse lighting conditions, or complex geometries.
Finally, while the feed-forward architecture and divide-and-conquer strategy contribute to the system's efficiency, it would be interesting to explore whether incorporating iterative refinement or feedback loops could further enhance the reconstruction quality, particularly for more complex scenes.
Conclusion
The Flash3D paper presents a novel and effective approach to 3D scene reconstruction from a single input image. By leveraging a divide-and-conquer strategy and advanced neural network architectures, the system can achieve high-quality 3D reconstructions in real-time, outperforming state-of-the-art methods on several benchmarks.
This work represents an important step forward in the field of 3D computer vision, with potential applications in areas such as augmented reality, robotics, and virtual environments. The efficient and generalizable nature of Flash3D could enable new possibilities for interactive and immersive experiences, paving the way for further advancements in 3D scene understanding and reconstruction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Flash3D: Feed-Forward Generalisable 3D Scene Reconstruction from a Single Image
Stanislaw Szymanowicz, Eldar Insafutdinov, Chuanxia Zheng, Dylan Campbell, Jo~ao F. Henriques, Christian Rupprecht, Andrea Vedaldi
In this paper, we propose Flash3D, a method for scene reconstruction and novel view synthesis from a single image which is both very generalisable and efficient. For generalisability, we start from a foundation model for monocular depth estimation and extend it to a full 3D shape and appearance reconstructor. For efficiency, we base this extension on feed-forward Gaussian Splatting. Specifically, we predict a first layer of 3D Gaussians at the predicted depth, and then add additional layers of Gaussians that are offset in space, allowing the model to complete the reconstruction behind occlusions and truncations. Flash3D is very efficient, trainable on a single GPU in a day, and thus accessible to most researchers. It achieves state-of-the-art results when trained and tested on RealEstate10k. When transferred to unseen datasets like NYU it outperforms competitors by a large margin. More impressively, when transferred to KITTI, Flash3D achieves better PSNR than methods trained specifically on that dataset. In some instances, it even outperforms recent methods that use multiple views as input. Code, models, demo, and more results are available at https://www.robots.ox.ac.uk/~vgg/research/flash3d/.
Read more6/7/2024

0
Generalizable 3D Scene Reconstruction via Divide and Conquer from a Single View
Andreea Dogaru, Mert Ozer, Bernhard Egger
Single-view 3D reconstruction is currently approached from two dominant perspectives: reconstruction of scenes with limited diversity using 3D data supervision or reconstruction of diverse singular objects using large image priors. However, real-world scenarios are far more complex and exceed the capabilities of these methods. We therefore propose a hybrid method following a divide-and-conquer strategy. We first process the scene holistically, extracting depth and semantic information, and then leverage a single-shot object-level method for the detailed reconstruction of individual components. By following a compositional processing approach, the overall framework achieves full reconstruction of complex 3D scenes from a single image. We purposely design our pipeline to be highly modular by carefully integrating specific procedures for each processing step, without requiring an end-to-end training of the whole system. This enables the pipeline to naturally improve as future methods can replace the individual modules. We demonstrate the reconstruction performance of our approach on both synthetic and real-world scenes, comparing favorable against prior works. Project page: https://andreeadogaru.github.io/Gen3DSR.
Read more4/5/2024

0
Shape of Motion: 4D Reconstruction from a Single Video
Qianqian Wang, Vickie Ye, Hang Gao, Jake Austin, Zhengqi Li, Angjoo Kanazawa
Monocular dynamic reconstruction is a challenging and long-standing vision problem due to the highly ill-posed nature of the task. Existing approaches are limited in that they either depend on templates, are effective only in quasi-static scenes, or fail to model 3D motion explicitly. In this work, we introduce a method capable of reconstructing generic dynamic scenes, featuring explicit, full-sequence-long 3D motion, from casually captured monocular videos. We tackle the under-constrained nature of the problem with two key insights: First, we exploit the low-dimensional structure of 3D motion by representing scene motion with a compact set of SE3 motion bases. Each point's motion is expressed as a linear combination of these bases, facilitating soft decomposition of the scene into multiple rigidly-moving groups. Second, we utilize a comprehensive set of data-driven priors, including monocular depth maps and long-range 2D tracks, and devise a method to effectively consolidate these noisy supervisory signals, resulting in a globally consistent representation of the dynamic scene. Experiments show that our method achieves state-of-the-art performance for both long-range 3D/2D motion estimation and novel view synthesis on dynamic scenes. Project Page: https://shape-of-motion.github.io/
Read more7/19/2024
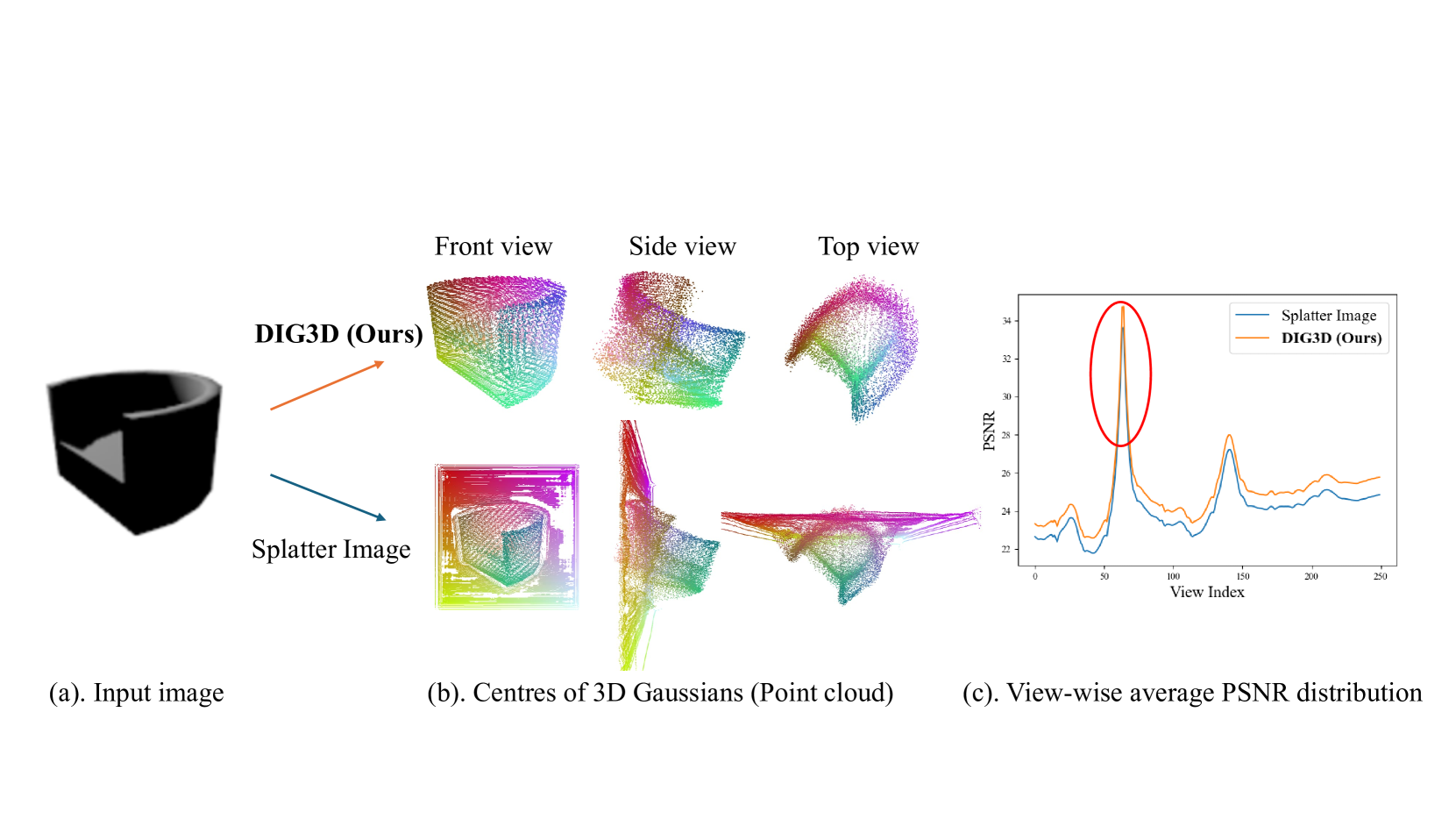
0
DIG3D: Marrying Gaussian Splatting with Deformable Transformer for Single Image 3D Reconstruction
Jiamin Wu, Kenkun Liu, Han Gao, Xiaoke Jiang, Lei Zhang
In this paper, we study the problem of 3D reconstruction from a single-view RGB image and propose a novel approach called DIG3D for 3D object reconstruction and novel view synthesis. Our method utilizes an encoder-decoder framework which generates 3D Gaussians in decoder with the guidance of depth-aware image features from encoder. In particular, we introduce the use of deformable transformer, allowing efficient and effective decoding through 3D reference point and multi-layer refinement adaptations. By harnessing the benefits of 3D Gaussians, our approach offers an efficient and accurate solution for 3D reconstruction from single-view images. We evaluate our method on the ShapeNet SRN dataset, getting PSNR of 24.21 and 24.98 in car and chair dataset, respectively. The result outperforming the recent method by around 2.25%, demonstrating the effectiveness of our method in achieving superior results.
Read more4/26/2024