6Img-to-3D: Few-Image Large-Scale Outdoor Driving Scene Reconstruction
2404.12378
0
0

Abstract
Current 3D reconstruction techniques struggle to infer unbounded scenes from a few images faithfully. Specifically, existing methods have high computational demands, require detailed pose information, and cannot reconstruct occluded regions reliably. We introduce 6Img-to-3D, an efficient, scalable transformer-based encoder-renderer method for single-shot image to 3D reconstruction. Our method outputs a 3D-consistent parameterized triplane from only six outward-facing input images for large-scale, unbounded outdoor driving scenarios. We take a step towards resolving existing shortcomings by combining contracted custom cross- and self-attention mechanisms for triplane parameterization, differentiable volume rendering, scene contraction, and image feature projection. We showcase that six surround-view vehicle images from a single timestamp without global pose information are enough to reconstruct 360$^{circ}$ scenes during inference time, taking 395 ms. Our method allows, for example, rendering third-person images and birds-eye views. Our code is available at https://github.com/continental/6Img-to-3D, and more examples can be found at our website here https://6Img-to-3D.GitHub.io/.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents "6Img-to-3D", a method for reconstructing large-scale outdoor driving scenes from just 6 input images.
- The researchers develop a novel neural network architecture and training process to efficiently generate high-quality 3D scene reconstructions from a small number of input views.
- The approach is designed to enable autonomous vehicles and robotics to rapidly build detailed 3D maps of their surrounding environments using minimal sensor data.
Plain English Explanation
The "6Img-to-3D" method tackles the challenge of generating detailed 3D models of large outdoor scenes using only a handful of camera images. This is an important capability for self-driving cars and robots, which need to quickly build 3D maps of their surroundings to safely navigate.
Traditionally, creating high-fidelity 3D reconstructions has required capturing many images from different viewpoints, which can be time-consuming and resource-intensive. The 6Img-to-3D approach instead uses a novel neural network design and training process to reconstruct detailed 3D scenes from just 6 input photos.
This means self-driving cars and robots could quickly build 3D maps of their environments using minimal sensor data, improving their efficiency and safety. The key innovation is the neural network's ability to intelligently fill in missing information and reconstruct high-quality 3D models from very limited input.
Technical Explanation
The 6Img-to-3D model takes 6 images as input and generates a detailed 3D reconstruction of the corresponding outdoor driving scene. The network architecture consists of link to related work on scene representation, e.g. [G3DR: Generative 3D Reconstruction with Differentiable Renderer] to encode the input views, and link to related work on depth/pose estimation, e.g. [Incremental Joint Learning of Depth and Pose] to predict the 3D structure and camera poses.
The training process incorporates several novel techniques to enable high-quality reconstruction from limited input, including link to related work on scenario generalization, e.g. [SGV3D: Towards Scenario Generalization for Vision-based Roadside 3D] and link to related work on text-to-3D generation, e.g. [DreamScene360: Unconstrained Text-to-3D Scene Generation].
The experiments demonstrate that 6Img-to-3D can reconstruct large-scale outdoor driving scenes with high fidelity, outperforming baseline methods that use more input images. This suggests the approach could be valuable for autonomous navigation and 3D mapping applications that require efficient scene understanding from limited sensor data.
Critical Analysis
The 6Img-to-3D method represents an impressive technical achievement in leveraging deep learning to enable high-quality 3D reconstruction from a small number of input views. However, the paper acknowledges several limitations and areas for future work:
- The approach is evaluated on outdoor driving scenes, but its performance on other types of large-scale environments is unclear. Further experiments would be needed to assess its generalizability.
- The reconstruction quality, while high, may still have inaccuracies or missing details compared to ground truth 3D data. Incorporating additional quality assurance measures could help improve reliability.
- The training process is complex, involving several specialized components. Simplifying the architecture and training pipeline could make the method more accessible and scalable.
Additionally, the ethical implications of rapid 3D mapping capabilities for autonomous vehicles warrant further consideration, such as potential privacy concerns and bias in training data. Responsible development and deployment of such technologies will be crucial.
Conclusion
The 6Img-to-3D method represents an important advance in 3D scene reconstruction, enabling autonomous vehicles and robots to efficiently build detailed models of their surroundings using minimal sensor data. This has significant implications for improving the safety and capabilities of self-driving cars, as well as expanding the potential applications of 3D mapping in robotics and other domains.
While the technical implementation is complex, the core idea of leveraging deep learning to reconstruct high-quality 3D scenes from limited inputs is a compelling innovation. Further research to address the identified limitations and ethical considerations could unlock even more transformative applications of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
UniScene: Multi-Camera Unified Pre-training via 3D Scene Reconstruction for Autonomous Driving
Chen Min, Liang Xiao, Dawei Zhao, Yiming Nie, Bin Dai
0
0
Multi-camera 3D perception has emerged as a prominent research field in autonomous driving, offering a viable and cost-effective alternative to LiDAR-based solutions. The existing multi-camera algorithms primarily rely on monocular 2D pre-training. However, the monocular 2D pre-training overlooks the spatial and temporal correlations among the multi-camera system. To address this limitation, we propose the first multi-camera unified pre-training framework, called UniScene, which involves initially reconstructing the 3D scene as the foundational stage and subsequently fine-tuning the model on downstream tasks. Specifically, we employ Occupancy as the general representation for the 3D scene, enabling the model to grasp geometric priors of the surrounding world through pre-training. A significant benefit of UniScene is its capability to utilize a considerable volume of unlabeled image-LiDAR pairs for pre-training purposes. The proposed multi-camera unified pre-training framework demonstrates promising results in key tasks such as multi-camera 3D object detection and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, UniScene shows a significant improvement of about 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. By adopting our unified pre-training method, a 25% reduction in 3D training annotation costs can be achieved, offering significant practical value for the implementation of real-world autonomous driving. Codes are publicly available at https://github.com/chaytonmin/UniScene.
4/30/2024

Incremental Joint Learning of Depth, Pose and Implicit Scene Representation on Monocular Camera in Large-scale Scenes
Tianchen Deng, Nailin Wang, Chongdi Wang, Shenghai Yuan, Jingchuan Wang, Danwei Wang, Weidong Chen
0
0
Dense scene reconstruction for photo-realistic view synthesis has various applications, such as VR/AR, autonomous vehicles. However, most existing methods have difficulties in large-scale scenes due to three core challenges: textit{(a) inaccurate depth input.} Accurate depth input is impossible to get in real-world large-scale scenes. textit{(b) inaccurate pose estimation.} Most existing approaches rely on accurate pre-estimated camera poses. textit{(c) insufficient scene representation capability.} A single global radiance field lacks the capacity to effectively scale to large-scale scenes. To this end, we propose an incremental joint learning framework, which can achieve accurate depth, pose estimation, and large-scale scene reconstruction. A vision transformer-based network is adopted as the backbone to enhance performance in scale information estimation. For pose estimation, a feature-metric bundle adjustment (FBA) method is designed for accurate and robust camera tracking in large-scale scenes. In terms of implicit scene representation, we propose an incremental scene representation method to construct the entire large-scale scene as multiple local radiance fields to enhance the scalability of 3D scene representation. Extended experiments have been conducted to demonstrate the effectiveness and accuracy of our method in depth estimation, pose estimation, and large-scale scene reconstruction.
4/10/2024

G3DR: Generative 3D Reconstruction in ImageNet
Pradyumna Reddy, Ismail Elezi, Jiankang Deng
0
0
We introduce a novel 3D generative method, Generative 3D Reconstruction (G3DR) in ImageNet, capable of generating diverse and high-quality 3D objects from single images, addressing the limitations of existing methods. At the heart of our framework is a novel depth regularization technique that enables the generation of scenes with high-geometric fidelity. G3DR also leverages a pretrained language-vision model, such as CLIP, to enable reconstruction in novel views and improve the visual realism of generations. Additionally, G3DR designs a simple but effective sampling procedure to further improve the quality of generations. G3DR offers diverse and efficient 3D asset generation based on class or text conditioning. Despite its simplicity, G3DR is able to beat state-of-theart methods, improving over them by up to 22% in perceptual metrics and 90% in geometry scores, while needing only half of the training time. Code is available at https://github.com/preddy5/G3DR
4/4/2024
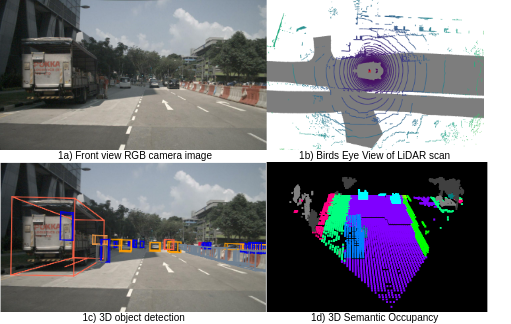
Real-time 3D semantic occupancy prediction for autonomous vehicles using memory-efficient sparse convolution
Samuel Sze, Lars Kunze
0
0
In autonomous vehicles, understanding the surrounding 3D environment of the ego vehicle in real-time is essential. A compact way to represent scenes while encoding geometric distances and semantic object information is via 3D semantic occupancy maps. State of the art 3D mapping methods leverage transformers with cross-attention mechanisms to elevate 2D vision-centric camera features into the 3D domain. However, these methods encounter significant challenges in real-time applications due to their high computational demands during inference. This limitation is particularly problematic in autonomous vehicles, where GPU resources must be shared with other tasks such as localization and planning. In this paper, we introduce an approach that extracts features from front-view 2D camera images and LiDAR scans, then employs a sparse convolution network (Minkowski Engine), for 3D semantic occupancy prediction. Given that outdoor scenes in autonomous driving scenarios are inherently sparse, the utilization of sparse convolution is particularly apt. By jointly solving the problems of 3D scene completion of sparse scenes and 3D semantic segmentation, we provide a more efficient learning framework suitable for real-time applications in autonomous vehicles. We also demonstrate competitive accuracy on the nuScenes dataset.
4/30/2024