FlashRAG: A Modular Toolkit for Efficient Retrieval-Augmented Generation Research

0
🛸
Sign in to get full access
Overview
- The paper introduces FlashRAG, an efficient and modular open-source toolkit designed to assist researchers in reproducing existing Retrieval Augmented Generation (RAG) methods and developing their own RAG algorithms within a unified framework.
- RAG techniques have gained significant research attention with the advent of Large Language Models (LLMs), and numerous novel algorithms and models have been introduced to enhance various aspects of RAG systems.
- However, the lack of a standardized framework for implementation and the inherent complexity of the RAG process make it challenging and time-consuming for researchers to compare and evaluate these approaches consistently.
- Existing RAG toolkits, such as LangChain and LlamaIndex, are often heavy and unwieldy, failing to meet the personalized needs of researchers.
Plain English Explanation
Retrieval Augmented Generation (RAG) is a technique that combines the power of large language models with the ability to retrieve relevant information from external sources to improve the performance of various natural language processing tasks, such as question answering, text generation, and summarization.
The introduction of advanced RAG methods has led to significant research progress in this area, with numerous novel algorithms and models being developed. However, the lack of a standardized framework for implementing and evaluating these approaches has made it challenging for researchers to compare and build upon each other's work.
To address this challenge, the researchers have developed FlashRAG, an open-source toolkit that provides a unified and efficient platform for researchers to reproduce existing RAG methods and develop their own algorithms. The toolkit includes a modular and customizable framework, a rich collection of pre-implemented RAG methods, a comprehensive set of benchmark datasets, and a suite of evaluation metrics.
By providing a standardized and streamlined environment for RAG research, FlashRAG aims to accelerate the progress in this field and enable researchers to more easily compare and build upon each other's work.
Technical Explanation
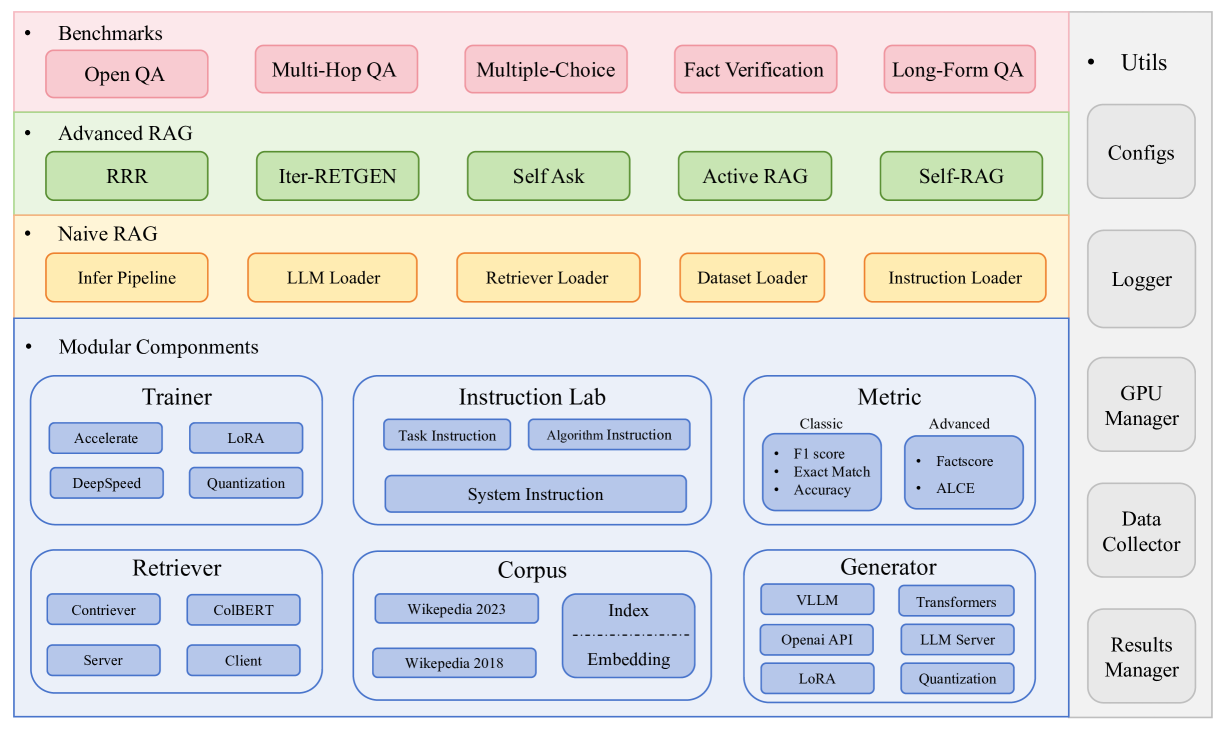
The researchers have developed FlashRAG, an open-source toolkit designed to assist researchers in reproducing and developing Retrieval Augmented Generation (RAG) algorithms. The toolkit implements 12 advanced RAG methods and has gathered and organized 32 benchmark datasets, providing a comprehensive and standardized environment for RAG research.
The key features of FlashRAG include:
-
Customizable Modular Framework: The toolkit offers a modular and flexible design, allowing researchers to easily customize and extend the framework to suit their specific research needs.
-
Rich Collection of Pre-implemented RAG Works: FlashRAG provides a comprehensive set of pre-implemented RAG methods, enabling researchers to reproduce and compare various approaches without the need to start from scratch.
-
Comprehensive Datasets: The toolkit has gathered and organized 32 benchmark datasets, covering a wide range of natural language processing tasks, to facilitate comprehensive evaluation and comparison of RAG methods.
-
Efficient Auxiliary Pre-processing Scripts: FlashRAG includes a suite of efficient auxiliary pre-processing scripts to streamline the dataset preparation and preprocessing tasks, reducing the overhead for researchers.
-
Extensive and Standard Evaluation Metrics: The toolkit offers a comprehensive set of evaluation metrics, allowing researchers to thoroughly assess the performance of their RAG models across various dimensions, such as task-specific metrics and general language understanding benchmarks.
By providing this unified and efficient framework, FlashRAG aims to address the challenges faced by researchers in the RAG domain, enabling them to more easily reproduce existing methods, develop novel algorithms, and compare their work in a consistent environment.
Critical Analysis
The researchers have developed a valuable and timely toolkit in FlashRAG to address the challenges faced by researchers in the Retrieval Augmented Generation (RAG) domain. The modular and customizable design of the toolkit, along with the comprehensive collection of pre-implemented RAG methods and benchmark datasets, provides a strong foundation for advancing research in this area.
One potential limitation of the toolkit is the extent to which it can accommodate the evolving needs of the research community. As the field of RAG continues to progress, with new techniques and use cases emerging, the researchers may need to regularly update and expand the toolkit to ensure it remains relevant and useful for researchers.
Additionally, the performance and scalability of the toolkit itself could be an area of concern, especially as researchers work with larger and more complex models and datasets. The researchers may want to investigate ways to optimize the toolkit's resource utilization and performance to ensure it can handle the growing demands of RAG research.
Furthermore, the researchers could consider incorporating more intuitive and user-friendly features, such as interactive visualizations or guided tutorials, to make the toolkit more accessible and easier to use for researchers who may not have extensive experience in this domain.
Despite these potential areas for improvement, FlashRAG represents a significant step forward in providing a standardized and efficient framework for Retrieval Augmented Generation research. By addressing the challenges faced by researchers in this field, the toolkit has the potential to accelerate the progress of RAG techniques and their applications in various natural language processing tasks.
Conclusion
The introduction of FlashRAG, an efficient and modular open-source toolkit for Retrieval Augmented Generation (RAG) research, addresses a crucial need in the field. By providing a standardized and customizable framework, the toolkit enables researchers to more easily reproduce existing RAG methods, develop novel algorithms, and compare their work in a consistent environment.
The key features of FlashRAG, such as the modular design, rich collection of pre-implemented RAG works, comprehensive datasets, and extensive evaluation metrics, have the potential to significantly accelerate the progress of RAG research and its applications in areas like question answering, text generation, and summarization.
As the field of RAG continues to evolve, the researchers behind FlashRAG will need to ensure the toolkit remains relevant and adaptable to the changing needs of the research community. By addressing potential limitations and incorporating user-friendly features, the toolkit can become an invaluable resource for researchers in the Retrieval Augmented Generation domain, ultimately driving the advancement of this important field of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
FlashRAG: A Modular Toolkit for Efficient Retrieval-Augmented Generation Research
Jiajie Jin, Yutao Zhu, Xinyu Yang, Chenghao Zhang, Zhicheng Dou
With the advent of Large Language Models (LLMs), the potential of Retrieval Augmented Generation (RAG) techniques have garnered considerable research attention. Numerous novel algorithms and models have been introduced to enhance various aspects of RAG systems. However, the absence of a standardized framework for implementation, coupled with the inherently intricate RAG process, makes it challenging and time-consuming for researchers to compare and evaluate these approaches in a consistent environment. Existing RAG toolkits like LangChain and LlamaIndex, while available, are often heavy and unwieldy, failing to meet the personalized needs of researchers. In response to this challenge, we propose FlashRAG, an efficient and modular open-source toolkit designed to assist researchers in reproducing existing RAG methods and in developing their own RAG algorithms within a unified framework. Our toolkit implements 12 advanced RAG methods and has gathered and organized 32 benchmark datasets. Our toolkit has various features, including customizable modular framework, rich collection of pre-implemented RAG works, comprehensive datasets, efficient auxiliary pre-processing scripts, and extensive and standard evaluation metrics. Our toolkit and resources are available at https://github.com/RUC-NLPIR/FlashRAG.
Read more5/24/2024
0
RAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation
Xuanwang Zhang, Yunze Song, Yidong Wang, Shuyun Tang, Xinfeng Li, Zhengran Zeng, Zhen Wu, Wei Ye, Wenyuan Xu, Yue Zhang, Xinyu Dai, Shikun Zhang, Qingsong Wen
Large Language Models (LLMs) demonstrate human-level capabilities in dialogue, reasoning, and knowledge retention. However, even the most advanced LLMs face challenges such as hallucinations and real-time updating of their knowledge. Current research addresses this bottleneck by equipping LLMs with external knowledge, a technique known as Retrieval Augmented Generation (RAG). However, two key issues constrained the development of RAG. First, there is a growing lack of comprehensive and fair comparisons between novel RAG algorithms. Second, open-source tools such as LlamaIndex and LangChain employ high-level abstractions, which results in a lack of transparency and limits the ability to develop novel algorithms and evaluation metrics. To close this gap, we introduce RAGLAB, a modular and research-oriented open-source library. RAGLAB reproduces 6 existing algorithms and provides a comprehensive ecosystem for investigating RAG algorithms. Leveraging RAGLAB, we conduct a fair comparison of 6 RAG algorithms across 10 benchmarks. With RAGLAB, researchers can efficiently compare the performance of various algorithms and develop novel algorithms.
Read more9/10/2024

0
Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks
Yunfan Gao, Yun Xiong, Meng Wang, Haofen Wang
Retrieval-augmented Generation (RAG) has markedly enhanced the capabilities of Large Language Models (LLMs) in tackling knowledge-intensive tasks. The increasing demands of application scenarios have driven the evolution of RAG, leading to the integration of advanced retrievers, LLMs and other complementary technologies, which in turn has amplified the intricacy of RAG systems. However, the rapid advancements are outpacing the foundational RAG paradigm, with many methods struggling to be unified under the process of retrieve-then-generate. In this context, this paper examines the limitations of the existing RAG paradigm and introduces the modular RAG framework. By decomposing complex RAG systems into independent modules and specialized operators, it facilitates a highly reconfigurable framework. Modular RAG transcends the traditional linear architecture, embracing a more advanced design that integrates routing, scheduling, and fusion mechanisms. Drawing on extensive research, this paper further identifies prevalent RAG patterns-linear, conditional, branching, and looping-and offers a comprehensive analysis of their respective implementation nuances. Modular RAG presents innovative opportunities for the conceptualization and deployment of RAG systems. Finally, the paper explores the potential emergence of new operators and paradigms, establishing a solid theoretical foundation and a practical roadmap for the continued evolution and practical deployment of RAG technologies.
Read more8/1/2024
🛸
0
CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of Large Language Models
Yuanjie Lyu, Zhiyu Li, Simin Niu, Feiyu Xiong, Bo Tang, Wenjin Wang, Hao Wu, Huanyong Liu, Tong Xu, Enhong Chen
Retrieval-Augmented Generation (RAG) is a technique that enhances the capabilities of large language models (LLMs) by incorporating external knowledge sources. This method addresses common LLM limitations, including outdated information and the tendency to produce inaccurate hallucinated content. However, the evaluation of RAG systems is challenging, as existing benchmarks are limited in scope and diversity. Most of the current benchmarks predominantly assess question-answering applications, overlooking the broader spectrum of situations where RAG could prove advantageous. Moreover, they only evaluate the performance of the LLM component of the RAG pipeline in the experiments, and neglect the influence of the retrieval component and the external knowledge database. To address these issues, this paper constructs a large-scale and more comprehensive benchmark, and evaluates all the components of RAG systems in various RAG application scenarios. Specifically, we have categorized the range of RAG applications into four distinct types-Create, Read, Update, and Delete (CRUD), each representing a unique use case. Create refers to scenarios requiring the generation of original, varied content. Read involves responding to intricate questions in knowledge-intensive situations. Update focuses on revising and rectifying inaccuracies or inconsistencies in pre-existing texts. Delete pertains to the task of summarizing extensive texts into more concise forms. For each of these CRUD categories, we have developed comprehensive datasets to evaluate the performance of RAG systems. We also analyze the effects of various components of the RAG system, such as the retriever, the context length, the knowledge base construction, and the LLM. Finally, we provide useful insights for optimizing the RAG technology for different scenarios.
Read more7/16/2024