Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
2309.11977
0
0

Abstract
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper proposes a method to improve language model-based zero-shot text-to-speech (TTS) synthesis using multi-scale acoustic prompts.
- The key idea is to leverage acoustic information from multiple scales (e.g., phoneme, syllable, word) to guide the language model and generate more natural-sounding speech.
- The authors introduce a speaker-aware text encoder and a multi-scale acoustic prompt module to achieve this.
Plain English Explanation
The paper discusses a way to improve the quality of computer-generated speech when using language models for text-to-speech (TTS) without any training data for the specific speaker. The main challenge with this "zero-shot" TTS is that the language model may not fully capture the nuances of how a person speaks.
To address this, the researchers propose using "acoustic prompts" - information about the sounds and rhythm of speech at different levels, like individual sounds, syllables, and whole words. By incorporating this acoustic data, the language model can better mimic the target speaker's voice and produce more natural-sounding speech.
The paper introduces two key components to enable this: a "speaker-aware text encoder" that takes the text input and speaker information into account, and a "multi-scale acoustic prompt module" that provides the acoustic cues at various levels. Together, these allow the language model to generate speech that sounds closer to how a human would say the words.
Technical Explanation
The paper presents a method to improve zero-shot text-to-speech (TTS) synthesis using multi-scale acoustic prompts. The key contributions are:
-
Speaker-aware Text Encoder: This module encodes the input text while also incorporating information about the target speaker's voice characteristics. This helps the subsequent components better model the speaker's speaking style.
-
Multi-scale Acoustic Prompt Module: This module extracts acoustic features at multiple levels of granularity (phoneme, syllable, word) from reference speech samples. These multi-scale acoustic prompts are then used to guide the language model in generating more natural-sounding speech.
The authors evaluate their approach on several benchmark TTS datasets and show significant improvements in speech quality compared to prior zero-shot TTS methods that did not leverage acoustic prompts. The proposed technique demonstrates the advantages of incorporating multi-modal prompting for enhancing the performance of language model-based TTS.
Critical Analysis
The paper presents a well-designed approach to improve the quality of zero-shot text-to-speech synthesis by leveraging multi-scale acoustic information. The authors have carefully considered the limitations of prior work and introduced innovative components to address them.
One potential limitation is the reliance on reference speech samples for the acoustic prompts. In real-world scenarios, such reference data may not always be available, so the authors could further explore techniques to generate or approximate the required acoustic information without requiring explicit speech recordings.
Additionally, the paper focuses on improving the overall speech quality, but does not delve into aspects like emotional expression or speaking style control. Extending the approach to enable more expressive and controllable zero-shot TTS could be an interesting direction for future research.
Conclusion
The proposed method for improving language model-based zero-shot text-to-speech synthesis using multi-scale acoustic prompts represents a significant advancement in the field. By incorporating acoustic information at multiple levels, the approach can generate more natural-sounding speech without requiring any training data for the target speaker.
This work highlights the importance of leveraging diverse modalities, such as acoustics, to enhance the performance of language models in downstream tasks like TTS. The techniques introduced in this paper could have broader implications for prompt-based control of language models and contribute to the development of more expressive and human-like speech synthesis systems.
Related Papers
🗣️
Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Zhenhui Ye, Shengpeng Ji, Qian Yang, Chen Zhang, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun Ma, Zhou Zhao
0
0
Zero-shot text-to-speech (TTS) aims to synthesize voices with unseen speech prompts, which significantly reduces the data and computation requirements for voice cloning by skipping the fine-tuning process. However, the prompting mechanisms of zero-shot TTS still face challenges in the following aspects: 1) previous works of zero-shot TTS are typically trained with single-sentence prompts, which significantly restricts their performance when the data is relatively sufficient during the inference stage. 2) The prosodic information in prompts is highly coupled with timbre, making it untransferable to each other. This paper introduces Mega-TTS 2, a generic prompting mechanism for zero-shot TTS, to tackle the aforementioned challenges. Specifically, we design a powerful acoustic autoencoder that separately encodes the prosody and timbre information into the compressed latent space while providing high-quality reconstructions. Then, we propose a multi-reference timbre encoder and a prosody latent language model (P-LLM) to extract useful information from multi-sentence prompts. We further leverage the probabilities derived from multiple P-LLM outputs to produce transferable and controllable prosody. Experimental results demonstrate that Mega-TTS 2 could not only synthesize identity-preserving speech with a short prompt of an unseen speaker from arbitrary sources but consistently outperform the fine-tuning method when the volume of data ranges from 10 seconds to 5 minutes. Furthermore, our method enables to transfer various speaking styles to the target timbre in a fine-grained and controlled manner. Audio samples can be found in https://boostprompt.github.io/boostprompt/.
4/11/2024
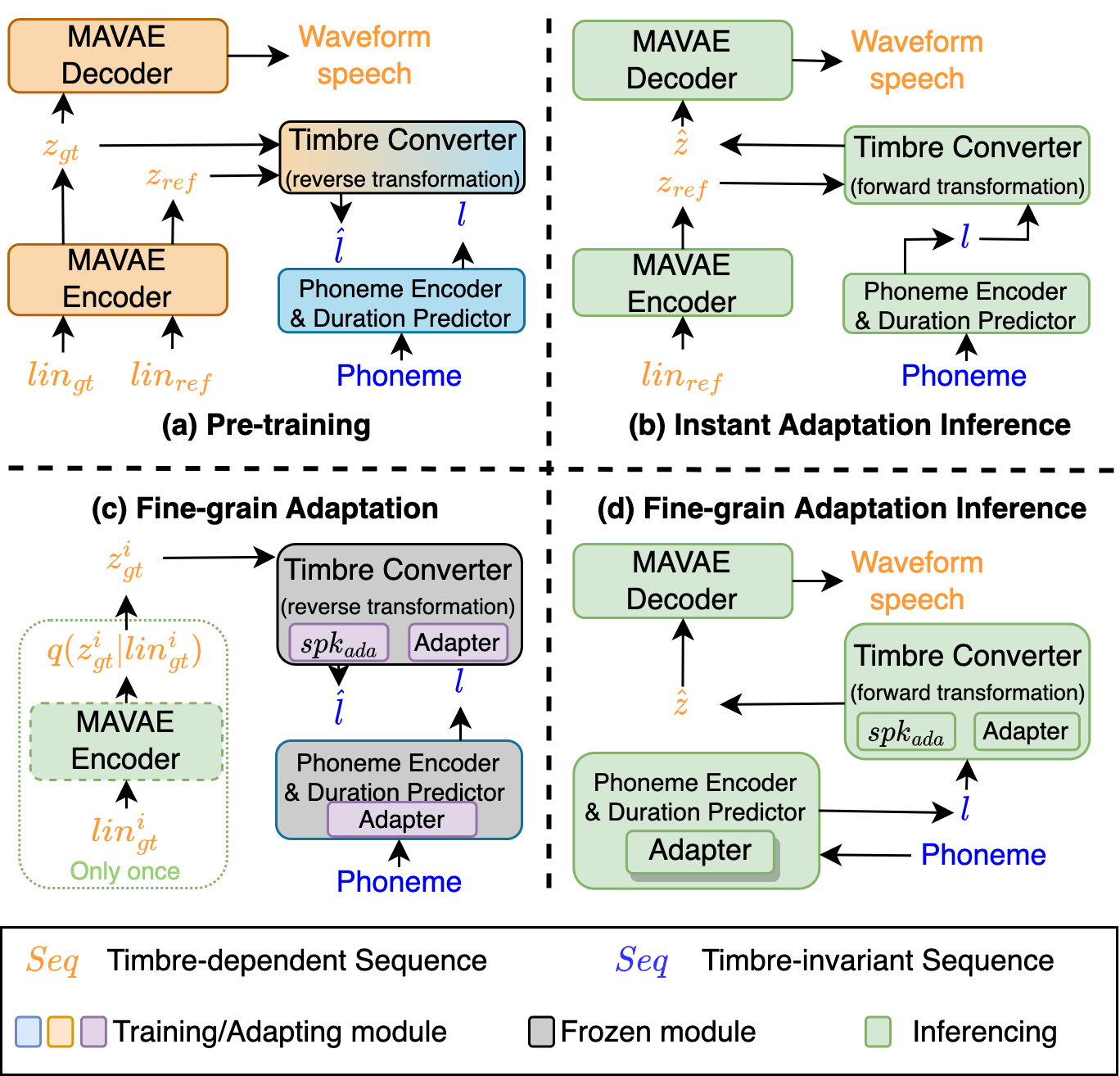
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Wenbin Wang, Yang Song, Sanjay Jha
0
0
Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as instant and fine-grained adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
4/30/2024
CLaM-TTS: Improving Neural Codec Language Model for Zero-Shot Text-to-Speech
Jaehyeon Kim, Keon Lee, Seungjun Chung, Jaewoong Cho
0
0
With the emergence of neural audio codecs, which encode multiple streams of discrete tokens from audio, large language models have recently gained attention as a promising approach for zero-shot Text-to-Speech (TTS) synthesis. Despite the ongoing rush towards scaling paradigms, audio tokenization ironically amplifies the scalability challenge, stemming from its long sequence length and the complexity of modelling the multiple sequences. To mitigate these issues, we present CLaM-TTS that employs a probabilistic residual vector quantization to (1) achieve superior compression in the token length, and (2) allow a language model to generate multiple tokens at once, thereby eliminating the need for cascaded modeling to handle the number of token streams. Our experimental results demonstrate that CLaM-TTS is better than or comparable to state-of-the-art neural codec-based TTS models regarding naturalness, intelligibility, speaker similarity, and inference speed. In addition, we examine the impact of the pretraining extent of the language models and their text tokenization strategies on performances.
4/4/2024
🗣️
FlashSpeech: Efficient Zero-Shot Speech Synthesis
Zhen Ye, Zeqian Ju, Haohe Liu, Xu Tan, Jianyi Chen, Yiwen Lu, Peiwen Sun, Jiahao Pan, Weizhen Bian, Shulin He, Qifeng Liu, Yike Guo, Wei Xue
0
0
Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.
4/26/2024