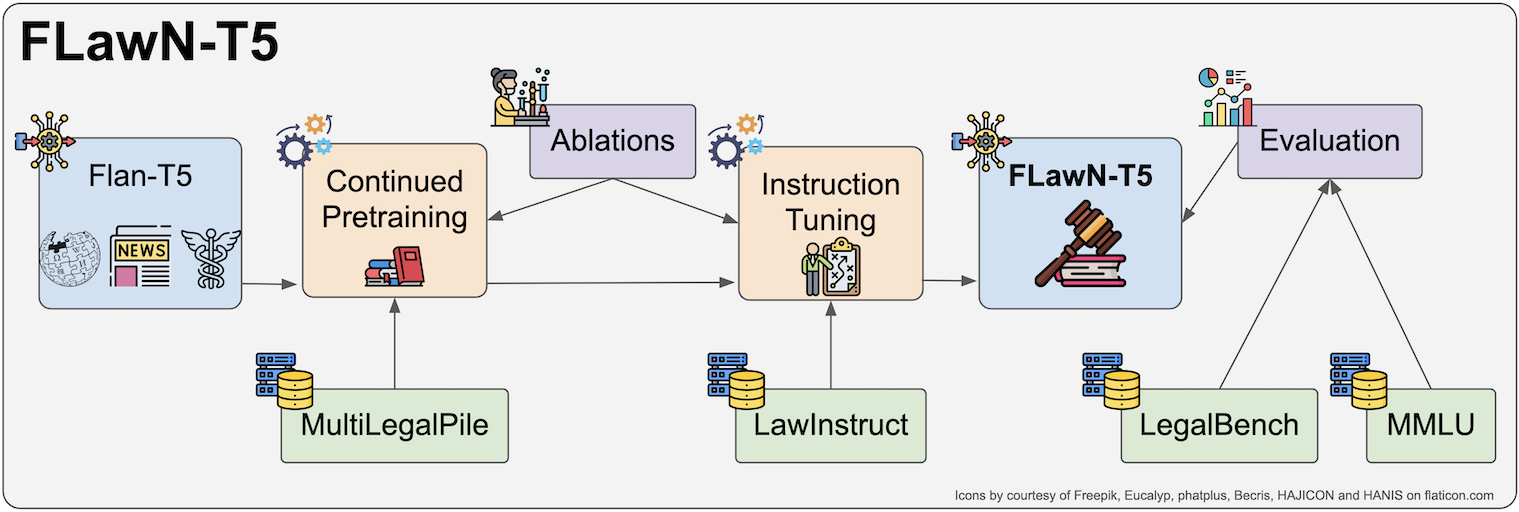
FLawN-T5: An Empirical Examination of Effective Instruction-Tuning Data Mixtures for Legal Reasoning
2404.02127
0
0
Abstract
Instruction tuning is an important step in making language models useful for direct user interaction. However, many legal tasks remain out of reach for most open LLMs and there do not yet exist any large scale instruction datasets for the domain. This critically limits research in this application area. In this work, we curate LawInstruct, a large legal instruction dataset, covering 17 jurisdictions, 24 languages and a total of 12M examples. We present evidence that domain-specific pretraining and instruction tuning improve performance on LegalBench, including improving Flan-T5 XL by 8 points or 16% over the baseline. However, the effect does not generalize across all tasks, training regimes, model sizes, and other factors. LawInstruct is a resource for accelerating the development of models with stronger information processing and decision making capabilities in the legal domain.
Create account to get full access
Overview
- The paper explores effective ways to combine different datasets for "instruction tuning" - a technique to fine-tune large language models for specialized tasks like legal reasoning.
- The researchers experimented with mixing various datasets, including legal documents, to see which combinations produced the best results on legal reasoning benchmarks.
- They found that a balanced mixture of legal and general language data led to the strongest performance, outperforming models trained on legal data alone.
Plain English Explanation
The researchers wanted to find the best way to train a powerful language model, like GPT-3, to excel at legal reasoning tasks. Rather than just using legal documents to fine-tune the model, they tried mixing in different types of text data to see what worked best.
The idea is that legal language and reasoning have unique characteristics, so a model trained only on legal documents may struggle with the nuances. By also incorporating more general language data, the model can learn broader context and patterns that help it apply legal knowledge more effectively.
The researchers experimented with various data mixtures, evaluating the models' performance on standard benchmarks for legal reasoning. They found that a balanced combination of legal and general text data produced the strongest results, outperforming models trained solely on legal data.
This suggests that a diverse training approach, which exposes the language model to a rich variety of language and knowledge, is key for developing capable AI systems in specialized domains like law. The model can learn the specialized skills while also building a robust general understanding to draw upon.
Technical Explanation
The paper introduces FLawN-T5, a language model fine-tuned for legal reasoning tasks through "instruction tuning" - a technique that involves training the model on a diverse set of prompts and target outputs.
The researchers experimented with different data mixtures for this instruction tuning process. They compared models trained on:
- Legal data alone (e.g. case law, statutes, legal briefs)
- A balanced mixture of legal and general language data (e.g. books, websites, dialogues)
- Various other ratios of legal to general data
The models were evaluated on established benchmarks for legal reasoning, including tasks like legal question answering, legal text summarization, and legal document classification.
The results showed that the model trained on the balanced legal-general data mixture significantly outperformed the model trained on legal data alone. This suggests that exposing the model to a diverse range of language, beyond just legal jargon, helps it develop more robust and transferable reasoning abilities.
The researchers hypothesize that the general language data provides the model with broader contextual knowledge and patterns that complement the specialized legal skills acquired from the legal corpus. This allows the model to better apply its legal expertise in a flexible and contextual manner.
Critical Analysis
The paper provides a thorough and well-designed empirical study on an important problem in AI and legal tech. The researchers carefully constructed their experiments to isolate the effects of data mixture on legal reasoning performance.
One limitation is that the study only considers English language data and tasks. It would be valuable to see if these findings hold true for other legal systems and languages as well.
Additionally, the paper does not delve into the specific types of legal and general language data used. A deeper analysis of how different genres or domains within these broad categories impact the results could yield further insights.
The researchers also acknowledge that their conclusions are based on current benchmark tasks, which may not fully capture the nuances of real-world legal reasoning. Further evaluation on more authentic and open-ended legal challenges would strengthen the practical implications of the work.
Overall, this research represents an important step in developing effective AI systems for legal applications. The insights on data mixture provide a useful guide for future work in this area, while also highlighting the need for continued exploration of model architectures, training techniques, and evaluation methods.
Conclusion
The FLawN-T5 study shows that a balanced mixture of legal and general language data is an effective approach for instruction tuning language models to excel at legal reasoning tasks. This suggests that building robust AI systems for specialized domains like law requires exposing the models to diverse knowledge and language patterns, rather than just the target domain data alone.
These findings have significant implications for the development of AI-powered legal tools and services. By incorporating a richer training approach, researchers and developers can create language models that better understand and apply legal concepts in flexible and contextual ways. This could lead to more capable AI assistants for legal research, document review, contract analysis, and other critical legal workflows.
More broadly, this work highlights the importance of data mixture and model architecture design for building AI systems that can effectively leverage specialized knowledge while maintaining general intelligence. As the field of AI continues to advance, studies like this will be crucial for guiding the development of capable, trustworthy, and adaptable AI applications across diverse domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Contrastive Instruction Tuning
Tianyi Lorena Yan, Fei Wang, James Y. Huang, Wenxuan Zhou, Fan Yin, Aram Galstyan, Wenpeng Yin, Muhao Chen
0
0
Instruction tuning has been used as a promising approach to improve the performance of large language models (LLMs) on unseen tasks. However, current LLMs exhibit limited robustness to unseen instructions, generating inconsistent outputs when the same instruction is phrased with slightly varied forms or language styles. This behavior indicates LLMs' lack of robustness to textual variations and generalizability to unseen instructions, potentially leading to trustworthiness issues. Accordingly, we propose Contrastive Instruction Tuning, which maximizes the similarity between the hidden representations of semantically equivalent instruction-instance pairs while minimizing the similarity between semantically different ones. To facilitate this approach, we augment the existing FLAN collection by paraphrasing task instructions. Experiments on the PromptBench benchmark show that CoIN consistently improves LLMs' robustness to unseen instructions with variations across character, word, sentence, and semantic levels by an average of +2.5% in accuracy. Code is available at https://github.com/luka-group/CoIN.
6/7/2024
💬
From Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning
Xuansheng Wu, Wenlin Yao, Jianshu Chen, Xiaoman Pan, Xiaoyang Wang, Ninghao Liu, Dong Yu
0
0
Large Language Models (LLMs) have achieved remarkable success, where instruction tuning is the critical step in aligning LLMs with user intentions. In this work, we investigate how the instruction tuning adjusts pre-trained models with a focus on intrinsic changes. Specifically, we first develop several local and global explanation methods, including a gradient-based method for input-output attribution, and techniques for interpreting patterns and concepts in self-attention and feed-forward layers. The impact of instruction tuning is then studied by comparing the explanations derived from the pre-trained and instruction-tuned models. This approach provides an internal perspective of the model shifts on a human-comprehensible level. Our findings reveal three significant impacts of instruction tuning: 1) It empowers LLMs to recognize the instruction parts of user prompts, and promotes the response generation constantly conditioned on the instructions. 2) It encourages the self-attention heads to capture more word-word relationships about instruction verbs. 3) It encourages the feed-forward networks to rotate their pre-trained knowledge toward user-oriented tasks. These insights contribute to a more comprehensive understanding of instruction tuning and lay the groundwork for future work that aims at explaining and optimizing LLMs for various applications. Our code and data are publicly available at https://github.com/JacksonWuxs/Interpret_Instruction_Tuning_LLMs.
4/5/2024
💬
BioInstruct: Instruction Tuning of Large Language Models for Biomedical Natural Language Processing
Hieu Tran, Zhichao Yang, Zonghai Yao, Hong Yu
0
0
To enhance the performance of large language models (LLMs) in biomedical natural language processing (BioNLP) by introducing a domain-specific instruction dataset and examining its impact when combined with multi-task learning principles. We created the BioInstruct, comprising 25,005 instructions to instruction-tune LLMs(LLaMA 1 & 2, 7B & 13B version). The instructions were created by prompting the GPT-4 language model with three-seed samples randomly drawn from an 80 human curated instructions. We employed Low-Rank Adaptation(LoRA) for parameter-efficient fine-tuning. We then evaluated these instruction-tuned LLMs on several BioNLP tasks, which can be grouped into three major categories: question answering(QA), information extraction(IE), and text generation(GEN). We also examined whether categories(e.g., QA, IE, and generation) of instructions impact model performance. Comparing with LLMs without instruction-tuned, our instruction-tuned LLMs demonstrated marked performance gains: 17.3% in QA, 5.7% in IE, and 96% in Generation tasks. Our 7B-parameter instruction-tuned LLaMA 1 model was competitive or even surpassed other LLMs in the biomedical domain that were also fine-tuned from LLaMA 1 with vast domain-specific data or a variety of tasks. Our results also show that the performance gain is significantly higher when instruction fine-tuning is conducted with closely related tasks. Our findings align with the observations of multi-task learning, suggesting the synergies between two tasks. The BioInstruct dataset serves as a valuable resource and instruction tuned LLMs lead to the best performing BioNLP applications.
6/10/2024
Instruction-tuned Language Models are Better Knowledge Learners
Zhengbao Jiang, Zhiqing Sun, Weijia Shi, Pedro Rodriguez, Chunting Zhou, Graham Neubig, Xi Victoria Lin, Wen-tau Yih, Srinivasan Iyer
0
0
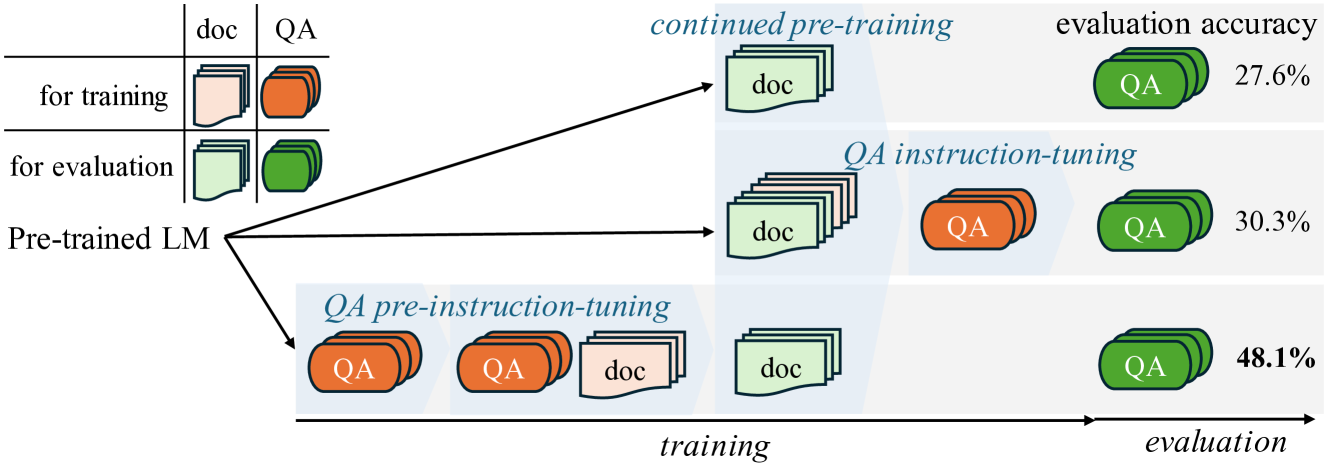
In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new data. The standard recipe for doing so involves continued pre-training on new documents followed by instruction-tuning on question-answer (QA) pairs. However, we find that LLMs trained with this recipe struggle to answer questions, even though the perplexity of documents is minimized. We found that QA pairs are generally straightforward, while documents are more complex, weaving many factual statements together in an intricate manner. Therefore, we hypothesize that it is beneficial to expose LLMs to QA pairs before continued pre-training on documents so that the process of encoding knowledge from complex documents takes into account how this knowledge is accessed through questions. Based on this, we propose pre-instruction-tuning (PIT), a method that instruction-tunes on questions prior to training on documents. This contrasts with standard instruction-tuning, which learns how to extract knowledge after training on documents. Extensive experiments and ablation studies demonstrate that pre-instruction-tuning significantly enhances the ability of LLMs to absorb knowledge from new documents, outperforming standard instruction-tuning by 17.8%.
5/28/2024