A Flexible, Equivariant Framework for Subgraph GNNs via Graph Products and Graph Coarsening

0

Sign in to get full access
Overview
- Presents a flexible and equivariant framework for subgraph Graph Neural Networks (GNNs) using graph products and graph coarsening
- Leverages the power of subgraph structures to improve the performance of GNNs on tasks involving hierarchical or structured data
- Introduces novel techniques for incorporating subgraph information into GNN architectures in an efficient and equivariant manner
Plain English Explanation
This research paper introduces a new approach for building Graph Neural Networks (GNNs) that can better handle tasks involving structured or hierarchical data. The key insight is to use the information about the subgraphs (smaller parts) within a larger graph to improve the performance of the GNN model.
The researchers propose a flexible and equivariant framework that allows for the incorporation of subgraph information into GNN architectures in an efficient manner. This is achieved through the use of graph products and graph coarsening techniques, which enable the model to capture the hierarchical structure of the input data.
By leveraging the power of subgraphs, the proposed framework can outperform traditional GNN approaches on tasks that involve complex, structured data, such as multi-view graph representation learning or improving the interpretability of GNN predictions.
Technical Explanation
The paper introduces a flexible and equivariant framework for subgraph GNNs that combines graph products and graph coarsening techniques. The key components of the framework are:
-
Graph Products: The researchers use graph products, such as the Cartesian product and the strong product, to incorporate subgraph information into the GNN architecture. This allows the model to learn representations that capture the hierarchical structure of the input data.
-
Graph Coarsening: The framework also employs graph coarsening, a technique that simplifies the input graph by merging nodes and edges, to efficiently process large-scale graphs. This helps to reduce the computational complexity of the GNN model while preserving the essential subgraph information.
-
Equivariance: The proposed framework ensures that the GNN model is equivariant to certain graph transformations, such as node permutations. This property is important for tasks where the relative position of nodes within the graph is crucial for making accurate predictions.
The paper demonstrates the effectiveness of the subgraph GNN framework on a variety of tasks, including node classification, graph classification, and link prediction. The experiments show that the proposed approach can outperform state-of-the-art GNN models, particularly on datasets that exhibit a strong hierarchical or structured nature.
Critical Analysis
The paper presents a well-designed and theoretically grounded framework for incorporating subgraph information into GNN architectures. The use of graph products and graph coarsening techniques is a novel and promising approach that can significantly improve the performance of GNNs on structured data tasks.
One potential limitation of the framework is its computational complexity, as the graph product operation can increase the size of the input graph exponentially. The authors address this issue by employing graph coarsening, but further research may be needed to optimize the efficiency of the overall framework.
Additionally, the paper does not discuss the interpretability of the subgraph GNN model's predictions. As previous research has shown, improving the interpretability of GNN models is an important area for future work.
Overall, the paper presents a flexible and equivariant framework that can serve as a powerful tool for researchers and practitioners working on graph-based machine learning tasks involving hierarchical or structured data.
Conclusion
The paper introduces a novel framework for subgraph GNNs that leverages graph products and graph coarsening to effectively incorporate subgraph information into GNN architectures. This approach can significantly improve the performance of GNNs on tasks that involve structured or hierarchical data, such as node classification, graph classification, and link prediction.
The key strengths of the proposed framework are its flexibility, equivariance, and ability to capture the hierarchical structure of the input data. By combining these techniques, the researchers have developed a powerful tool that can advance the state-of-the-art in graph-based machine learning. Further research on optimizing the computational efficiency and interpretability of the subgraph GNN model could lead to even more impactful applications in various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Flexible, Equivariant Framework for Subgraph GNNs via Graph Products and Graph Coarsening
Guy Bar-Shalom, Yam Eitan, Fabrizio Frasca, Haggai Maron
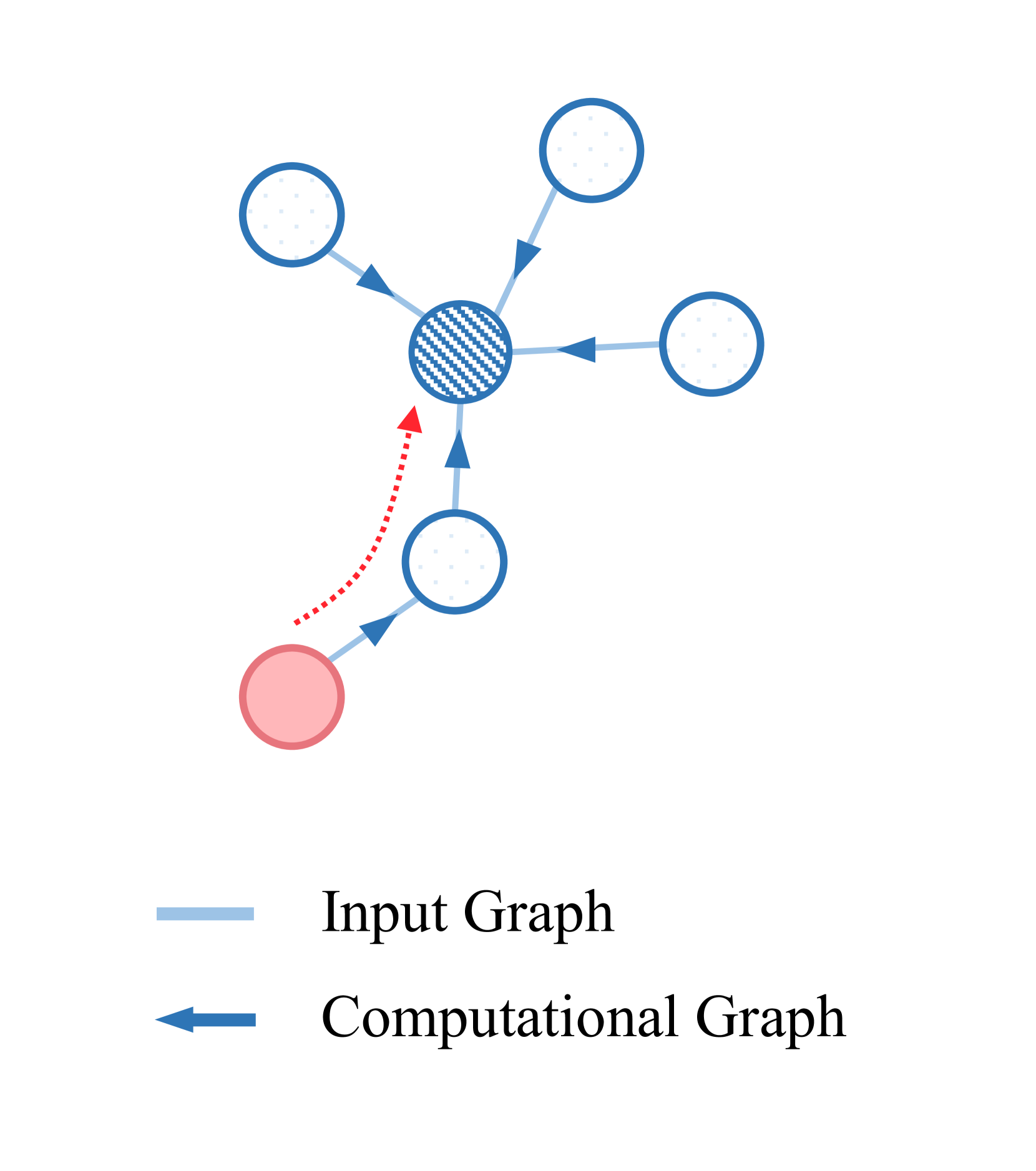
Subgraph Graph Neural Networks (Subgraph GNNs) enhance the expressivity of message-passing GNNs by representing graphs as sets of subgraphs. They have shown impressive performance on several tasks, but their complexity limits applications to larger graphs. Previous approaches suggested processing only subsets of subgraphs, selected either randomly or via learnable sampling. However, they make suboptimal subgraph selections or can only cope with very small subset sizes, inevitably incurring performance degradation. This paper introduces a new Subgraph GNNs framework to address these issues. We employ a graph coarsening function to cluster nodes into super-nodes with induced connectivity. The product between the coarsened and the original graph reveals an implicit structure whereby subgraphs are associated with specific sets of nodes. By running generalized message-passing on such graph product, our method effectively implements an efficient, yet powerful Subgraph GNN. Controlling the coarsening function enables meaningful selection of any number of subgraphs while, contrary to previous methods, being fully compatible with standard training techniques. Notably, we discover that the resulting node feature tensor exhibits new, unexplored permutation symmetries. We leverage this structure, characterize the associated linear equivariant layers and incorporate them into the layers of our Subgraph GNN architecture. Extensive experiments on multiple graph learning benchmarks demonstrate that our method is significantly more flexible than previous approaches, as it can seamlessly handle any number of subgraphs, while consistently outperforming baseline approaches.
Read more8/23/2024
⛏️
0
Subgraphormer: Unifying Subgraph GNNs and Graph Transformers via Graph Products
Guy Bar-Shalom, Beatrice Bevilacqua, Haggai Maron
In the realm of Graph Neural Networks (GNNs), two exciting research directions have recently emerged: Subgraph GNNs and Graph Transformers. In this paper, we propose an architecture that integrates both approaches, dubbed Subgraphormer, which combines the enhanced expressive power, message-passing mechanisms, and aggregation schemes from Subgraph GNNs with attention and positional encodings, arguably the most important components in Graph Transformers. Our method is based on an intriguing new connection we reveal between Subgraph GNNs and product graphs, suggesting that Subgraph GNNs can be formulated as Message Passing Neural Networks (MPNNs) operating on a product of the graph with itself. We use this formulation to design our architecture: first, we devise an attention mechanism based on the connectivity of the product graph. Following this, we propose a novel and efficient positional encoding scheme for Subgraph GNNs, which we derive as a positional encoding for the product graph. Our experimental results demonstrate significant performance improvements over both Subgraph GNNs and Graph Transformers on a wide range of datasets.
Read more5/29/2024
0
Scalable Graph Compressed Convolutions
Junshu Sun, Chenxue Yang, Shuhui Wang, Qingming Huang
Designing effective graph neural networks (GNNs) with message passing has two fundamental challenges, i.e., determining optimal message-passing pathways and designing local aggregators. Previous methods of designing optimal pathways are limited with information loss on the input features. On the other hand, existing local aggregators generally fail to extract multi-scale features and approximate diverse operators under limited parameter scales. In contrast to these methods, Euclidean convolution has been proven as an expressive aggregator, making it a perfect candidate for GNN construction. However, the challenges of generalizing Euclidean convolution to graphs arise from the irregular structure of graphs. To bridge the gap between Euclidean space and graph topology, we propose a differentiable method that applies permutations to calibrate input graphs for Euclidean convolution. The permutations constrain all nodes in a row regardless of their input order and therefore enable the flexible generalization of Euclidean convolution to graphs. Based on the graph calibration, we propose the Compressed Convolution Network (CoCN) for hierarchical graph representation learning. CoCN follows local feature-learning and global parameter-sharing mechanisms of convolution neural networks. The whole model can be trained end-to-end, with compressed convolution applied to learn individual node features and their corresponding structure features. CoCN can further borrow successful practices from Euclidean convolution, including residual connection and inception mechanism. We validate CoCN on both node-level and graph-level benchmarks. CoCN achieves superior performance over competitive GNN baselines. Codes are available at https://github.com/sunjss/CoCN.
Read more7/29/2024
🧠
0
Sketch-GNN: Scalable Graph Neural Networks with Sublinear Training Complexity
Mucong Ding, Tahseen Rabbani, Bang An, Evan Z Wang, Furong Huang
Graph Neural Networks (GNNs) are widely applied to graph learning problems such as node classification. When scaling up the underlying graphs of GNNs to a larger size, we are forced to either train on the complete graph and keep the full graph adjacency and node embeddings in memory (which is often infeasible) or mini-batch sample the graph (which results in exponentially growing computational complexities with respect to the number of GNN layers). Various sampling-based and historical-embedding-based methods are proposed to avoid this exponential growth of complexities. However, none of these solutions eliminates the linear dependence on graph size. This paper proposes a sketch-based algorithm whose training time and memory grow sublinearly with respect to graph size by training GNNs atop a few compact sketches of graph adjacency and node embeddings. Based on polynomial tensor-sketch (PTS) theory, our framework provides a novel protocol for sketching non-linear activations and graph convolution matrices in GNNs, as opposed to existing methods that sketch linear weights or gradients in neural networks. In addition, we develop a locality-sensitive hashing (LSH) technique that can be trained to improve the quality of sketches. Experiments on large-graph benchmarks demonstrate the scalability and competitive performance of our Sketch-GNNs versus their full-size GNN counterparts.
Read more6/26/2024