Flexible Motion In-betweening with Diffusion Models
2405.11126
0
0

Abstract
Motion in-betweening, a fundamental task in character animation, consists of generating motion sequences that plausibly interpolate user-provided keyframe constraints. It has long been recognized as a labor-intensive and challenging process. We investigate the potential of diffusion models in generating diverse human motions guided by keyframes. Unlike previous inbetweening methods, we propose a simple unified model capable of generating precise and diverse motions that conform to a flexible range of user-specified spatial constraints, as well as text conditioning. To this end, we propose Conditional Motion Diffusion In-betweening (CondMDI) which allows for arbitrary dense-or-sparse keyframe placement and partial keyframe constraints while generating high-quality motions that are diverse and coherent with the given keyframes. We evaluate the performance of CondMDI on the text-conditioned HumanML3D dataset and demonstrate the versatility and efficacy of diffusion models for keyframe in-betweening. We further explore the use of guidance and imputation-based approaches for inference-time keyframing and compare CondMDI against these methods.
Create account to get full access
Overview
- This paper proposes a flexible and efficient motion in-betweening method using diffusion models.
- Diffusion models are a type of generative machine learning model that can generate high-quality, realistic images by gradually adding noise to data and then learning to reverse the process.
- The authors show how diffusion models can be adapted to generate smooth, natural-looking motion sequences between keyframes.
- This allows for more flexible and controllable motion generation compared to traditional methods.
Plain English Explanation
The paper introduces a new way to create animations, using a type of AI model called a diffusion model. Diffusion models are good at generating realistic images by starting with random noise and then gradually refining it into a specific image.
The key insight of this work is that diffusion models can also be used to generate smooth, natural-looking motion sequences between keyframes - the starting and ending positions of a character's movement. This allows animators and motion designers to have more control and flexibility over the motion, compared to traditional techniques.
Instead of having to manually fill in all the in-between frames, the diffusion model can automatically generate the intermediate motions in a realistic way. This could save a lot of time and effort in the animation process.
The paper demonstrates how this diffusion-based motion in-betweening approach can produce high-quality results, handling a variety of different motions and styles. It's an exciting development that could have significant impact on the animation industry and how motion is created for games, films, and other media.
Technical Explanation
The paper proposes a motion-aware latent diffusion model for flexible and efficient motion in-betweening. The key idea is to leverage the powerful generative capabilities of diffusion models, which have shown impressive results in generating realistic images, and adapt them to the motion generation domain.
The authors design a motion-aware diffusion model that can generate plausible intermediate motion frames given only the start and end keyframes. This is achieved by conditioning the diffusion process on the motion information encoded in the keyframes, allowing the model to learn the underlying dynamics and temporal coherence of the motion.
Experiments demonstrate that the proposed method can generate smooth, natural-looking motions for a variety of human poses and styles, outperforming previous motion in-betweening approaches. The model is also shown to be efficient, allowing for real-time motion generation from user inputs.
Critical Analysis
The paper presents a promising approach for flexible and efficient motion in-betweening using diffusion models. However, there are a few potential limitations and areas for further research:
-
The method is currently limited to human motion and may require adaptations to handle more diverse types of motion, such as animal locomotion or rigid-body dynamics.
-
The paper does not explore the model's ability to generalize to unseen motion styles or handle large variations in the input keyframes. Further investigation into the model's robustness and generalization capabilities would be valuable.
-
While the method is shown to be efficient, there may still be opportunities for further optimization, especially for real-time applications with tight computational constraints.
-
The paper does not address the potential ethical considerations around the use of AI-generated motion, such as concerns about the authenticity or potential misuse of synthetic animations.
Overall, the proposed diffusion-based motion in-betweening approach is a promising direction that could significantly impact the animation industry and how motion is created for various applications. Addressing the above limitations and exploring the wider implications of this technology will be important areas for future research.
Conclusion
This paper presents a novel approach to motion in-betweening using diffusion models, a powerful class of generative AI models. By conditioning the diffusion process on motion information, the authors have developed a flexible and efficient method for generating smooth, natural-looking intermediate motions between keyframes.
The proposed technique has the potential to revolutionize the animation workflow, allowing animators and motion designers to have more control and flexibility over the motion generation process. This could lead to significant time and cost savings, as well as enable new types of motion-driven applications and experiences.
While the current method is focused on human motion, the underlying principles could be extended to a wider range of motion types and styles. Continued research and development in this area could further enhance the capabilities of AI-powered motion generation, ultimately transforming how we create and interact with animated content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Shape Conditioned Human Motion Generation with Diffusion Model
Kebing Xue, Hyewon Seo
0
0
Human motion synthesis is an important task in computer graphics and computer vision. While focusing on various conditioning signals such as text, action class, or audio to guide the generation process, most existing methods utilize skeleton-based pose representation, requiring additional skinning to produce renderable meshes. Given that human motion is a complex interplay of bones, joints, and muscles, considering solely the skeleton for generation may neglect their inherent interdependency, which can limit the variability and precision of the generated results. To address this issue, we propose a Shape-conditioned Motion Diffusion model (SMD), which enables the generation of motion sequences directly in mesh format, conditioned on a specified target mesh. In SMD, the input meshes are transformed into spectral coefficients using graph Laplacian, to efficiently represent meshes. Subsequently, we propose a Spectral-Temporal Autoencoder (STAE) to leverage cross-temporal dependencies within the spectral domain. Extensive experimental evaluations show that SMD not only produces vivid and realistic motions but also achieves competitive performance in text-to-motion and action-to-motion tasks when compared to state-of-the-art methods.
5/14/2024
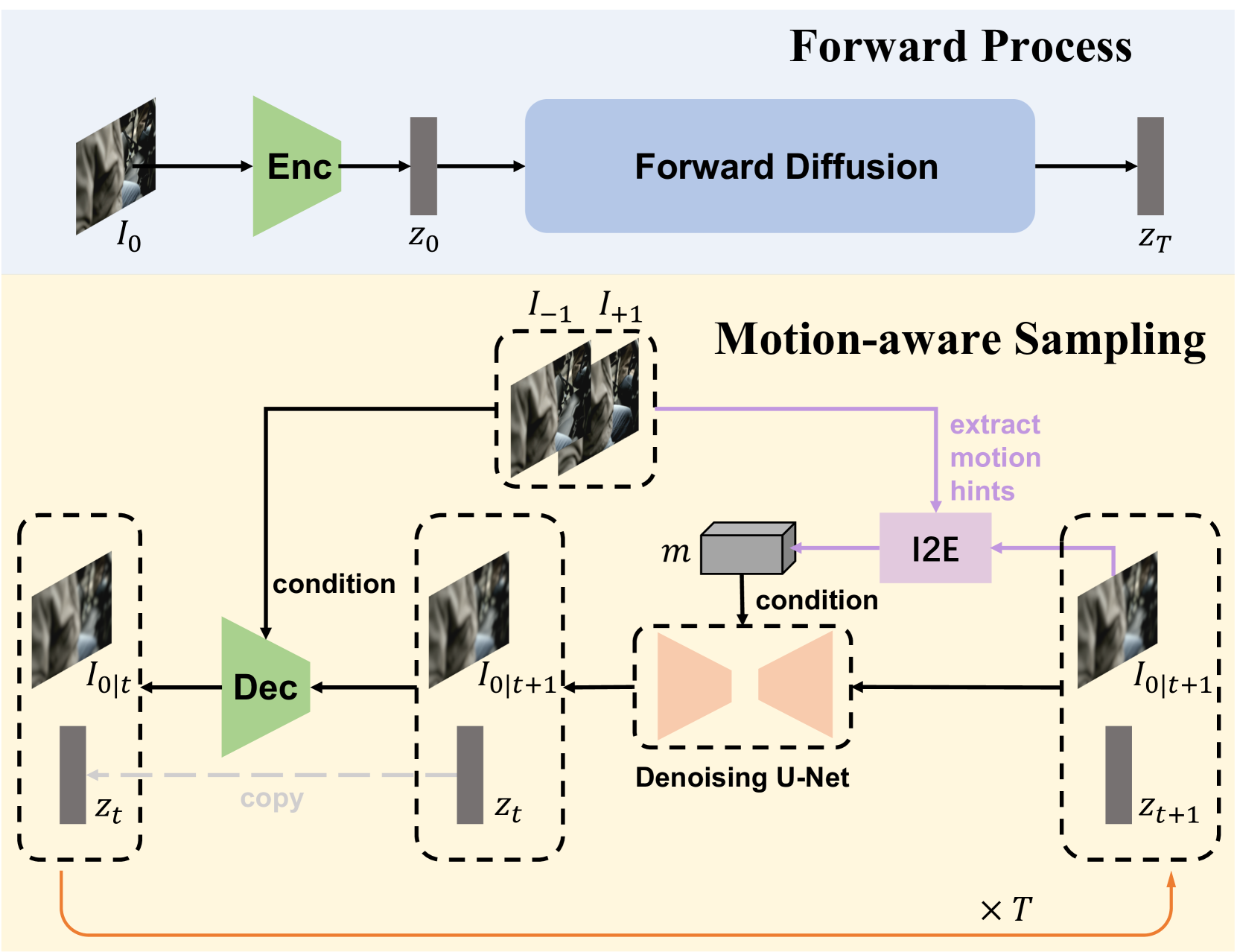
Motion-aware Latent Diffusion Models for Video Frame Interpolation
Zhilin Huang, Yijie Yu, Ling Yang, Chujun Qin, Bing Zheng, Xiawu Zheng, Zikun Zhou, Yaowei Wang, Wenming Yang
0
0
With the advancement of AIGC, video frame interpolation (VFI) has become a crucial component in existing video generation frameworks, attracting widespread research interest. For the VFI task, the motion estimation between neighboring frames plays a crucial role in avoiding motion ambiguity. However, existing VFI methods always struggle to accurately predict the motion information between consecutive frames, and this imprecise estimation leads to blurred and visually incoherent interpolated frames. In this paper, we propose a novel diffusion framework, motion-aware latent diffusion models (MADiff), which is specifically designed for the VFI task. By incorporating motion priors between the conditional neighboring frames with the target interpolated frame predicted throughout the diffusion sampling procedure, MADiff progressively refines the intermediate outcomes, culminating in generating both visually smooth and realistic results. Extensive experiments conducted on benchmark datasets demonstrate that our method achieves state-of-the-art performance significantly outperforming existing approaches, especially under challenging scenarios involving dynamic textures with complex motion.
6/5/2024
🐍
Taming Diffusion Probabilistic Models for Character Control
Rui Chen, Mingyi Shi, Shaoli Huang, Ping Tan, Taku Komura, Xuelin Chen
0
0
We present a novel character control framework that effectively utilizes motion diffusion probabilistic models to generate high-quality and diverse character animations, responding in real-time to a variety of dynamic user-supplied control signals. At the heart of our method lies a transformer-based Conditional Autoregressive Motion Diffusion Model (CAMDM), which takes as input the character's historical motion and can generate a range of diverse potential future motions conditioned on high-level, coarse user control. To meet the demands for diversity, controllability, and computational efficiency required by a real-time controller, we incorporate several key algorithmic designs. These include separate condition tokenization, classifier-free guidance on past motion, and heuristic future trajectory extension, all designed to address the challenges associated with taming motion diffusion probabilistic models for character control. As a result, our work represents the first model that enables real-time generation of high-quality, diverse character animations based on user interactive control, supporting animating the character in multiple styles with a single unified model. We evaluate our method on a diverse set of locomotion skills, demonstrating the merits of our method over existing character controllers. Project page and source codes: https://aiganimation.github.io/CAMDM/
4/24/2024
🔄
On-the-fly Learning to Transfer Motion Style with Diffusion Models: A Semantic Guidance Approach
Lei Hu, Zihao Zhang, Yongjing Ye, Yiwen Xu, Shihong Xia
0
0
In recent years, the emergence of generative models has spurred development of human motion generation, among which the generation of stylized human motion has consistently been a focal point of research. The conventional approach for stylized human motion generation involves transferring the style from given style examples to new motions. Despite decades of research in human motion style transfer, it still faces three main challenges: 1) difficulties in decoupling the motion content and style; 2) generalization to unseen motion style. 3) requirements of dedicated motion style dataset; To address these issues, we propose an on-the-fly human motion style transfer learning method based on the diffusion model, which can learn a style transfer model in a few minutes of fine-tuning to transfer an unseen style to diverse content motions. The key idea of our method is to consider the denoising process of the diffusion model as a motion translation process that learns the difference between the style-neutral motion pair, thereby avoiding the challenge of style and content decoupling. Specifically, given an unseen style example, we first generate the corresponding neutral motion through the proposed Style-Neutral Motion Pair Generation module. We then add noise to the generated neutral motion and denoise it to be close to the style example to fine-tune the style transfer diffusion model. We only need one style example and a text-to-motion dataset with predominantly neutral motion (e.g. HumanML3D). The qualitative and quantitative evaluations demonstrate that our method can achieve state-of-the-art performance and has practical applications.
5/14/2024