FlexiDreamer: Single Image-to-3D Generation with FlexiCubes

0
Sign in to get full access
Overview
- Proposes a novel 3D generation model called FlexiDreamer that can generate 3D objects from a single 2D input image
- Introduces a flexible cube representation called FlexiCubes that allows for efficient and fine-grained 3D generation
- Demonstrates state-of-the-art results on single image-to-3D generation benchmarks
Plain English Explanation
The paper introduces a new AI system called FlexiDreamer that can create 3D models from a single 2D photo. This is a challenging task, as going from a flat, 2D image to a full 3D object requires a lot of inferred information about the shape, depth, and structure of the object.
To tackle this, the researchers developed a novel representation called FlexiCubes. Instead of trying to generate a complete 3D mesh all at once, FlexiDreamer breaks the 3D object down into a collection of small, flexible cubes. These cubes can then be adjusted and positioned to match the shape of the object in the 2D photo.
This flexible, modular approach has several key advantages. It allows for efficient and detailed 3D generation, as the model only needs to predict the position and shape of each individual cube, rather than an entire complex 3D mesh. It also gives the generated 3D objects a high degree of fine-grained detail and flexibility, as the cubes can be adjusted and rearranged in various ways.
The researchers demonstrate that FlexiDreamer achieves state-of-the-art results on standard benchmarks for single image-to-3D generation. This is an important advance, as being able to quickly and accurately create 3D models from 2D photos has many practical applications, from 3D content creation to augmented reality.
Technical Explanation
The key technical innovation in this paper is the FlexiCubes representation. Rather than trying to generate a complete 3D mesh from a single 2D input image, the FlexiDreamer model instead predicts a collection of small, flexible 3D cube primitives that can be assembled to form the final 3D object.
Specifically, the model takes in a 2D input image and encodes it using a convolutional neural network. It then predicts a set of parameters for each FlexiCube, including its position, size, orientation, and deformation. These cubes are then arranged and deformed to match the shape of the object in the input image.
The use of this flexible, modular representation has several key advantages over traditional 3D generation approaches:
- Efficiency: By only predicting the parameters of individual cubes rather than an entire 3D mesh, the model is able to generate detailed 3D objects much more efficiently.
- Fine-grained control: The ability to adjust the position, size, and deformation of each cube individually allows for a high degree of fine-grained control and detail in the generated 3D models.
- Generalization: The modular nature of the FlexiCubes representation means the model can more easily generalize to a wide variety of 3D object shapes and structures, rather than being limited to a specific type of 3D geometry.
The researchers evaluate FlexiDreamer on standard single image-to-3D generation benchmarks and show that it outperforms previous state-of-the-art methods. They also provide ablation studies and qualitative results demonstrating the flexibility and expressiveness of the FlexiCubes representation.
Critical Analysis
The FlexiDreamer model represents a promising advance in single image-to-3D generation, with the FlexiCubes representation offering significant advantages over previous approaches. However, the paper also acknowledges several limitations and areas for future work.
One key limitation is that the current model is trained and evaluated on a relatively limited dataset of 3D object categories. While the modular FlexiCubes representation is designed to generalize, the researchers note that further work is needed to scale the model to handle an even wider diversity of 3D object types and structures.
Additionally, the paper does not delve deeply into the computational and memory efficiency of the FlexiDreamer model compared to alternative 3D generation approaches. As real-world applications often have strict resource constraints, further analysis of the model's efficiency would be valuable.
Some other potential areas for improvement include enhancing the realism and physical plausibility of the generated 3D objects, as well as exploring ways to incorporate user guidance or interaction into the 3D generation process.
Overall, the FlexiDreamer model represents an exciting step forward in single image-to-3D generation, with the FlexiCubes representation offering a flexible and efficient approach to this challenging problem. Further research building on these ideas could lead to even more powerful and versatile 3D generation capabilities.
Conclusion
The FlexiDreamer model introduced in this paper represents a significant advancement in the field of single image-to-3D generation. By leveraging a novel FlexiCubes representation, the model is able to generate detailed and flexible 3D objects from a single 2D input image.
The key benefits of the FlexiCubes approach include its efficiency, fine-grained control, and ability to generalize to a wide variety of 3D object shapes and structures. The researchers demonstrate state-of-the-art results on benchmark tasks, showcasing the power and potential of this new 3D generation technique.
While the paper identifies some limitations and areas for future work, the FlexiDreamer model nonetheless represents an important step forward in the quest to create advanced AI systems that can seamlessly translate between 2D and 3D representations. As 3D content and virtual environments become increasingly prevalent, tools like FlexiDreamer will be crucial for enabling more efficient and accessible 3D content creation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FlexiDreamer: Single Image-to-3D Generation with FlexiCubes
Ruowen Zhao, Zhengyi Wang, Yikai Wang, Zihan Zhou, Jun Zhu
3D content generation has wide applications in various fields. One of its dominant paradigms is by sparse-view reconstruction using multi-view images generated by diffusion models. However, since directly reconstructing triangle meshes from multi-view images is challenging, most methodologies opt to an implicit representation (such as NeRF) during the sparse-view reconstruction and acquire the target mesh by a post-processing extraction. However, the implicit representation takes extensive time to train and the post-extraction also leads to undesirable visual artifacts. In this paper, we propose FlexiDreamer, a novel framework that directly reconstructs high-quality meshes from multi-view generated images. We utilize an advanced gradient-based mesh optimization, namely FlexiCubes, for multi-view mesh reconstruction, which enables us to generate 3D meshes in an end-to-end manner. To address the reconstruction artifacts owing to the inconsistencies from generated images, we design a hybrid positional encoding scheme to improve the reconstruction geometry and an orientation-aware texture mapping to mitigate surface ghosting. To further enhance the results, we respectively incorporate eikonal and smooth regularizations to reduce geometric holes and surface noise. Our approach can generate high-fidelity 3D meshes in the single image-to-3D downstream task with approximately 1 minute, significantly outperforming previous methods.
Read more5/28/2024

0
Unique3D: High-Quality and Efficient 3D Mesh Generation from a Single Image
Kailu Wu, Fangfu Liu, Zhihan Cai, Runjie Yan, Hanyang Wang, Yating Hu, Yueqi Duan, Kaisheng Ma
In this work, we introduce Unique3D, a novel image-to-3D framework for efficiently generating high-quality 3D meshes from single-view images, featuring state-of-the-art generation fidelity and strong generalizability. Previous methods based on Score Distillation Sampling (SDS) can produce diversified 3D results by distilling 3D knowledge from large 2D diffusion models, but they usually suffer from long per-case optimization time with inconsistent issues. Recent works address the problem and generate better 3D results either by finetuning a multi-view diffusion model or training a fast feed-forward model. However, they still lack intricate textures and complex geometries due to inconsistency and limited generated resolution. To simultaneously achieve high fidelity, consistency, and efficiency in single image-to-3D, we propose a novel framework Unique3D that includes a multi-view diffusion model with a corresponding normal diffusion model to generate multi-view images with their normal maps, a multi-level upscale process to progressively improve the resolution of generated orthographic multi-views, as well as an instant and consistent mesh reconstruction algorithm called ISOMER, which fully integrates the color and geometric priors into mesh results. Extensive experiments demonstrate that our Unique3D significantly outperforms other image-to-3D baselines in terms of geometric and textural details.
Read more6/14/2024
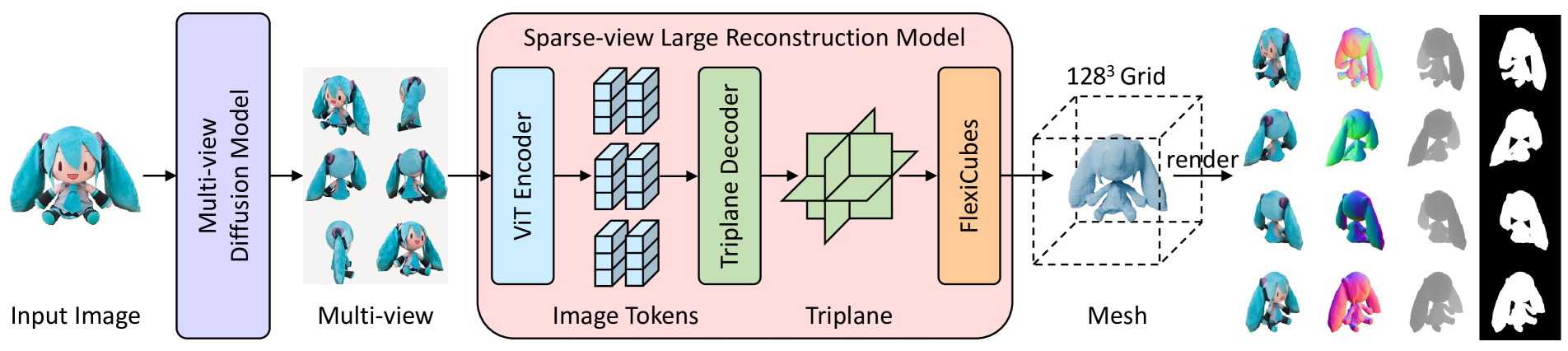
1
InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, Ying Shan
We present InstantMesh, a feed-forward framework for instant 3D mesh generation from a single image, featuring state-of-the-art generation quality and significant training scalability. By synergizing the strengths of an off-the-shelf multiview diffusion model and a sparse-view reconstruction model based on the LRM architecture, InstantMesh is able to create diverse 3D assets within 10 seconds. To enhance the training efficiency and exploit more geometric supervisions, e.g, depths and normals, we integrate a differentiable iso-surface extraction module into our framework and directly optimize on the mesh representation. Experimental results on public datasets demonstrate that InstantMesh significantly outperforms other latest image-to-3D baselines, both qualitatively and quantitatively. We release all the code, weights, and demo of InstantMesh, with the intention that it can make substantial contributions to the community of 3D generative AI and empower both researchers and content creators.
Read more4/16/2024

0
VI3DRM:Towards meticulous 3D Reconstruction from Sparse Views via Photo-Realistic Novel View Synthesis
Hao Chen, Jiafu Wu, Ying Jin, Jinlong Peng, Xiaofeng Mao, Mingmin Chi, Mufeng Yao, Bo Peng, Jian Li, Yun Cao
Recently, methods like Zero-1-2-3 have focused on single-view based 3D reconstruction and have achieved remarkable success. However, their predictions for unseen areas heavily rely on the inductive bias of large-scale pretrained diffusion models. Although subsequent work, such as DreamComposer, attempts to make predictions more controllable by incorporating additional views, the results remain unrealistic due to feature entanglement in the vanilla latent space, including factors such as lighting, material, and structure. To address these issues, we introduce the Visual Isotropy 3D Reconstruction Model (VI3DRM), a diffusion-based sparse views 3D reconstruction model that operates within an ID consistent and perspective-disentangled 3D latent space. By facilitating the disentanglement of semantic information, color, material properties and lighting, VI3DRM is capable of generating highly realistic images that are indistinguishable from real photographs. By leveraging both real and synthesized images, our approach enables the accurate construction of pointmaps, ultimately producing finely textured meshes or point clouds. On the NVS task, tested on the GSO dataset, VI3DRM significantly outperforms state-of-the-art method DreamComposer, achieving a PSNR of 38.61, an SSIM of 0.929, and an LPIPS of 0.027. Code will be made available upon publication.
Read more9/14/2024