InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models
2404.07191
2
0
Abstract
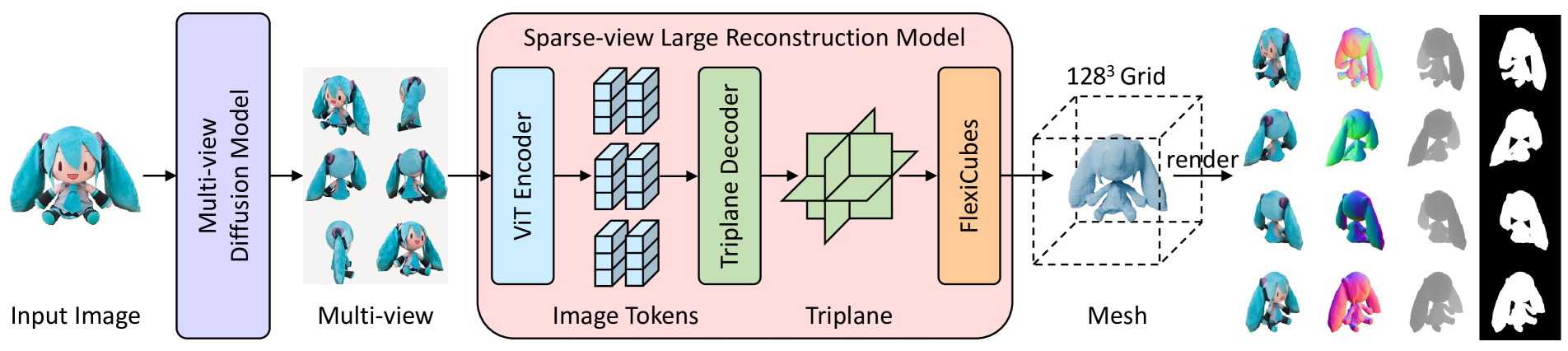
We present InstantMesh, a feed-forward framework for instant 3D mesh generation from a single image, featuring state-of-the-art generation quality and significant training scalability. By synergizing the strengths of an off-the-shelf multiview diffusion model and a sparse-view reconstruction model based on the LRM architecture, InstantMesh is able to create diverse 3D assets within 10 seconds. To enhance the training efficiency and exploit more geometric supervisions, e.g, depths and normals, we integrate a differentiable iso-surface extraction module into our framework and directly optimize on the mesh representation. Experimental results on public datasets demonstrate that InstantMesh significantly outperforms other latest image-to-3D baselines, both qualitatively and quantitatively. We release all the code, weights, and demo of InstantMesh, with the intention that it can make substantial contributions to the community of 3D generative AI and empower both researchers and content creators.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents InstantMesh, a method for efficiently generating 3D meshes from a single image using sparse-view large reconstruction models.
- The key innovation is the ability to produce high-quality 3D meshes from a single image, without requiring multiple input views or expensive computational resources.
- The approach leverages recent advances in large-scale 3D reconstruction models that can handle sparse input data, enabling efficient 3D mesh generation from a single image.
Plain English Explanation
The paper describes a new method called InstantMesh that can create 3D models, or meshes, from a single photograph. This is a significant improvement over previous methods that required multiple images or complex computational resources to generate 3D content.
The core idea behind InstantMesh is to use large-scale 3D reconstruction models that are specifically designed to work with sparse input data, meaning they can generate 3D information from just a single image. This allows for efficient and high-quality 3D mesh generation from a single photograph, without needing to capture multiple views or perform extensive computations.
The advantage of this approach is that it enables quick and easy 3D content creation from readily available single-image data, which could be useful for a variety of applications, such as InstantAvatar, InstantSplat, Learning Topology Uniformed Face Mesh by Volume, G3DR, and DreamScene360.
Technical Explanation
The key technical innovation behind InstantMesh is its ability to leverage large-scale 3D reconstruction models that can handle sparse input data, such as a single image. This is in contrast to traditional methods that often require multiple input views or complex computational resources to generate 3D meshes.
The paper demonstrates that by using these sparse-view large reconstruction models, InstantMesh can efficiently produce high-quality 3D meshes from a single image. This is accomplished by leveraging the powerful capabilities of these large-scale models, which have been trained on extensive datasets to extract 3D information from limited input data.
The authors evaluate the performance of InstantMesh on various benchmarks and demonstrate its ability to generate accurate and visually appealing 3D meshes from single-image inputs. The results show that InstantMesh can achieve competitive performance compared to more resource-intensive traditional methods, while offering significant efficiency advantages.
Critical Analysis
The paper presents a promising approach for efficient 3D mesh generation from single-image inputs, leveraging the capabilities of large-scale sparse-view reconstruction models. However, the authors acknowledge that the performance of InstantMesh may be limited by the inherent challenges of working with a single image, which can lack the depth and context information available in multi-view or depth-based inputs.
Additionally, the paper does not provide a comprehensive analysis of the limitations or potential failure cases of the InstantMesh approach. It would be valuable to explore the scenarios where the method may struggle, such as handling occlusions, complex geometries, or diverse object categories beyond the evaluated benchmarks.
Further research could also investigate ways to enhance the quality and robustness of the generated 3D meshes, potentially by incorporating additional constraints or refinement techniques. Exploring the integration of InstantMesh with other 3D reconstruction or editing workflows could also broaden its applicability and impact.
Conclusion
The InstantMesh approach presented in this paper represents a significant advance in efficient 3D mesh generation from single-image inputs. By leveraging large-scale sparse-view reconstruction models, the method can produce high-quality 3D meshes without the need for multiple input views or extensive computational resources.
This innovation could have far-reaching implications, enabling more widespread and accessible 3D content creation from readily available single-image data. The potential applications of InstantMesh span a wide range of domains, from virtual reality and game development to facial reconstruction and scene generation.
As the field of 3D reconstruction continues to evolve, the InstantMesh approach represents an important step towards more efficient and accessible 3D content creation, with the potential to democratize 3D modeling and spur further advancements in generative 3D reconstruction.
Related Papers
📈
MeshLRM: Large Reconstruction Model for High-Quality Mesh
Xinyue Wei, Kai Zhang, Sai Bi, Hao Tan, Fujun Luan, Valentin Deschaintre, Kalyan Sunkavalli, Hao Su, Zexiang Xu
0
0
We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute. Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation. Project page: https://sarahweiii.github.io/meshlrm/
4/19/2024
🤷
InstantAvatar: Efficient 3D Head Reconstruction via Surface Rendering
Antonio Canela, Pol Caselles, Ibrar Malik, Eduard Ramon, Jaime Garc'ia, Jordi S'anchez-Riera, Gil Triginer, Francesc Moreno-Noguer
0
0
Recent advances in full-head reconstruction have been obtained by optimizing a neural field through differentiable surface or volume rendering to represent a single scene. While these techniques achieve an unprecedented accuracy, they take several minutes, or even hours, due to the expensive optimization process required. In this work, we introduce InstantAvatar, a method that recovers full-head avatars from few images (down to just one) in a few seconds on commodity hardware. In order to speed up the reconstruction process, we propose a system that combines, for the first time, a voxel-grid neural field representation with a surface renderer. Notably, a naive combination of these two techniques leads to unstable optimizations that do not converge to valid solutions. In order to overcome this limitation, we present a novel statistical model that learns a prior distribution over 3D head signed distance functions using a voxel-grid based architecture. The use of this prior model, in combination with other design choices, results into a system that achieves 3D head reconstructions with comparable accuracy as the state-of-the-art with a 100x speed-up.
4/8/2024
🛸
Instant3D: Instant Text-to-3D Generation
Ming Li, Pan Zhou, Jia-Wei Liu, Jussi Keppo, Min Lin, Shuicheng Yan, Xiangyu Xu
0
0
Text-to-3D generation has attracted much attention from the computer vision community. Existing methods mainly optimize a neural field from scratch for each text prompt, relying on heavy and repetitive training cost which impedes their practical deployment. In this paper, we propose a novel framework for fast text-to-3D generation, dubbed Instant3D. Once trained, Instant3D is able to create a 3D object for an unseen text prompt in less than one second with a single run of a feedforward network. We achieve this remarkable speed by devising a new network that directly constructs a 3D triplane from a text prompt. The core innovation of our Instant3D lies in our exploration of strategies to effectively inject text conditions into the network. In particular, we propose to combine three key mechanisms: cross-attention, style injection, and token-to-plane transformation, which collectively ensure precise alignment of the output with the input text. Furthermore, we propose a simple yet effective activation function, the scaled-sigmoid, to replace the original sigmoid function, which speeds up the training convergence by more than ten times. Finally, to address the Janus (multi-head) problem in 3D generation, we propose an adaptive Perp-Neg algorithm that can dynamically adjust its concept negation scales according to the severity of the Janus problem during training, effectively reducing the multi-head effect. Extensive experiments on a wide variety of benchmark datasets demonstrate that the proposed algorithm performs favorably against the state-of-the-art methods both qualitatively and quantitatively, while achieving significantly better efficiency. The code, data, and models are available at https://github.com/ming1993li/Instant3DCodes.
4/30/2024
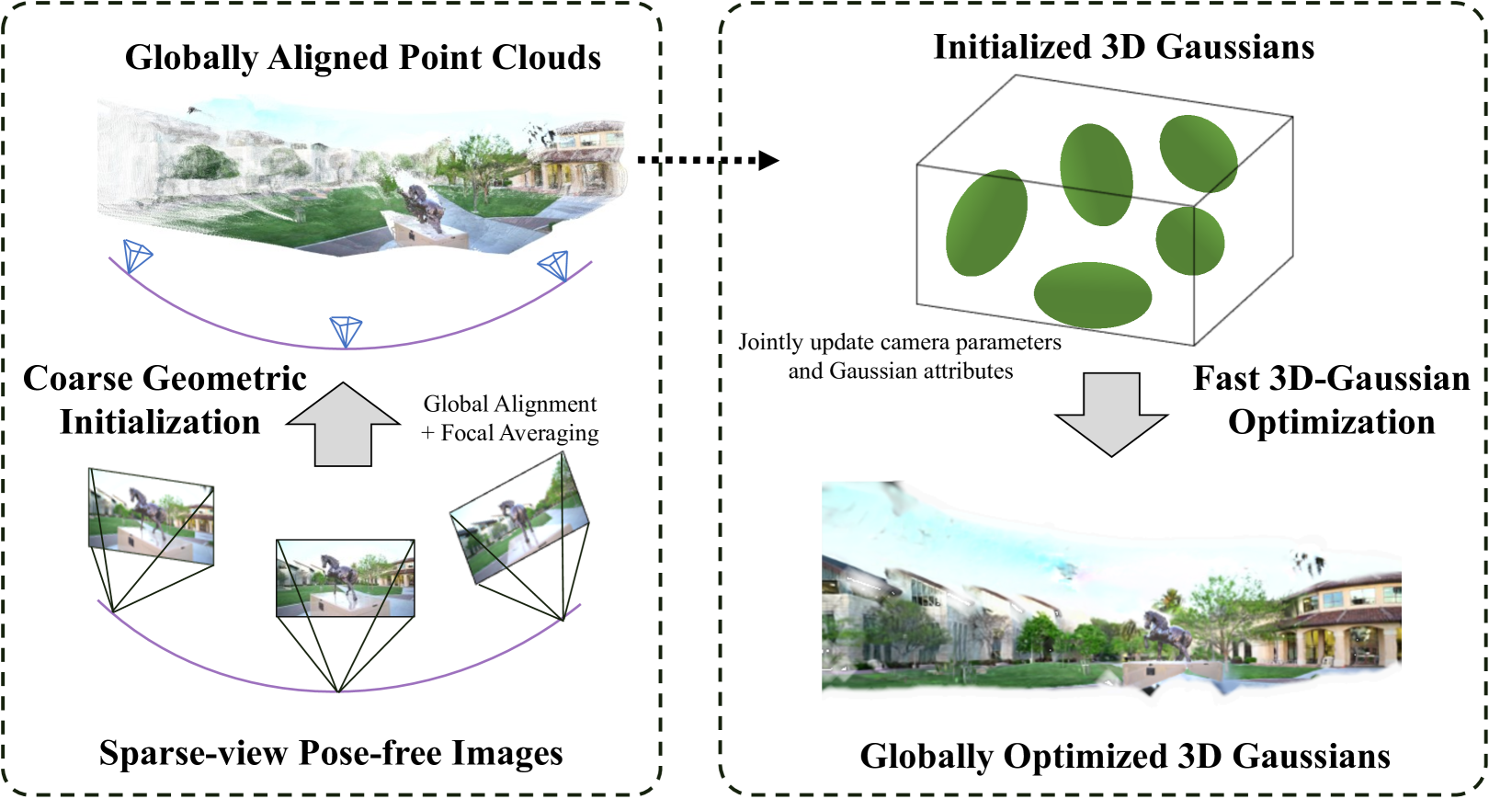
InstantSplat: Unbounded Sparse-view Pose-free Gaussian Splatting in 40 Seconds
Zhiwen Fan, Wenyan Cong, Kairun Wen, Kevin Wang, Jian Zhang, Xinghao Ding, Danfei Xu, Boris Ivanovic, Marco Pavone, Georgios Pavlakos, Zhangyang Wang, Yue Wang
0
0
While novel view synthesis (NVS) has made substantial progress in 3D computer vision, it typically requires an initial estimation of camera intrinsics and extrinsics from dense viewpoints. This pre-processing is usually conducted via a Structure-from-Motion (SfM) pipeline, a procedure that can be slow and unreliable, particularly in sparse-view scenarios with insufficient matched features for accurate reconstruction. In this work, we integrate the strengths of point-based representations (e.g., 3D Gaussian Splatting, 3D-GS) with end-to-end dense stereo models (DUSt3R) to tackle the complex yet unresolved issues in NVS under unconstrained settings, which encompasses pose-free and sparse view challenges. Our framework, InstantSplat, unifies dense stereo priors with 3D-GS to build 3D Gaussians of large-scale scenes from sparseview & pose-free images in less than 1 minute. Specifically, InstantSplat comprises a Coarse Geometric Initialization (CGI) module that swiftly establishes a preliminary scene structure and camera parameters across all training views, utilizing globally-aligned 3D point maps derived from a pre-trained dense stereo pipeline. This is followed by the Fast 3D-Gaussian Optimization (F-3DGO) module, which jointly optimizes the 3D Gaussian attributes and the initialized poses with pose regularization. Experiments conducted on the large-scale outdoor Tanks & Temples datasets demonstrate that InstantSplat significantly improves SSIM (by 32%) while concurrently reducing Absolute Trajectory Error (ATE) by 80%. These establish InstantSplat as a viable solution for scenarios involving posefree and sparse-view conditions. Project page: instantsplat.github.io.
4/1/2024