Unique3D: High-Quality and Efficient 3D Mesh Generation from a Single Image
2405.20343
0
0

Abstract
In this work, we introduce Unique3D, a novel image-to-3D framework for efficiently generating high-quality 3D meshes from single-view images, featuring state-of-the-art generation fidelity and strong generalizability. Previous methods based on Score Distillation Sampling (SDS) can produce diversified 3D results by distilling 3D knowledge from large 2D diffusion models, but they usually suffer from long per-case optimization time with inconsistent issues. Recent works address the problem and generate better 3D results either by finetuning a multi-view diffusion model or training a fast feed-forward model. However, they still lack intricate textures and complex geometries due to inconsistency and limited generated resolution. To simultaneously achieve high fidelity, consistency, and efficiency in single image-to-3D, we propose a novel framework Unique3D that includes a multi-view diffusion model with a corresponding normal diffusion model to generate multi-view images with their normal maps, a multi-level upscale process to progressively improve the resolution of generated orthographic multi-views, as well as an instant and consistent mesh reconstruction algorithm called ISOMER, which fully integrates the color and geometric priors into mesh results. Extensive experiments demonstrate that our Unique3D significantly outperforms other image-to-3D baselines in terms of geometric and textural details.
Create account to get full access
Overview
- This paper presents Unique3D, a novel approach for generating high-quality and efficient 3D mesh models from a single input image.
- The key innovations include a novel transformer-based architecture, a novel photometric loss function, and a novel hierarchical mesh generation process.
- The authors demonstrate that Unique3D outperforms state-of-the-art methods on several benchmark datasets, in terms of both mesh quality and generation efficiency.
Plain English Explanation
The paper introduces a new method called Unique3D that can create detailed 3D models from a single 2D image. This is a challenging problem, as converting a flat image into a 3D shape with the right proportions and details is not trivial.
Unique3D uses a specialized neural network architecture that includes a transformer model to process the input image. It also has a novel "photometric loss" function that helps the model learn to generate 3D shapes that match the lighting and shading of the original image. Finally, Unique3D uses a hierarchical approach to build up the 3D mesh in stages, starting with a coarse shape and adding more detail progressively.
The authors show that Unique3D outperforms other state-of-the-art methods for converting 2D images into 3D models. It is able to generate higher-quality 3D meshes that are more true to the original image, and it can do so more efficiently than previous approaches. This could be useful for applications like 3D content creation, virtual reality, and e-commerce, where generating realistic 3D models from photos is valuable.
Technical Explanation
The core of Unique3D is a transformer-based neural network architecture that takes a single 2D input image and generates a high-quality 3D mesh as output. The transformer model [1] is well-suited for this task as it can effectively capture the global, long-range dependencies in the input image.
To train the model, the authors introduce a novel photometric loss function that compares the rendered appearance of the generated 3D mesh to the original input image. This helps the model learn to create 3D shapes that match the lighting, shading, and other visual characteristics of the input.
Additionally, Unique3D uses a hierarchical mesh generation process, starting with a coarse base mesh and progressively adding more geometric detail. This allows the model to efficiently capture the overall 3D structure as well as fine-grained surface details.
The authors evaluate Unique3D on several benchmark datasets for single-image 3D reconstruction, including FlexiDreamer, ONE-to-3D, and Part-123. They demonstrate that Unique3D outperforms state-of-the-art methods in terms of both mesh quality and generation efficiency.
Critical Analysis
The authors acknowledge that Unique3D has some limitations, such as its reliance on a single input image. In some cases, additional information like camera parameters or depth cues may be needed to generate highly accurate 3D meshes. The authors suggest that future work could explore ways to incorporate auxiliary data sources to further improve performance.
Additionally, the paper does not provide a detailed analysis of the computational complexity and runtime of Unique3D compared to other 3D reconstruction methods. This information would be valuable for understanding the practical deployment scenarios of the proposed approach.
Overall, the Unique3D method represents a significant advancement in the field of single-image 3D reconstruction, with its novel network architecture, photometric loss function, and hierarchical mesh generation process. The strong empirical results on benchmark datasets suggest that Unique3D could be a useful tool for a variety of applications that require efficient and high-quality 3D mesh generation from 2D images.
Conclusion
The Unique3D paper introduces a novel approach for generating high-quality and efficient 3D mesh models from a single input image. The key innovations, including a transformer-based architecture, a photometric loss function, and a hierarchical mesh generation process, allow Unique3D to outperform state-of-the-art methods on several benchmark datasets.
This research could have important implications for applications that require converting 2D images into 3D content, such as 3D content creation, virtual reality, and e-commerce. By providing a more efficient and accurate way to generate 3D models from photos, Unique3D could help lower the barriers to 3D content creation and enable new use cases for 3D technology in various industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, Ying Shan
0
0
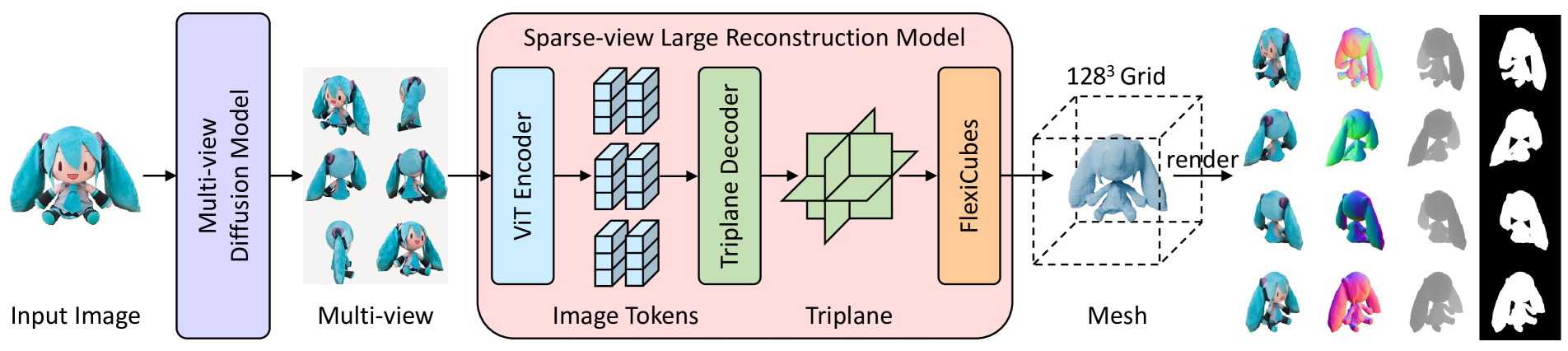
We present InstantMesh, a feed-forward framework for instant 3D mesh generation from a single image, featuring state-of-the-art generation quality and significant training scalability. By synergizing the strengths of an off-the-shelf multiview diffusion model and a sparse-view reconstruction model based on the LRM architecture, InstantMesh is able to create diverse 3D assets within 10 seconds. To enhance the training efficiency and exploit more geometric supervisions, e.g, depths and normals, we integrate a differentiable iso-surface extraction module into our framework and directly optimize on the mesh representation. Experimental results on public datasets demonstrate that InstantMesh significantly outperforms other latest image-to-3D baselines, both qualitatively and quantitatively. We release all the code, weights, and demo of InstantMesh, with the intention that it can make substantial contributions to the community of 3D generative AI and empower both researchers and content creators.
4/16/2024
FlexiDreamer: Single Image-to-3D Generation with FlexiCubes
Ruowen Zhao, Zhengyi Wang, Yikai Wang, Zihan Zhou, Jun Zhu
0
0
3D content generation has wide applications in various fields. One of its dominant paradigms is by sparse-view reconstruction using multi-view images generated by diffusion models. However, since directly reconstructing triangle meshes from multi-view images is challenging, most methodologies opt to an implicit representation (such as NeRF) during the sparse-view reconstruction and acquire the target mesh by a post-processing extraction. However, the implicit representation takes extensive time to train and the post-extraction also leads to undesirable visual artifacts. In this paper, we propose FlexiDreamer, a novel framework that directly reconstructs high-quality meshes from multi-view generated images. We utilize an advanced gradient-based mesh optimization, namely FlexiCubes, for multi-view mesh reconstruction, which enables us to generate 3D meshes in an end-to-end manner. To address the reconstruction artifacts owing to the inconsistencies from generated images, we design a hybrid positional encoding scheme to improve the reconstruction geometry and an orientation-aware texture mapping to mitigate surface ghosting. To further enhance the results, we respectively incorporate eikonal and smooth regularizations to reduce geometric holes and surface noise. Our approach can generate high-fidelity 3D meshes in the single image-to-3D downstream task with approximately 1 minute, significantly outperforming previous methods.
5/28/2024
Portrait3D: 3D Head Generation from Single In-the-wild Portrait Image
Jinkun Hao, Junshu Tang, Jiangning Zhang, Ran Yi, Yijia Hong, Moran Li, Weijian Cao, Yating Wang, Lizhuang Ma
0
0
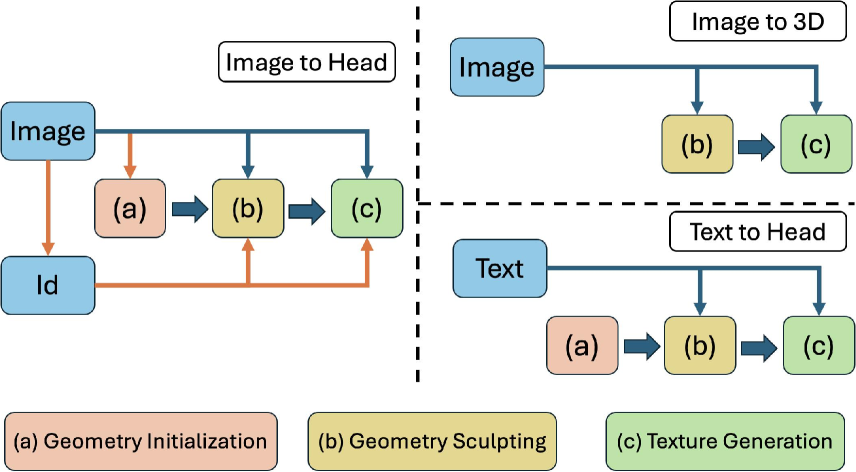
While recent works have achieved great success on one-shot 3D common object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, Portrait3D, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the id-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from single in-the-wild portrait images. The project page is at https://jinkun-hao.github.io/Portrait3D/.
6/26/2024
OneTo3D: One Image to Re-editable Dynamic 3D Model and Video Generation
Jinwei Lin
0
0
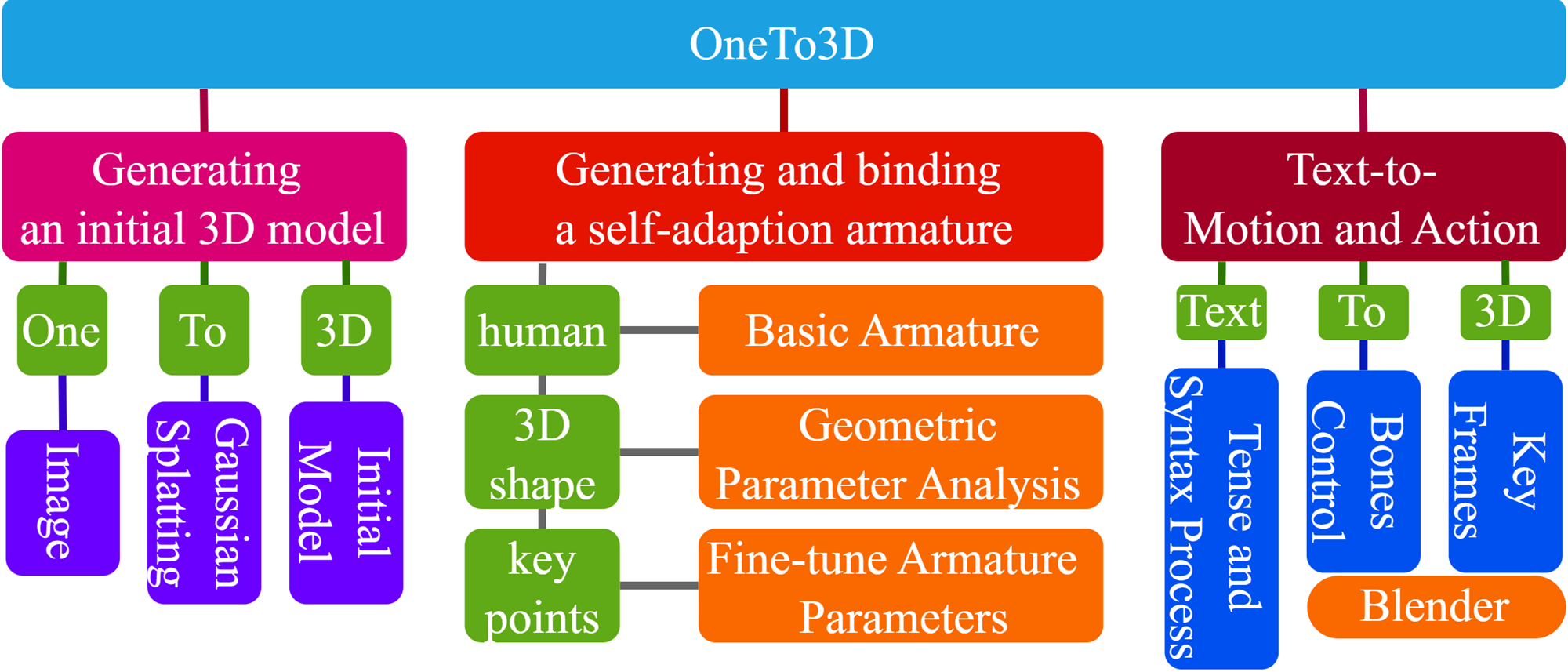
One image to editable dynamic 3D model and video generation is novel direction and change in the research area of single image to 3D representation or 3D reconstruction of image. Gaussian Splatting has demonstrated its advantages in implicit 3D reconstruction, compared with the original Neural Radiance Fields. As the rapid development of technologies and principles, people tried to used the Stable Diffusion models to generate targeted models with text instructions. However, using the normal implicit machine learning methods is hard to gain the precise motions and actions control, further more, it is difficult to generate a long content and semantic continuous 3D video. To address this issue, we propose the OneTo3D, a method and theory to used one single image to generate the editable 3D model and generate the targeted semantic continuous time-unlimited 3D video. We used a normal basic Gaussian Splatting model to generate the 3D model from a single image, which requires less volume of video memory and computer calculation ability. Subsequently, we designed an automatic generation and self-adaptive binding mechanism for the object armature. Combined with the re-editable motions and actions analyzing and controlling algorithm we proposed, we can achieve a better performance than the SOTA projects in the area of building the 3D model precise motions and actions control, and generating a stable semantic continuous time-unlimited 3D video with the input text instructions. Here we will analyze the detailed implementation methods and theories analyses. Relative comparisons and conclusions will be presented. The project code is open source.
5/13/2024