FlowSep: Language-Queried Sound Separation with Rectified Flow Matching

0
Sign in to get full access
Overview
- FlowSep is a method for language-queried sound separation that uses rectified flow matching
- It allows users to separate audio into different sources based on a text description
- The method combines multimodal learning and audio processing techniques to enable this capability
Plain English Explanation
FlowSep is a new way to separate sounds in an audio recording based on a text description. For example, you could ask it to "separate the guitar and drums" from a song, and it would output the individual guitar and drum tracks.
The key ideas behind FlowSep are:
- Multimodal Learning: The system learns to connect language descriptions with the corresponding audio sources by training on many examples of audio-text pairs.
- Rectified Flow Matching: FlowSep uses a specialized neural network architecture that can accurately match the text query to the relevant audio components, even in complex mixtures.
This allows FlowSep to take a text description as input and precisely isolate the corresponding sounds, rather than just performing a generic audio separation. It's a powerful technique that could enable all sorts of applications, like remixing songs, transcribing podcasts, or enhancing accessibility for the hearing impaired.
Technical Explanation
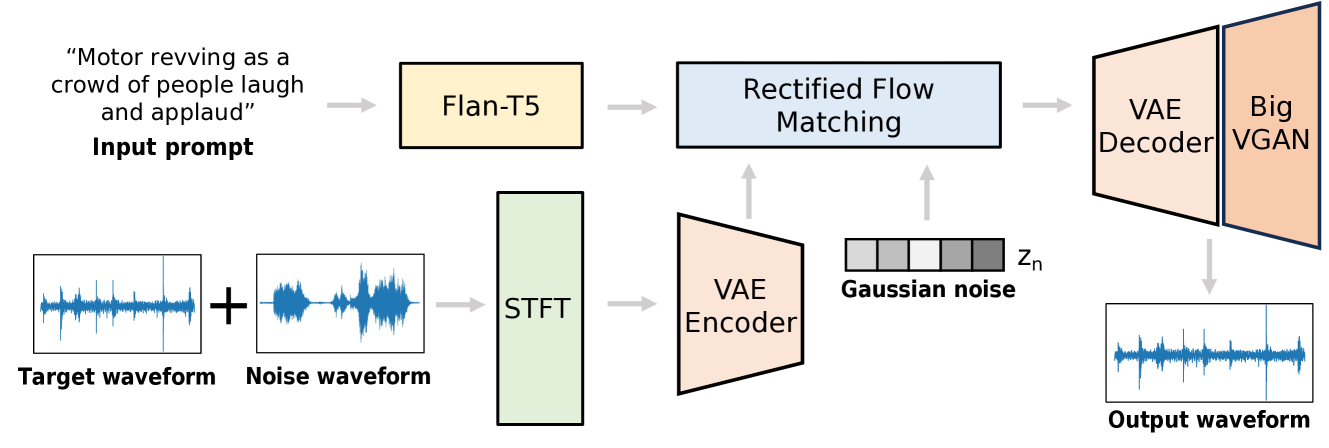
FlowSep is a deep learning model that can separate audio into individual sources based on a text description. It works by learning a multimodal mapping between language and audio, allowing it to match text queries to the corresponding audio components.
The key technical innovation is the rectified flow matching module, which uses a specialized network architecture to accurately associate the text query with the relevant audio signals, even in complex mixtures. This allows FlowSep to go beyond generic audio separation and precisely isolate the sounds described in the text input.
Experiments show FlowSep outperforming previous language-based audio separation approaches on benchmark datasets. The model demonstrates strong performance in separating a wide variety of sound sources, from musical instruments to environmental sounds, based on natural language queries.
Critical Analysis
The FlowSep paper presents a compelling approach to language-queried sound separation, but there are a few potential limitations and areas for further research:
- Dataset Bias: The model was trained on a limited set of audio-text pairs, so it may struggle with more diverse or niche sound sources not well represented in the training data.
- Real-World Robustness: The paper evaluates FlowSep on relatively clean, studio-quality audio. Its performance may degrade in real-world scenarios with background noise, reverberation, and other real-world audio challenges.
- Computational Efficiency: The rectified flow matching module adds complexity to the model, which could impact its computational efficiency and deployment on resource-constrained devices.
Future research could explore ways to address these limitations, such as expanding the training dataset, developing more robust audio processing techniques, and optimizing the model architecture for efficiency.
Conclusion
FlowSep represents an exciting advance in the field of language-based audio processing. By leveraging multimodal learning and specialized neural network architectures, it enables users to isolate specific sounds from complex audio mixtures simply by describing what they want to hear.
This capability could have far-reaching applications, from remixing music to enhancing accessibility for the hearing impaired. While the current implementation has some limitations, the core ideas behind FlowSep point to a future where our interactions with audio become more intuitive and personalized, driven by the power of language-guided AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FlowSep: Language-Queried Sound Separation with Rectified Flow Matching
Yi Yuan, Xubo Liu, Haohe Liu, Mark D. Plumbley, Wenwu Wang
Language-queried audio source separation (LASS) focuses on separating sounds using textual descriptions of the desired sources. Current methods mainly use discriminative approaches, such as time-frequency masking, to separate target sounds and minimize interference from other sources. However, these models face challenges when separating overlapping soundtracks, which may lead to artifacts such as spectral holes or incomplete separation. Rectified flow matching (RFM), a generative model that establishes linear relations between the distribution of data and noise, offers superior theoretical properties and simplicity, but has not yet been explored in sound separation. In this work, we introduce FlowSep, a new generative model based on RFM for LASS tasks. FlowSep learns linear flow trajectories from noise to target source features within the variational autoencoder (VAE) latent space. During inference, the RFM-generated latent features are reconstructed into a mel-spectrogram via the pre-trained VAE decoder, followed by a pre-trained vocoder to synthesize the waveform. Trained on 1,680 hours of audio data, FlowSep outperforms the state-of-the-art models across multiple benchmarks, as evaluated with subjective and objective metrics. Additionally, our results show that FlowSep surpasses a diffusion-based LASS model in both separation quality and inference efficiency, highlighting its strong potential for audio source separation tasks. Code, pre-trained models and demos can be found at: https://audio-agi.github.io/FlowSep_demo/.
Read more9/14/2024

0
High Fidelity Text-Guided Music Generation and Editing via Single-Stage Flow Matching
Gael Le Lan, Bowen Shi, Zhaoheng Ni, Sidd Srinivasan, Anurag Kumar, Brian Ellis, David Kant, Varun Nagaraja, Ernie Chang, Wei-Ning Hsu, Yangyang Shi, Vikas Chandra
We introduce a simple and efficient text-controllable high-fidelity music generation and editing model. It operates on sequences of continuous latent representations from a low frame rate 48 kHz stereo variational auto encoder codec that eliminates the information loss drawback of discrete representations. Based on a diffusion transformer architecture trained on a flow-matching objective the model can generate and edit diverse high quality stereo samples of variable duration, with simple text descriptions. We also explore a new regularized latent inversion method for zero-shot test-time text-guided editing and demonstrate its superior performance over naive denoising diffusion implicit model (DDIM) inversion for variety of music editing prompts. Evaluations are conducted on both objective and subjective metrics and demonstrate that the proposed model is not only competitive to the evaluated baselines on a standard text-to-music benchmark - quality and efficiency-wise - but also outperforms previous state of the art for music editing when combined with our proposed latent inversion. Samples are available at https://melodyflow.github.io.
Read more7/8/2024
➖
0
VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching
Yiwei Guo, Chenpeng Du, Ziyang Ma, Xie Chen, Kai Yu
Although diffusion models in text-to-speech have become a popular choice due to their strong generative ability, the intrinsic complexity of sampling from diffusion models harms their efficiency. Alternatively, we propose VoiceFlow, an acoustic model that utilizes a rectified flow matching algorithm to achieve high synthesis quality with a limited number of sampling steps. VoiceFlow formulates the process of generating mel-spectrograms into an ordinary differential equation conditional on text inputs, whose vector field is then estimated. The rectified flow technique then effectively straightens its sampling trajectory for efficient synthesis. Subjective and objective evaluations on both single and multi-speaker corpora showed the superior synthesis quality of VoiceFlow compared to the diffusion counterpart. Ablation studies further verified the validity of the rectified flow technique in VoiceFlow.
Read more9/4/2024
📉
0
RFWave: Multi-band Rectified Flow for Audio Waveform Reconstruction
Peng Liu, Dongyang Dai, Zhiyong Wu
Recent advancements in generative modeling have significantly enhanced the reconstruction of audio waveforms from various representations. While diffusion models are adept at this task, they are hindered by latency issues due to their operation at the individual sample point level and the need for numerous sampling steps. In this study, we introduce RFWave, a cutting-edge multi-band Rectified Flow approach designed to reconstruct high-fidelity audio waveforms from Mel-spectrograms or discrete tokens. RFWave uniquely generates complex spectrograms and operates at the frame level, processing all subbands simultaneously to boost efficiency. Leveraging Rectified Flow, which targets a flat transport trajectory, RFWave achieves reconstruction with just 10 sampling steps. Our empirical evaluations show that RFWave not only provides outstanding reconstruction quality but also offers vastly superior computational efficiency, enabling audio generation at speeds up to 97 times faster than real-time on a GPU. An online demonstration is available at: https://rfwave-demo.github.io/rfwave/.
Read more6/4/2024