RFWave: Multi-band Rectified Flow for Audio Waveform Reconstruction

0
📉
Sign in to get full access
Overview
- This paper introduces a template for citing AI research papers in a consistent "PRIME AI Style" format.
- The template includes key bibliographic information such as author names, paper title, page numbers, and DOI.
- The paper covers guidelines for formatting headings, sections, and other elements to create a standardized citation style.
Plain English Explanation
The provided paper presents a template for how to properly cite and format references to AI research papers. This template aims to establish a consistent "PRIME AI Style" that researchers can use when citing AI-related work.
The template includes all the typical bibliographic details you'd expect to see in a citation, such as the author names, paper title, page numbers, and the digital object identifier (DOI). It also provides guidance on formatting the different heading levels and structuring the overall citation.
The goal is to create a standardized way of citing AI papers that makes it easier for readers to quickly identify key information about the referenced work. This can be especially helpful when there are many citations throughout a paper or when comparing citations across multiple sources.
Technical Explanation
The paper outlines a template for citing AI research papers in a consistent "PRIME AI Style" format. The template includes the following key elements:
- Author Names: The full names of all authors, formatted in a consistent style (e.g. FirstName LastName).
- Title: The full title of the research paper.
- Pages: The page range for the paper.
- DOI: The digital object identifier (DOI) for the paper, which provides a unique and persistent link to the published version.
The paper also provides guidance on formatting the different heading levels (e.g. Section 1, Subsection 2.1) and structuring the overall citation. This includes using consistent capitalization, punctuation, and spacing throughout.
The proposed citation style is designed to make it easier for readers to quickly identify key information about referenced AI papers. This standardization can be particularly useful in research areas with rapidly expanding literature, where a consistent citation format can improve readability and discoverability.
Critical Analysis
The template presented in this paper provides a helpful standardization for citing AI research works. The inclusion of key bibliographic details like author names, titles, page ranges, and DOIs makes the citations more informative and easier to cross-reference.
One potential limitation is that the template does not address how to handle papers with large author lists, which are becoming more common in AI research. The authors may want to consider guidance on abbreviating long author lists while still preserving key information.
Additionally, the template could be further enhanced by incorporating links to the paper or code repositories associated with the cited work. This would make it easier for readers to quickly access the referenced materials.
Overall, this paper provides a solid foundation for a standardized AI citation style. As the field continues to evolve, the authors may want to revisit the template and incorporate feedback from the community to ensure it remains relevant and useful.
Conclusion
This paper introduces a template for citing AI research papers in a consistent "PRIME AI Style" format. The template includes key bibliographic details like author names, paper titles, page numbers, and DOIs, along with guidance on formatting headings and structure.
The proposed citation style is designed to improve the readability and discoverability of AI research literature, which is becoming increasingly important as the field continues to grow rapidly. While the template could be further refined, it represents a valuable step towards establishing a more standardized approach to referencing AI-related works.
By adopting this or a similar citation style, researchers can help make it easier for readers to quickly identify and access the relevant AI papers they need, ultimately advancing the field through better information sharing and collaboration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
RFWave: Multi-band Rectified Flow for Audio Waveform Reconstruction
Peng Liu, Dongyang Dai, Zhiyong Wu
Recent advancements in generative modeling have significantly enhanced the reconstruction of audio waveforms from various representations. While diffusion models are adept at this task, they are hindered by latency issues due to their operation at the individual sample point level and the need for numerous sampling steps. In this study, we introduce RFWave, a cutting-edge multi-band Rectified Flow approach designed to reconstruct high-fidelity audio waveforms from Mel-spectrograms or discrete tokens. RFWave uniquely generates complex spectrograms and operates at the frame level, processing all subbands simultaneously to boost efficiency. Leveraging Rectified Flow, which targets a flat transport trajectory, RFWave achieves reconstruction with just 10 sampling steps. Our empirical evaluations show that RFWave not only provides outstanding reconstruction quality but also offers vastly superior computational efficiency, enabling audio generation at speeds up to 97 times faster than real-time on a GPU. An online demonstration is available at: https://rfwave-demo.github.io/rfwave/.
Read more6/4/2024
➖
0
VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching
Yiwei Guo, Chenpeng Du, Ziyang Ma, Xie Chen, Kai Yu
Although diffusion models in text-to-speech have become a popular choice due to their strong generative ability, the intrinsic complexity of sampling from diffusion models harms their efficiency. Alternatively, we propose VoiceFlow, an acoustic model that utilizes a rectified flow matching algorithm to achieve high synthesis quality with a limited number of sampling steps. VoiceFlow formulates the process of generating mel-spectrograms into an ordinary differential equation conditional on text inputs, whose vector field is then estimated. The rectified flow technique then effectively straightens its sampling trajectory for efficient synthesis. Subjective and objective evaluations on both single and multi-speaker corpora showed the superior synthesis quality of VoiceFlow compared to the diffusion counterpart. Ablation studies further verified the validity of the rectified flow technique in VoiceFlow.
Read more9/4/2024
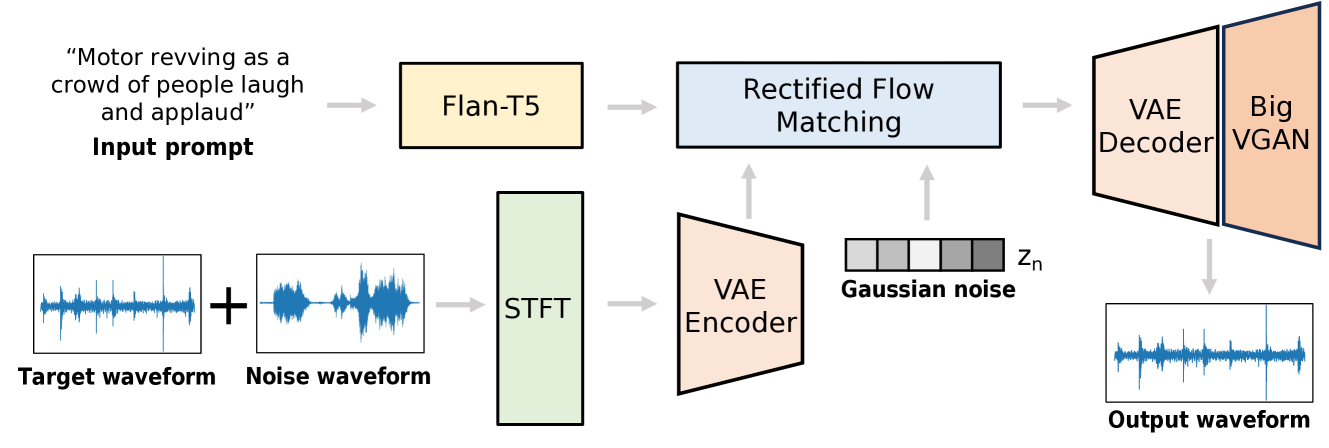
0
FlowSep: Language-Queried Sound Separation with Rectified Flow Matching
Yi Yuan, Xubo Liu, Haohe Liu, Mark D. Plumbley, Wenwu Wang
Language-queried audio source separation (LASS) focuses on separating sounds using textual descriptions of the desired sources. Current methods mainly use discriminative approaches, such as time-frequency masking, to separate target sounds and minimize interference from other sources. However, these models face challenges when separating overlapping soundtracks, which may lead to artifacts such as spectral holes or incomplete separation. Rectified flow matching (RFM), a generative model that establishes linear relations between the distribution of data and noise, offers superior theoretical properties and simplicity, but has not yet been explored in sound separation. In this work, we introduce FlowSep, a new generative model based on RFM for LASS tasks. FlowSep learns linear flow trajectories from noise to target source features within the variational autoencoder (VAE) latent space. During inference, the RFM-generated latent features are reconstructed into a mel-spectrogram via the pre-trained VAE decoder, followed by a pre-trained vocoder to synthesize the waveform. Trained on 1,680 hours of audio data, FlowSep outperforms the state-of-the-art models across multiple benchmarks, as evaluated with subjective and objective metrics. Additionally, our results show that FlowSep surpasses a diffusion-based LASS model in both separation quality and inference efficiency, highlighting its strong potential for audio source separation tasks. Code, pre-trained models and demos can be found at: https://audio-agi.github.io/FlowSep_demo/.
Read more9/14/2024

0
PeriodWave: Multi-Period Flow Matching for High-Fidelity Waveform Generation
Sang-Hoon Lee, Ha-Yeong Choi, Seong-Whan Lee
Recently, universal waveform generation tasks have been investigated conditioned on various out-of-distribution scenarios. Although GAN-based methods have shown their strength in fast waveform generation, they are vulnerable to train-inference mismatch scenarios such as two-stage text-to-speech. Meanwhile, diffusion-based models have shown their powerful generative performance in other domains; however, they stay out of the limelight due to slow inference speed in waveform generation tasks. Above all, there is no generator architecture that can explicitly disentangle the natural periodic features of high-resolution waveform signals. In this paper, we propose PeriodWave, a novel universal waveform generation model. First, we introduce a period-aware flow matching estimator that can capture the periodic features of the waveform signal when estimating the vector fields. Additionally, we utilize a multi-period estimator that avoids overlaps to capture different periodic features of waveform signals. Although increasing the number of periods can improve the performance significantly, this requires more computational costs. To reduce this issue, we also propose a single period-conditional universal estimator that can feed-forward parallel by period-wise batch inference. Additionally, we utilize discrete wavelet transform to losslessly disentangle the frequency information of waveform signals for high-frequency modeling, and introduce FreeU to reduce the high-frequency noise for waveform generation. The experimental results demonstrated that our model outperforms the previous models both in Mel-spectrogram reconstruction and text-to-speech tasks. All source code will be available at url{https://github.com/sh-lee-prml/PeriodWave}.
Read more8/15/2024