High Fidelity Text-Guided Music Generation and Editing via Single-Stage Flow Matching

0

Sign in to get full access
Overview
- The paper proposes a method for high-fidelity, text-guided music generation and editing using a single-stage flow matching approach.
- The method allows users to generate or edit music by providing text prompts, enabling fine-grained control over the musical output.
- The approach involves a novel architecture that combines text encoding, audio representation learning, and a single-stage flow-based generative model.
Plain English Explanation
The researchers have developed a new way to generate and edit music using text prompts. Traditionally, creating music with computers has been challenging, as it often requires specialized knowledge and skills. This new method aims to make the process more accessible by allowing users to describe the music they want, rather than having to manually create it.
The researchers' approach involves a novel architecture that combines text encoding, audio representation learning, and a single-stage flow-based generative model. This means the system can understand the text prompts, translate them into musical features, and then generate or edit the music accordingly.
By using a single-stage flow matching approach, the method is able to produce high-fidelity, coherent musical outputs that closely match the text prompts. This allows users to have fine-grained control over the generated music, such as specifying the genre, mood, or instrumentation.
The researchers have demonstrated the effectiveness of their approach through various experiments and comparisons to existing music generation and editing techniques. Overall, this work represents an important step towards making music creation more accessible and intuitive for a wider audience.
Technical Explanation
The key components of the proposed method include a text encoder, an audio representation learning module, and a single-stage flow-based generative model. The text encoder converts the input text prompt into a semantic representation, which is then combined with the audio representation learned from the training data.
The researchers conducted experiments to evaluate the generation and editing capabilities of their method. They compared the generated music to ground-truth data and existing music generation techniques, demonstrating the ability to produce coherent and high-quality musical outputs that closely match the input text prompts.
Critical Analysis
The paper presents a compelling approach to text-guided music generation and editing, addressing the challenge of making music creation more accessible. The single-stage flow-based architecture is a novel contribution that enables efficient, high-fidelity generation.
However, the paper does not fully address the potential limitations of the method, such as the potential for bias in the training data or the ability to generate diverse and original musical styles beyond those represented in the training set. Additionally, the paper could have provided more details on the specific architectural choices and the training process to allow for better reproducibility and further research.
While the experiments demonstrate the method's effectiveness, it would be valuable to see more extensive evaluations, including user studies to assess the usability and real-world applicability of the system. Exploring the limitations and potential biases of the approach would also be important for understanding its practical implications.
Conclusion
The proposed method for high-fidelity, text-guided music generation and editing represents an important step forward in making music creation more accessible and intuitive for a wider audience. The single-stage flow-based architecture enables efficient and high-quality musical outputs that closely match the input text prompts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
High Fidelity Text-Guided Music Generation and Editing via Single-Stage Flow Matching
Gael Le Lan, Bowen Shi, Zhaoheng Ni, Sidd Srinivasan, Anurag Kumar, Brian Ellis, David Kant, Varun Nagaraja, Ernie Chang, Wei-Ning Hsu, Yangyang Shi, Vikas Chandra
We introduce a simple and efficient text-controllable high-fidelity music generation and editing model. It operates on sequences of continuous latent representations from a low frame rate 48 kHz stereo variational auto encoder codec that eliminates the information loss drawback of discrete representations. Based on a diffusion transformer architecture trained on a flow-matching objective the model can generate and edit diverse high quality stereo samples of variable duration, with simple text descriptions. We also explore a new regularized latent inversion method for zero-shot test-time text-guided editing and demonstrate its superior performance over naive denoising diffusion implicit model (DDIM) inversion for variety of music editing prompts. Evaluations are conducted on both objective and subjective metrics and demonstrate that the proposed model is not only competitive to the evaluated baselines on a standard text-to-music benchmark - quality and efficiency-wise - but also outperforms previous state of the art for music editing when combined with our proposed latent inversion. Samples are available at https://melodyflow.github.io.
Read more7/8/2024

0
MusicMagus: Zero-Shot Text-to-Music Editing via Diffusion Models
Yixiao Zhang, Yukara Ikemiya, Gus Xia, Naoki Murata, Marco A. Mart'inez-Ram'irez, Wei-Hsiang Liao, Yuki Mitsufuji, Simon Dixon
Recent advances in text-to-music generation models have opened new avenues in musical creativity. However, music generation usually involves iterative refinements, and how to edit the generated music remains a significant challenge. This paper introduces a novel approach to the editing of music generated by such models, enabling the modification of specific attributes, such as genre, mood and instrument, while maintaining other aspects unchanged. Our method transforms text editing to textit{latent space manipulation} while adding an extra constraint to enforce consistency. It seamlessly integrates with existing pretrained text-to-music diffusion models without requiring additional training. Experimental results demonstrate superior performance over both zero-shot and certain supervised baselines in style and timbre transfer evaluations. Additionally, we showcase the practical applicability of our approach in real-world music editing scenarios.
Read more5/29/2024

0
FLUX that Plays Music
Zhengcong Fei, Mingyuan Fan, Changqian Yu, Junshi Huang
This paper explores a simple extension of diffusion-based rectified flow Transformers for text-to-music generation, termed as FluxMusic. Generally, along with design in advanced Fluxfootnote{https://github.com/black-forest-labs/flux} model, we transfers it into a latent VAE space of mel-spectrum. It involves first applying a sequence of independent attention to the double text-music stream, followed by a stacked single music stream for denoised patch prediction. We employ multiple pre-trained text encoders to sufficiently capture caption semantic information as well as inference flexibility. In between, coarse textual information, in conjunction with time step embeddings, is utilized in a modulation mechanism, while fine-grained textual details are concatenated with the music patch sequence as inputs. Through an in-depth study, we demonstrate that rectified flow training with an optimized architecture significantly outperforms established diffusion methods for the text-to-music task, as evidenced by various automatic metrics and human preference evaluations. Our experimental data, code, and model weights are made publicly available at: url{https://github.com/feizc/FluxMusic}.
Read more9/4/2024
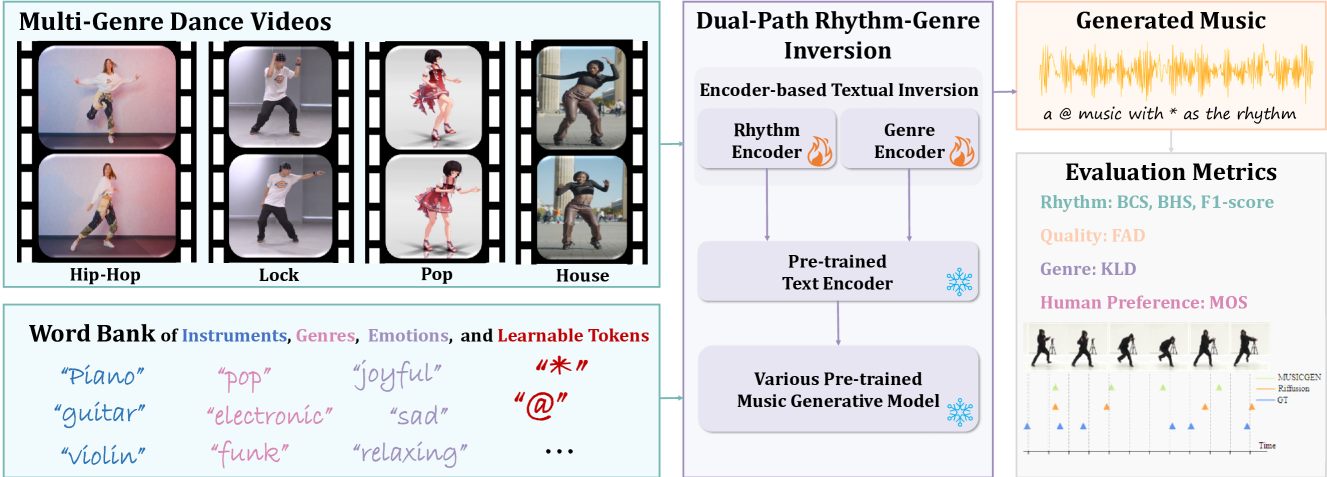
0
New!Dance-to-Music Generation with Encoder-based Textual Inversion
Sifei Li, Weiming Dong, Yuxin Zhang, Fan Tang, Chongyang Ma, Oliver Deussen, Tong-Yee Lee, Changsheng Xu
The seamless integration of music with dance movements is essential for communicating the artistic intent of a dance piece. This alignment also significantly improves the immersive quality of gaming experiences and animation productions. Although there has been remarkable advancement in creating high-fidelity music from textual descriptions, current methodologies mainly focus on modulating overall characteristics such as genre and emotional tone. They often overlook the nuanced management of temporal rhythm, which is indispensable in crafting music for dance, since it intricately aligns the musical beats with the dancers' movements. Recognizing this gap, we propose an encoder-based textual inversion technique to augment text-to-music models with visual control, facilitating personalized music generation. Specifically, we develop dual-path rhythm-genre inversion to effectively integrate the rhythm and genre of a dance motion sequence into the textual space of a text-to-music model. Contrary to traditional textual inversion methods, which directly update text embeddings to reconstruct a single target object, our approach utilizes separate rhythm and genre encoders to obtain text embeddings for two pseudo-words, adapting to the varying rhythms and genres. We collect a new dataset called In-the-wild Dance Videos (InDV) and demonstrate that our approach outperforms state-of-the-art methods across multiple evaluation metrics. Furthermore, our method is able to adapt to changes in tempo and effectively integrates with the inherent text-guided generation capability of the pre-trained model. Our source code and demo videos are available at url{https://github.com/lsfhuihuiff/Dance-to-music_Siggraph_Asia_2024}
Read more9/16/2024