FlowVQA: Mapping Multimodal Logic in Visual Question Answering with Flowcharts
2406.19237
0
0

Abstract
Existing benchmarks for visual question answering lack in visual grounding and complexity, particularly in evaluating spatial reasoning skills. We introduce FlowVQA, a novel benchmark aimed at assessing the capabilities of visual question-answering multimodal language models in reasoning with flowcharts as visual contexts. FlowVQA comprises 2,272 carefully generated and human-verified flowchart images from three distinct content sources, along with 22,413 diverse question-answer pairs, to test a spectrum of reasoning tasks, including information localization, decision-making, and logical progression. We conduct a thorough baseline evaluation on a suite of both open-source and proprietary multimodal language models using various strategies, followed by an analysis of directional bias. The results underscore the benchmark's potential as a vital tool for advancing the field of multimodal modeling, providing a focused and challenging environment for enhancing model performance in visual and logical reasoning tasks.
Create account to get full access
Overview
- The paper presents a new resource called FlowVQA for studying multimodal logic in visual question answering (VQA) using flowcharts.
- FlowVQA consists of a dataset of images and questions, along with annotated flowcharts that capture the underlying reasoning for answering the questions.
- The authors propose a novel FlowVQA model that maps the multimodal inputs (image and question) to the flowchart representations to generate answers.
Plain English Explanation
The paper introduces a new dataset called FlowVQA that is designed to study how people use logical reasoning to answer questions about images. The key idea is to capture this logical reasoning process using flowcharts, which are diagrams that show the step-by-step decision-making involved in solving a problem.
The FlowVQA dataset contains images, questions about those images, and flowcharts that illustrate the thought process for answering the questions. For example, if the image shows a kitchen scene and the question is "What is the cook doing?", the flowchart might show steps like "Identify the person in the image", "Observe their actions", and "Determine the cooking-related activity they are performing".
By studying how people map the image and question to the flowchart representation, the researchers hope to gain insights into the underlying multimodal reasoning involved in visual question answering. This could lead to the development of more advanced AI models for VQA that can better mimic human-like logical thinking.
The paper also proposes a new FlowVQA model that learns to generate the appropriate flowchart given an image and question. This model could be useful for explaining the reasoning behind VQA systems in a more interpretable way, similar to how BLOOMVQA aims to provide hierarchical explanations.
Technical Explanation
The FlowVQA dataset consists of 23,000 images from the LOVA3 dataset, along with over 92,000 question-answer pairs and 92,000 annotated flowcharts. The flowcharts were created by humans to capture the step-by-step logical reasoning for answering each question.
The authors propose a FlowVQA model that takes the image and question as input and generates the corresponding flowchart representation. The model uses a vision transformer to encode the image, a language model to encode the question, and a flowchart decoder to generate the flowchart step-by-step. The model is trained end-to-end to minimize the discrepancy between the generated flowchart and the ground truth flowchart.
Experiments on the FlowVQA dataset show that the proposed model outperforms several baselines in terms of flowchart generation accuracy. The authors also demonstrate that the generated flowcharts can provide interpretable explanations for the model's VQA predictions, similar to the MedThink approach for medical VQA.
Critical Analysis
The FlowVQA resource and model represent an interesting step towards understanding and explaining the multimodal reasoning involved in visual question answering. By focusing on flowcharts as an intermediate representation, the authors aim to capture the step-by-step logical process that humans use to answer questions about images.
One potential limitation of the FlowVQA dataset is the reliance on human-annotated flowcharts, which may not fully capture the nuances of human reasoning. Additionally, the dataset is relatively small compared to other VQA benchmarks, which could limit the generalization of the models trained on it.
Further research could explore ways to automatically generate flowcharts from question-answer pairs, or to learn flowchart representations directly from the data without relying on human annotations. Integrating the FlowVQA model with other VQA approaches, such as LOVA3 or MedThink, could also lead to more robust and interpretable VQA systems.
Conclusion
The FlowVQA resource and model introduced in this paper represent an important step towards understanding and explaining the multimodal reasoning involved in visual question answering. By capturing the logical reasoning process through flowcharts, the authors aim to provide a more interpretable and explainable approach to VQA. While the current dataset and model have some limitations, the overall concept of using flowcharts as an intermediate representation for VQA is a promising direction for future research in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

mChartQA: A universal benchmark for multimodal Chart Question Answer based on Vision-Language Alignment and Reasoning
Jingxuan Wei, Nan Xu, Guiyong Chang, Yin Luo, BiHui Yu, Ruifeng Guo
0
0
In the fields of computer vision and natural language processing, multimodal chart question-answering, especially involving color, structure, and textless charts, poses significant challenges. Traditional methods, which typically involve either direct multimodal processing or a table-to-text conversion followed by language model analysis, have limitations in effectively handling these complex scenarios. This paper introduces a novel multimodal chart question-answering model, specifically designed to address these intricate tasks. Our model integrates visual and linguistic processing, overcoming the constraints of existing methods. We adopt a dual-phase training approach: the initial phase focuses on aligning image and text representations, while the subsequent phase concentrates on optimizing the model's interpretative and analytical abilities in chart-related queries. This approach has demonstrated superior performance on multiple public datasets, particularly in handling color, structure, and textless chart questions, indicating its effectiveness in complex multimodal tasks.
4/3/2024
First Multi-Dimensional Evaluation of Flowchart Comprehension for Multimodal Large Language Models
Enming Zhang, Ruobing Yao, Huanyong Liu, Junhui Yu, Jiale Wang
0
0
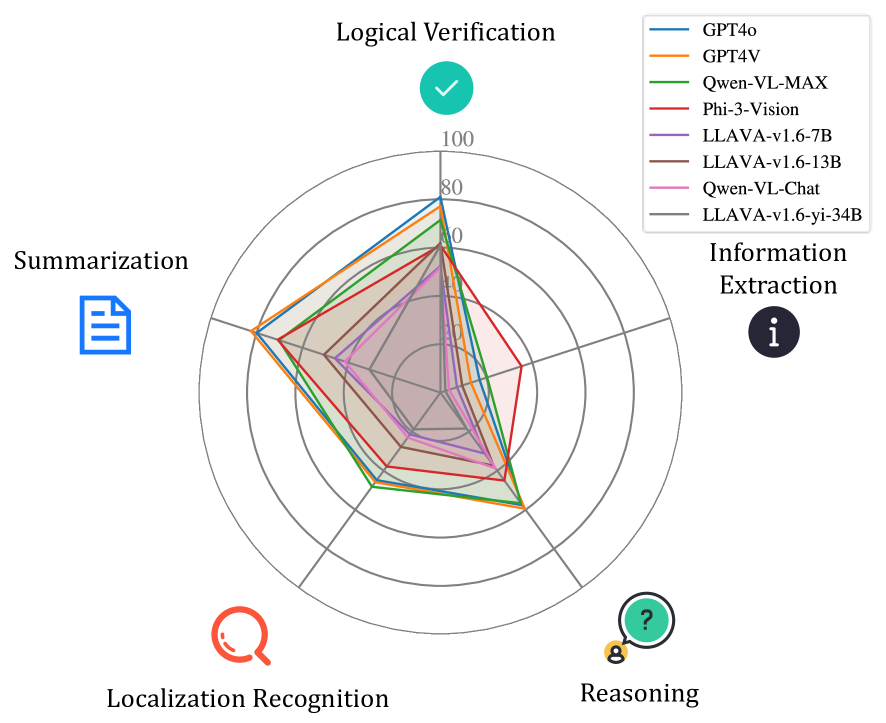
With the development of Multimodal Large Language Models (MLLMs) technology, its general capabilities are increasingly powerful. To evaluate the various abilities of MLLMs, numerous evaluation systems have emerged. But now there is still a lack of a comprehensive method to evaluate MLLMs in the tasks related to flowcharts, which are very important in daily life and work. We propose the first comprehensive method, FlowCE, to assess MLLMs across various dimensions for tasks related to flowcharts. It encompasses evaluating MLLMs' abilities in Reasoning, Localization Recognition, Information Extraction, Logical Verification, and Summarization on flowcharts. However, we find that even the GPT4o model achieves only a score of 56.63. Among open-source models, Phi-3-Vision obtained the highest score of 49.97. We hope that FlowCE can contribute to future research on MLLMs for tasks based on flowcharts. url{https://github.com/360AILAB-NLP/FlowCE} end{abstract}
6/19/2024
BloomVQA: Assessing Hierarchical Multi-modal Comprehension
Yunye Gong, Robik Shrestha, Jared Claypoole, Michael Cogswell, Arijit Ray, Christopher Kanan, Ajay Divakaran
0
0
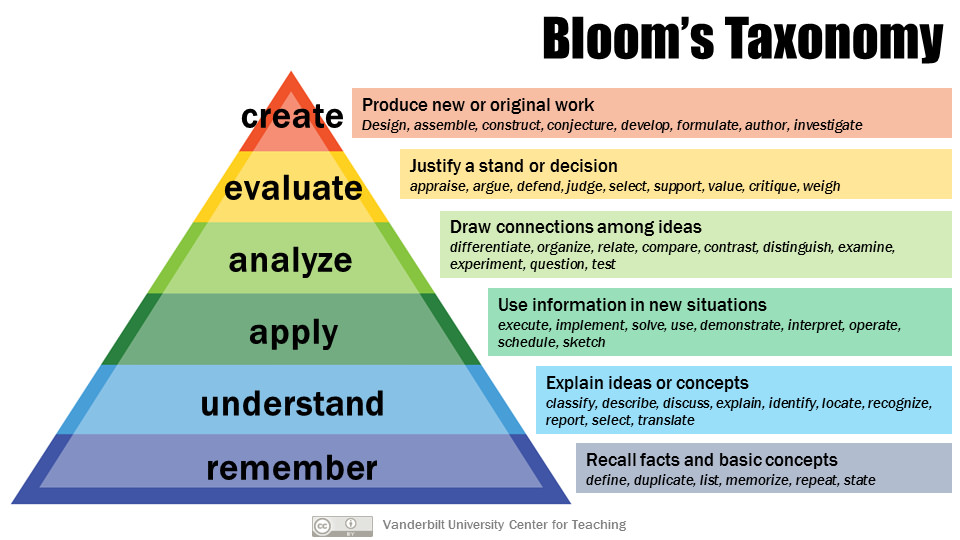
We propose a novel VQA dataset, BloomVQA, to facilitate comprehensive evaluation of large vision-language models on comprehension tasks. Unlike current benchmarks that often focus on fact-based memorization and simple reasoning tasks without theoretical grounding, we collect multiple-choice samples based on picture stories that reflect different levels of comprehension, as laid out in Bloom's Taxonomy, a classic framework for learning assessment widely adopted in education research. Our data maps to a novel hierarchical graph representation which enables automatic data augmentation and novel measures characterizing model consistency. We perform graded evaluation and reliability analysis on recent multi-modal models. In comparison to low-level tasks, we observe decreased performance on tasks requiring advanced comprehension and cognitive skills with up to 38.0% drop in VQA accuracy. In comparison to earlier models, GPT-4V demonstrates improved accuracy over all comprehension levels and shows a tendency of bypassing visual inputs especially for higher-level tasks. Current models also show consistency patterns misaligned with human comprehension in various scenarios, demonstrating the need for improvement based on theoretically-grounded criteria.
6/11/2024

LOVA3: Learning to Visual Question Answering, Asking and Assessment
Henry Hengyuan Zhao, Pan Zhou, Difei Gao, Mike Zheng Shou
0
0
Question answering, asking, and assessment are three innate human traits crucial for understanding the world and acquiring knowledge. By enhancing these capabilities, humans can more effectively utilize data, leading to better comprehension and learning outcomes. However, current Multimodal Large Language Models (MLLMs) primarily focus on question answering, often neglecting the full potential of questioning and assessment skills. In this study, we introduce LOVA3, an innovative framework named ``Learning tO Visual Question Answering, Asking and Assessment,'' designed to equip MLLMs with these additional capabilities. Our approach involves the creation of two supplementary training tasks GenQA and EvalQA, aiming at fostering the skills of asking and assessing questions in the context of images. To develop the questioning ability, we compile a comprehensive set of multimodal foundational tasks. For assessment, we introduce a new benchmark called EvalQABench, comprising 64,000 training samples (split evenly between positive and negative samples) and 5,000 testing samples. We posit that enhancing MLLMs with the capabilities to answer, ask, and assess questions will improve their multimodal comprehension and lead to better performance. We validate our hypothesis by training an MLLM using the LOVA3 framework and testing it on 10 multimodal benchmarks. The results demonstrate consistent performance improvements, thereby confirming the efficacy of our approach.
5/27/2024