BloomVQA: Assessing Hierarchical Multi-modal Comprehension

0
Sign in to get full access
Overview
- This paper introduces BloomVQA, a new dataset and benchmark for assessing hierarchical multi-modal comprehension.
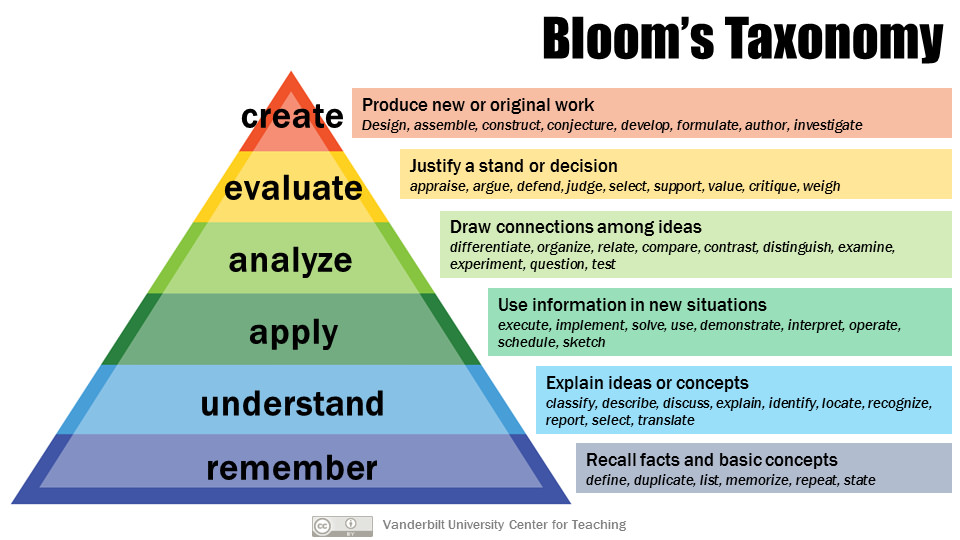
- The dataset is inspired by Bloom's Taxonomy, a framework for categorizing different levels of learning objectives.
- The goal is to measure a model's ability to answer questions that span different cognitive levels, from simple factual recall to higher-order reasoning and problem-solving.
Plain English Explanation
The researchers behind this paper wanted to create a new way to test how well AI models can understand and reason about visual information in combination with language. They drew inspiration from Bloom's Taxonomy, a popular framework in education for categorizing different levels of learning, from basic memorization up to more complex analysis and problem-solving.
The researchers built a new dataset called BloomVQA, which contains visual questions that span these different cognitive levels. For example, some questions might just ask you to identify an object in an image, while others require deeper understanding to answer correctly.
The goal is to use this dataset as a more comprehensive benchmark for evaluating multi-modal AI models - that is, models that can process both images and text. By looking at how well a model performs across the full range of question types, researchers can get a better sense of its true multi-modal comprehension abilities, rather than just focusing on simple factual recall.
This could help advance the development of AI systems that can engage in more nuanced and contextual understanding of visual information, which has important applications in areas like visual question answering, image captioning, and even multi-modal reasoning for tasks like visual common sense.
Technical Explanation
The BloomVQA dataset is structured around Bloom's Taxonomy, a widely-used framework in education for categorizing different levels of learning objectives. The taxonomy defines six cognitive levels: remembering, understanding, applying, analyzing, evaluating, and creating.
The researchers created visual questions that align with these different cognitive levels, ranging from simple factual recall (e.g. "What color is the car?") to higher-order reasoning and problem-solving (e.g. "What is the best way to get from point A to point B?"). This allows them to assess a model's multi-modal comprehension abilities in a more nuanced and comprehensive way than prior visual question answering datasets.
They evaluated several state-of-the-art multi-modal models on the BloomVQA benchmark, including LOVA3, PuzzleVQA, and SEED-Bench 2+. The results showed significant performance gaps between the different cognitive levels, highlighting the limitations of current models in tackling the more advanced reasoning and problem-solving tasks.
Critical Analysis
The BloomVQA benchmark represents an important step forward in multi-modal AI evaluation, as it moves beyond simple factual recall to assess higher-order reasoning and comprehension abilities. However, the authors acknowledge that the dataset is still limited in its scope, focusing primarily on English-language visual questions.
Future work could explore expanding the dataset to include more diverse language and cultural perspectives, as examined in CVQA. Additionally, the authors note that the current BloomVQA questions are largely independent, and incorporating more contextual or open-ended reasoning tasks could further challenge the capabilities of state-of-the-art models.
Conclusion
The BloomVQA dataset provides a valuable new tool for assessing the multi-modal comprehension abilities of AI systems. By drawing on Bloom's Taxonomy, it offers a more nuanced and comprehensive evaluation framework than previous visual question answering benchmarks.
The insights gained from testing models on BloomVQA can help drive the development of more advanced multi-modal AI systems, with the potential to enhance applications like visual question answering, image captioning, and multi-modal reasoning. As the field of AI continues to progress, tools like BloomVQA will be crucial for measuring and pushing the boundaries of what these systems can achieve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BloomVQA: Assessing Hierarchical Multi-modal Comprehension
Yunye Gong, Robik Shrestha, Jared Claypoole, Michael Cogswell, Arijit Ray, Christopher Kanan, Ajay Divakaran
We propose a novel VQA dataset, BloomVQA, to facilitate comprehensive evaluation of large vision-language models on comprehension tasks. Unlike current benchmarks that often focus on fact-based memorization and simple reasoning tasks without theoretical grounding, we collect multiple-choice samples based on picture stories that reflect different levels of comprehension, as laid out in Bloom's Taxonomy, a classic framework for learning assessment widely adopted in education research. Our data maps to a novel hierarchical graph representation which enables automatic data augmentation and novel measures characterizing model consistency. We perform graded evaluation and reliability analysis on recent multi-modal models. In comparison to low-level tasks, we observe decreased performance on tasks requiring advanced comprehension and cognitive skills with up to 38.0% drop in VQA accuracy. In comparison to earlier models, GPT-4V demonstrates improved accuracy over all comprehension levels and shows a tendency of bypassing visual inputs especially for higher-level tasks. Current models also show consistency patterns misaligned with human comprehension in various scenarios, demonstrating the need for improvement based on theoretically-grounded criteria.
Read more6/11/2024
🛸
0
A Comprehensive Evaluation of GPT-4V on Knowledge-Intensive Visual Question Answering
Yunxin Li, Longyue Wang, Baotian Hu, Xinyu Chen, Wanqi Zhong, Chenyang Lyu, Wei Wang, Min Zhang
The emergence of multimodal large models (MLMs) has significantly advanced the field of visual understanding, offering remarkable capabilities in the realm of visual question answering (VQA). Yet, the true challenge lies in the domain of knowledge-intensive VQA tasks, which necessitate not just recognition of visual elements, but also a deep comprehension of the visual information in conjunction with a vast repository of learned knowledge. To uncover such capabilities of MLMs, particularly the newly introduced GPT-4V and Gemini, we provide an in-depth evaluation from three perspectives: 1) Commonsense Knowledge, which assesses how well models can understand visual cues and connect to general knowledge; 2) Fine-grained World Knowledge, which tests the model's skill in reasoning out specific knowledge from images, showcasing their proficiency across various specialized fields; 3) Comprehensive Knowledge with Decision-making Rationales, which examines model's capability to provide logical explanations for its inference, facilitating a deeper analysis from the interpretability perspective. Additionally, we utilize a visual knowledge-enhanced training strategy and multimodal retrieval-augmented generation approach to enhance MLMs, highlighting the future need for advancements in this research direction. Extensive experiments indicate that: a) GPT-4V demonstrates enhanced explanation generation when using composite images as few-shots; b) GPT-4V and other MLMs produce severe hallucinations when dealing with world knowledge; c) Visual knowledge enhanced training and prompting technicals present potential to improve performance. Codes: https://github.com/HITsz-TMG/Cognitive-Visual-Language-Mapper
Read more8/27/2024

0
Guiding Vision-Language Model Selection for Visual Question-Answering Across Tasks, Domains, and Knowledge Types
Neelabh Sinha, Vinija Jain, Aman Chadha
Visual Question-Answering (VQA) has become a key use-case in several applications to aid user experience, particularly after Vision-Language Models (VLMs) achieving good results in zero-shot inference. But evaluating different VLMs for an application requirement using a standardized framework in practical settings is still challenging. This paper introduces a comprehensive framework for evaluating VLMs tailored to VQA tasks in practical settings. We present a novel dataset derived from established VQA benchmarks, annotated with task types, application domains, and knowledge types, three key practical aspects on which tasks can vary. We also introduce GoEval, a multimodal evaluation metric developed using GPT-4o, achieving a correlation factor of 56.71% with human judgments. Our experiments with ten state-of-the-art VLMs reveals that no single model excelling universally, making appropriate selection a key design decision. Proprietary models such as Gemini-1.5-Pro and GPT-4o-mini generally outperform others, though open-source models like InternVL-2-8B and CogVLM-2-Llama-3-19B demonstrate competitive strengths in specific contexts, while providing additional advantages. This study guides the selection of VLMs based on specific task requirements and resource constraints, and can also be extended to other vision-language tasks.
Read more9/17/2024
🏷️
0
Open-ended VQA benchmarking of Vision-Language models by exploiting Classification datasets and their semantic hierarchy
Simon Ging, Mar'ia A. Bravo, Thomas Brox
The evaluation of text-generative vision-language models is a challenging yet crucial endeavor. By addressing the limitations of existing Visual Question Answering (VQA) benchmarks and proposing innovative evaluation methodologies, our research seeks to advance our understanding of these models' capabilities. We propose a novel VQA benchmark based on well-known visual classification datasets which allows a granular evaluation of text-generative vision-language models and their comparison with discriminative vision-language models. To improve the assessment of coarse answers on fine-grained classification tasks, we suggest using the semantic hierarchy of the label space to ask automatically generated follow-up questions about the ground-truth category. Finally, we compare traditional NLP and LLM-based metrics for the problem of evaluating model predictions given ground-truth answers. We perform a human evaluation study upon which we base our decision on the final metric. We apply our benchmark to a suite of vision-language models and show a detailed comparison of their abilities on object, action, and attribute classification. Our contributions aim to lay the foundation for more precise and meaningful assessments, facilitating targeted progress in the exciting field of vision-language modeling.
Read more5/7/2024