First Multi-Dimensional Evaluation of Flowchart Comprehension for Multimodal Large Language Models

0
Sign in to get full access
Overview
• This paper presents the first multi-dimensional evaluation of flowchart comprehension for multimodal large language models (LLMs).
• The researchers assess the ability of LLMs to understand and reason about flowcharts, which are commonly used to represent algorithms and processes.
Plain English Explanation
• Flowcharts are visual diagrams that show the step-by-step flow of a process or algorithm. They are widely used in fields like computer science, business, and engineering.
• As large language models (LLMs) like GPT-3 and DALL-E become more advanced, it's important to understand how well they can comprehend and reason about these types of visual-textual representations.
• The researchers in this paper conducted a comprehensive evaluation to test the flowchart comprehension abilities of several state-of-the-art multimodal LLMs. They looked at different aspects like understanding the overall structure, identifying key components, and answering questions about the flowchart.
• By testing the LLMs on a diverse set of flowcharts, the researchers were able to get a more complete picture of their strengths and limitations in this domain. This kind of multi-dimensional evaluation is crucial for understanding the true capabilities and limitations of these powerful AI models.
Technical Explanation
• The researchers compiled a dataset of 1,000 diverse flowcharts covering a range of topics and complexity levels.
• They then evaluated several prominent multimodal LLMs, including DALL-E, ChartMimic, and M4U, on their ability to:
- Identify the overall structure of the flowchart
- Recognize and classify the different components (e.g., decision points, process steps)
- Answer questions about the content and meaning of the flowchart
• The results showed that while the LLMs performed reasonably well on some tasks, they struggled with more complex reasoning and understanding of the flowchart semantics.
• The researchers also found that performance varied significantly across the different models, highlighting the need for comprehensive, multifaceted evaluations to fully assess the capabilities of these systems.
Critical Analysis
• The paper acknowledges that the dataset used in the evaluation, while diverse, may not be representative of all types of flowcharts encountered in the real world.
• Additionally, the researchers note that the task-based evaluation approach may not capture the full breadth of how these LLMs might be used in practical applications involving flowcharts.
• Further research is needed to explore more open-ended and interactive scenarios where LLMs need to generate, explain, or modify flowcharts based on natural language instructions or queries.
Conclusion
• This study provides the first comprehensive, multi-dimensional evaluation of flowchart comprehension for state-of-the-art multimodal LLMs.
• The findings suggest that while these models have made significant progress in understanding visual-textual representations, there is still room for improvement, particularly when it comes to complex reasoning and semantic understanding.
• The insights from this research can help guide the development of more robust and capable LLMs that can effectively interact with and reason about flowcharts and other types of structured visual information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
First Multi-Dimensional Evaluation of Flowchart Comprehension for Multimodal Large Language Models
Enming Zhang, Ruobing Yao, Huanyong Liu, Junhui Yu, Jiale Wang
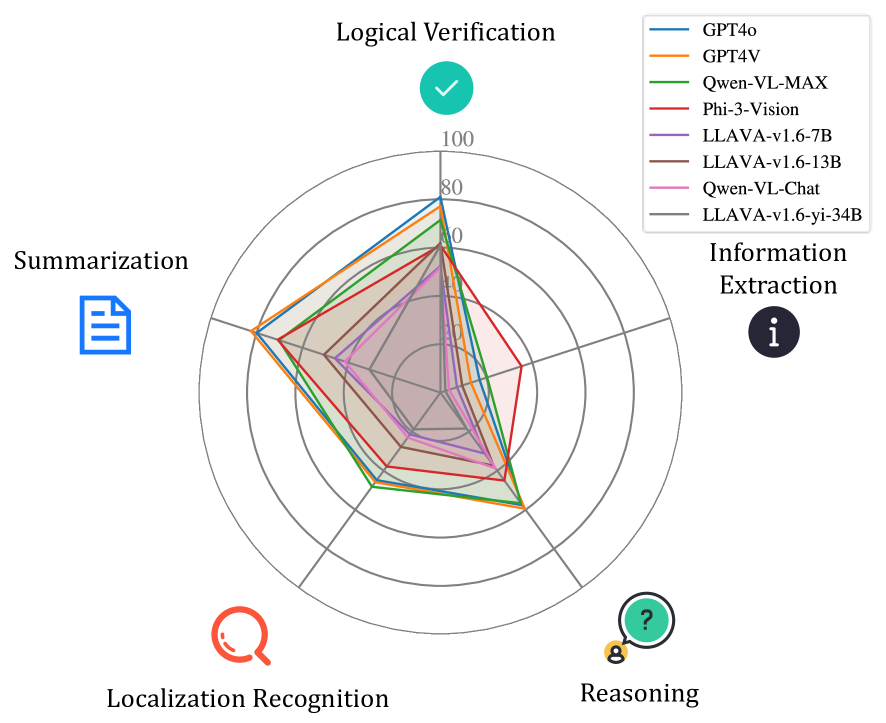
With the development of Multimodal Large Language Models (MLLMs) technology, its general capabilities are increasingly powerful. To evaluate the various abilities of MLLMs, numerous evaluation systems have emerged. But now there is still a lack of a comprehensive method to evaluate MLLMs in the tasks related to flowcharts, which are very important in daily life and work. We propose the first comprehensive method, FlowCE, to assess MLLMs across various dimensions for tasks related to flowcharts. It encompasses evaluating MLLMs' abilities in Reasoning, Localization Recognition, Information Extraction, Logical Verification, and Summarization on flowcharts. However, we find that even the GPT4o model achieves only a score of 56.63. Among open-source models, Phi-3-Vision obtained the highest score of 49.97. We hope that FlowCE can contribute to future research on MLLMs for tasks based on flowcharts. url{https://github.com/360AILAB-NLP/FlowCE} end{abstract}
Read more6/19/2024
0
FlowLearn: Evaluating Large Vision-Language Models on Flowchart Understanding
Huitong Pan, Qi Zhang, Cornelia Caragea, Eduard Dragut, Longin Jan Latecki
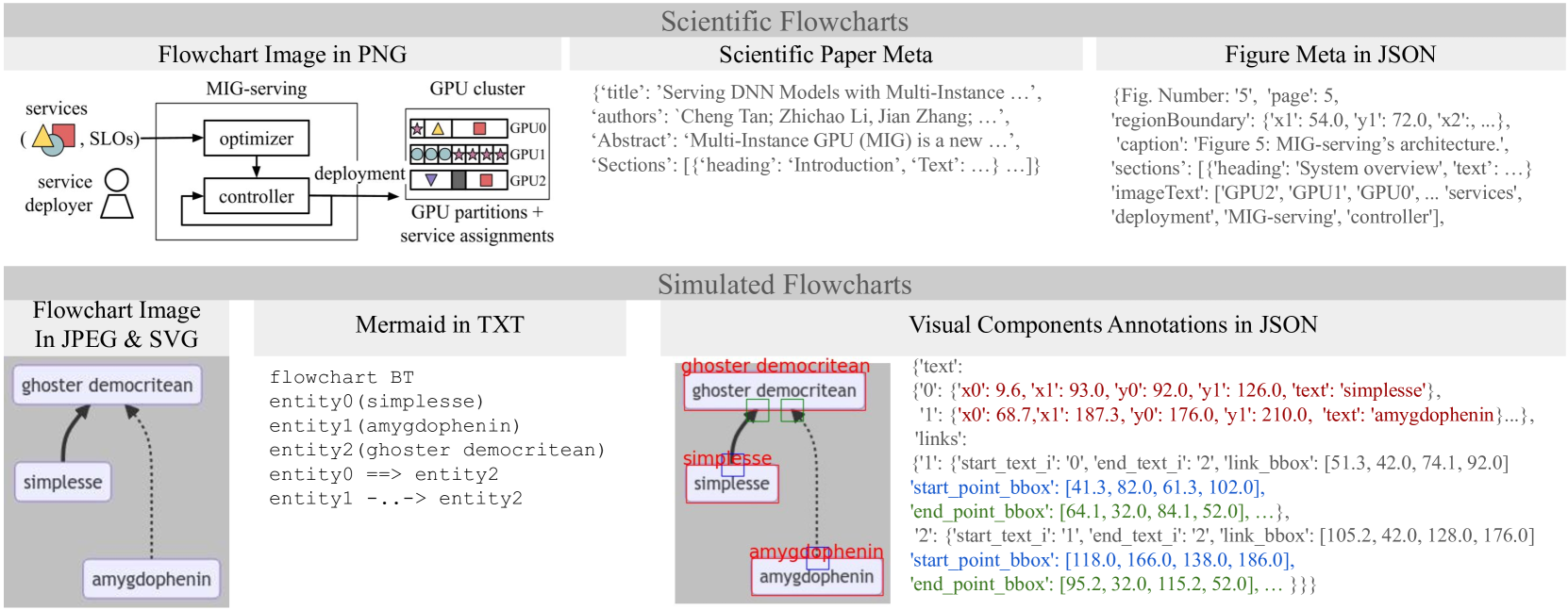
Flowcharts are graphical tools for representing complex concepts in concise visual representations. This paper introduces the FlowLearn dataset, a resource tailored to enhance the understanding of flowcharts. FlowLearn contains complex scientific flowcharts and simulated flowcharts. The scientific subset contains 3,858 flowcharts sourced from scientific literature and the simulated subset contains 10,000 flowcharts created using a customizable script. The dataset is enriched with annotations for visual components, OCR, Mermaid code representation, and VQA question-answer pairs. Despite the proven capabilities of Large Vision-Language Models (LVLMs) in various visual understanding tasks, their effectiveness in decoding flowcharts - a crucial element of scientific communication - has yet to be thoroughly investigated. The FlowLearn test set is crafted to assess the performance of LVLMs in flowchart comprehension. Our study thoroughly evaluates state-of-the-art LVLMs, identifying existing limitations and establishing a foundation for future enhancements in this relatively underexplored domain. For instance, in tasks involving simulated flowcharts, GPT-4V achieved the highest accuracy (58%) in counting the number of nodes, while Claude recorded the highest accuracy (83%) in OCR tasks. Notably, no single model excels in all tasks within the FlowLearn framework, highlighting significant opportunities for further development.
Read more7/11/2024

0
FlowVQA: Mapping Multimodal Logic in Visual Question Answering with Flowcharts
Shubhankar Singh, Purvi Chaurasia, Yerram Varun, Pranshu Pandya, Vatsal Gupta, Vivek Gupta, Dan Roth
Existing benchmarks for visual question answering lack in visual grounding and complexity, particularly in evaluating spatial reasoning skills. We introduce FlowVQA, a novel benchmark aimed at assessing the capabilities of visual question-answering multimodal language models in reasoning with flowcharts as visual contexts. FlowVQA comprises 2,272 carefully generated and human-verified flowchart images from three distinct content sources, along with 22,413 diverse question-answer pairs, to test a spectrum of reasoning tasks, including information localization, decision-making, and logical progression. We conduct a thorough baseline evaluation on a suite of both open-source and proprietary multimodal language models using various strategies, followed by an analysis of directional bias. The results underscore the benchmark's potential as a vital tool for advancing the field of multimodal modeling, providing a focused and challenging environment for enhancing model performance in visual and logical reasoning tasks.
Read more7/1/2024
0
A Survey on Evaluation of Multimodal Large Language Models
Jiaxing Huang, Jingyi Zhang
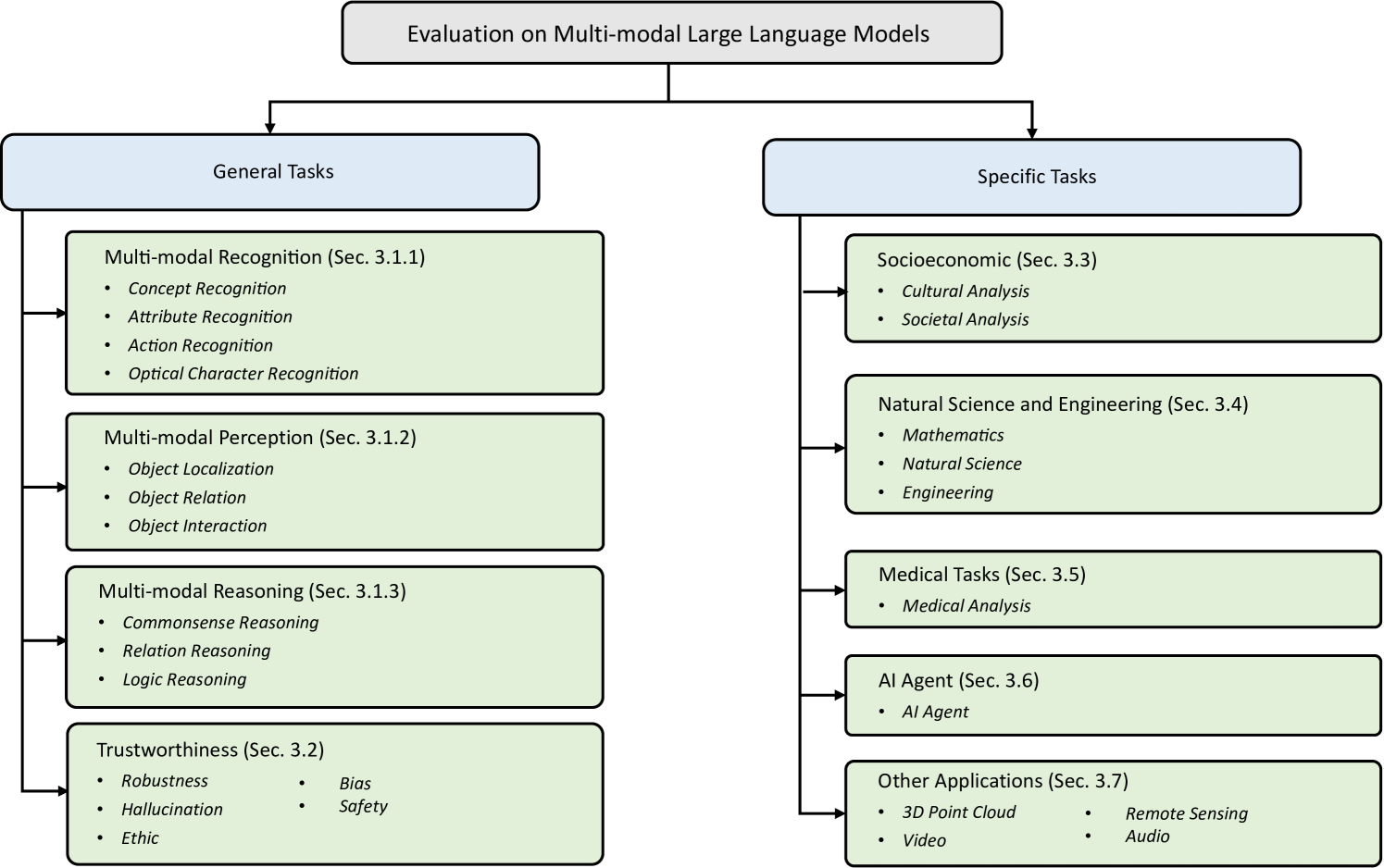
Multimodal Large Language Models (MLLMs) mimic human perception and reasoning system by integrating powerful Large Language Models (LLMs) with various modality encoders (e.g., vision, audio), positioning LLMs as the brain and various modality encoders as sensory organs. This framework endows MLLMs with human-like capabilities, and suggests a potential pathway towards achieving artificial general intelligence (AGI). With the emergence of all-round MLLMs like GPT-4V and Gemini, a multitude of evaluation methods have been developed to assess their capabilities across different dimensions. This paper presents a systematic and comprehensive review of MLLM evaluation methods, covering the following key aspects: (1) the background of MLLMs and their evaluation; (2) what to evaluate that reviews and categorizes existing MLLM evaluation tasks based on the capabilities assessed, including general multimodal recognition, perception, reasoning and trustworthiness, and domain-specific applications such as socioeconomic, natural sciences and engineering, medical usage, AI agent, remote sensing, video and audio processing, 3D point cloud analysis, and others; (3) where to evaluate that summarizes MLLM evaluation benchmarks into general and specific benchmarks; (4) how to evaluate that reviews and illustrates MLLM evaluation steps and metrics; Our overarching goal is to provide valuable insights for researchers in the field of MLLM evaluation, thereby facilitating the development of more capable and reliable MLLMs. We emphasize that evaluation should be regarded as a critical discipline, essential for advancing the field of MLLMs.
Read more8/29/2024