FMiFood: Multi-modal Contrastive Learning for Food Image Classification

0

Sign in to get full access
Overview
- The paper presents a multi-modal contrastive learning approach for food image classification, called FMiFood.
- FMiFood leverages both visual and textual information to improve the performance of food image classification.
- The approach utilizes contrastive learning to effectively learn visual-textual representations for food images.
Plain English Explanation
The researchers developed a new way to classify food images more accurately by using both the visual information in the image and the textual information about the food. Typically, food image classification models only use the visual information in the image, but the researchers found that adding textual information can improve the performance.
The key idea is to use a technique called "contrastive learning" to learn the relationships between the visual and textual data. Contrastive learning works by training the model to recognize when two pieces of data (like an image and some text) belong together, versus when they don't. This helps the model learn meaningful representations of the food images and the associated text.
By combining the visual and textual information in this way, the FMiFood model is able to better identify the contents of food images, compared to using just the visual information alone. This could be useful for applications like recipe recommendation, food logging, or dietary monitoring.
Technical Explanation
The paper introduces the FMiFood model, which uses a multi-modal contrastive learning approach to improve food image classification. The key aspects of the technical approach are:
-
Visual and Textual Encoding: The model uses a pre-trained vision transformer to encode the visual information from food images, and a pre-trained language model to encode the textual information about the foods.
-
Cross-Modal Contrastive Learning: The model is trained using a contrastive learning objective, which encourages the visual and textual representations to be similar for matching image-text pairs, and dissimilar for non-matching pairs. This helps the model learn robust cross-modal representations.
-
Classification Head: The final layer of the model is a classification head that takes the learned cross-modal representations and predicts the food category for a given image.
The researchers evaluate FMiFood on several standard food image classification datasets, and show that it outperforms models that use only visual or only textual information. The multi-modal contrastive learning approach allows FMiFood to learn more discriminative features for food recognition.
Critical Analysis
The paper provides a robust technical evaluation of the FMiFood model, demonstrating its effectiveness on multiple food image classification benchmarks. However, the authors acknowledge some limitations:
- The model requires both visual and textual data for inference, which may not always be available in practical settings.
- The performance gains over vision-only baselines, while statistically significant, are relatively modest in magnitude.
- The paper does not explore the model's generalization to out-of-distribution food categories or its robustness to noisy or incomplete textual descriptions.
Further research could address these limitations by, for example, investigating zero-shot or few-shot learning approaches to handle missing textual data, or exploring more advanced multi-modal fusion techniques to further improve classification accuracy.
Conclusion
The FMiFood model presented in this paper demonstrates the potential of leveraging multi-modal contrastive learning for food image classification. By effectively combining visual and textual information, the model is able to learn richer representations and achieve better performance compared to vision-only approaches.
While the current results are promising, there is still room for improvement in terms of addressing practical limitations and further enhancing the model's capabilities. Nonetheless, this work highlights the value of multi-modal machine learning techniques in building more robust and versatile food recognition systems, with potential applications in areas like smart dietary monitoring and personalized nutrition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FMiFood: Multi-modal Contrastive Learning for Food Image Classification
Xinyue Pan, Jiangpeng He, Fengqing Zhu
Food image classification is the fundamental step in image-based dietary assessment, which aims to estimate participants' nutrient intake from eating occasion images. A common challenge of food images is the intra-class diversity and inter-class similarity, which can significantly hinder classification performance. To address this issue, we introduce a novel multi-modal contrastive learning framework called FMiFood, which learns more discriminative features by integrating additional contextual information, such as food category text descriptions, to enhance classification accuracy. Specifically, we propose a flexible matching technique that improves the similarity matching between text and image embeddings to focus on multiple key information. Furthermore, we incorporate the classification objectives into the framework and explore the use of GPT-4 to enrich the text descriptions and provide more detailed context. Our method demonstrates improved performance on both the UPMC-101 and VFN datasets compared to existing methods.
Read more8/9/2024

0
FoodieQA: A Multimodal Dataset for Fine-Grained Understanding of Chinese Food Culture
Wenyan Li, Xinyu Zhang, Jiaang Li, Qiwei Peng, Raphael Tang, Li Zhou, Weijia Zhang, Guimin Hu, Yifei Yuan, Anders S{o}gaard, Daniel Hershcovich, Desmond Elliott
Food is a rich and varied dimension of cultural heritage, crucial to both individuals and social groups. To bridge the gap in the literature on the often-overlooked regional diversity in this domain, we introduce FoodieQA, a manually curated, fine-grained image-text dataset capturing the intricate features of food cultures across various regions in China. We evaluate vision-language Models (VLMs) and large language models (LLMs) on newly collected, unseen food images and corresponding questions. FoodieQA comprises three multiple-choice question-answering tasks where models need to answer questions based on multiple images, a single image, and text-only descriptions, respectively. While LLMs excel at text-based question answering, surpassing human accuracy, the open-sourced VLMs still fall short by 41% on multi-image and 21% on single-image VQA tasks, although closed-weights models perform closer to human levels (within 10%). Our findings highlight that understanding food and its cultural implications remains a challenging and under-explored direction.
Read more6/18/2024

0
FoodLMM: A Versatile Food Assistant using Large Multi-modal Model
Yuehao Yin, Huiyan Qi, Bin Zhu, Jingjing Chen, Yu-Gang Jiang, Chong-Wah Ngo
Large Multi-modal Models (LMMs) have made impressive progress in many vision-language tasks. Nevertheless, the performance of general LMMs in specific domains is still far from satisfactory. This paper proposes FoodLMM, a versatile food assistant based on LMMs with various capabilities, including food recognition, ingredient recognition, recipe generation, nutrition estimation, food segmentation and multi-round conversation. To facilitate FoodLMM to deal with tasks beyond pure text output, we introduce a series of novel task-specific tokens and heads, enabling the model to predict food nutritional values and multiple segmentation masks. We adopt a two-stage training strategy. In the first stage, we utilize multiple public food benchmarks for multi-task learning by leveraging the instruct-following paradigm. In the second stage, we construct a multi-round conversation dataset and a reasoning segmentation dataset to fine-tune the model, enabling it to conduct professional dialogues and generate segmentation masks based on complex reasoning in the food domain. Our fine-tuned FoodLMM achieves state-of-the-art results across several food benchmarks. We will make our code, models and datasets publicly available.
Read more4/15/2024
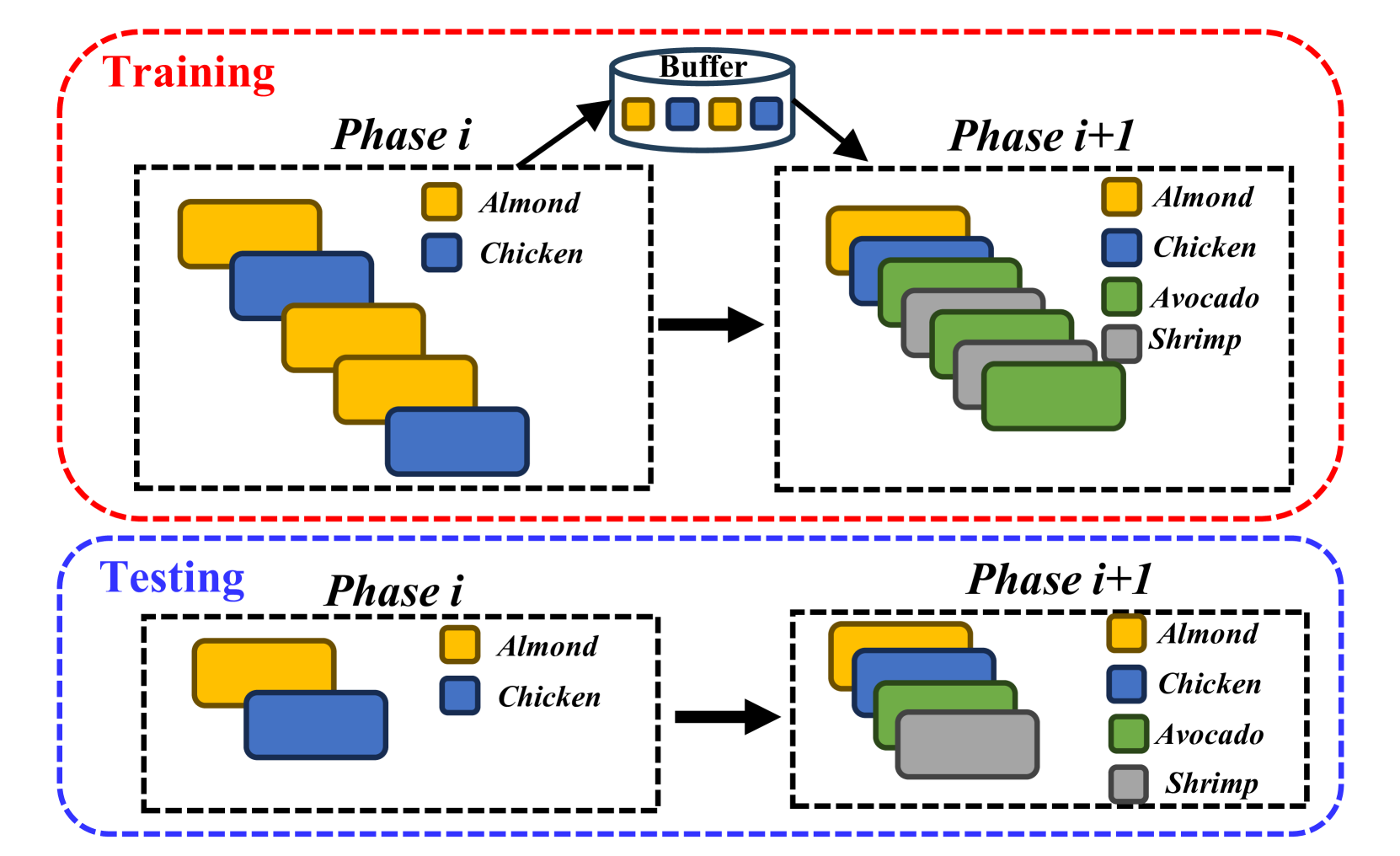
0
Learning to Classify New Foods Incrementally Via Compressed Exemplars
Justin Yang, Zhihao Duan, Jiangpeng He, Fengqing Zhu
Food image classification systems play a crucial role in health monitoring and diet tracking through image-based dietary assessment techniques. However, existing food recognition systems rely on static datasets characterized by a pre-defined fixed number of food classes. This contrasts drastically with the reality of food consumption, which features constantly changing data. Therefore, food image classification systems should adapt to and manage data that continuously evolves. This is where continual learning plays an important role. A challenge in continual learning is catastrophic forgetting, where ML models tend to discard old knowledge upon learning new information. While memory-replay algorithms have shown promise in mitigating this problem by storing old data as exemplars, they are hampered by the limited capacity of memory buffers, leading to an imbalance between new and previously learned data. To address this, our work explores the use of neural image compression to extend buffer size and enhance data diversity. We introduced the concept of continuously learning a neural compression model to adaptively improve the quality of compressed data and optimize the bitrates per pixel (bpp) to store more exemplars. Our extensive experiments, including evaluations on food-specific datasets including Food-101 and VFN-74, as well as the general dataset ImageNet-100, demonstrate improvements in classification accuracy. This progress is pivotal in advancing more realistic food recognition systems that are capable of adapting to continually evolving data. Moreover, the principles and methodologies we've developed hold promise for broader applications, extending their benefits to other domains of continual machine learning systems.
Read more4/12/2024