FoodLMM: A Versatile Food Assistant using Large Multi-modal Model

0

Sign in to get full access
Overview
- This paper introduces FoodLMM, a versatile food assistant that leverages large multi-modal models to assist users with a variety of food-related tasks.
- FoodLMM can help users with recipe recommendations, meal planning, dietary guidance, and more by integrating visual, textual, and other modalities.
- The paper explores the potential of large multi-modal models to provide a comprehensive and intelligent food assistant system.
Plain English Explanation
FoodLMM is a new technology that uses large, sophisticated AI models to help people with all kinds of food-related tasks. These models can understand and process different types of information, like text, images, and even audio. This allows FoodLMM to do things like recommend recipes, plan meals, and provide dietary guidance.
For example, if you take a picture of a dish you're thinking of making, FoodLMM can analyze the image and give you information about the ingredients, nutritional content, and even suggest similar recipes you might like. Or if you describe the kind of meal you're craving, FoodLMM can search its database of recipes and suggest options that fit your preferences.
The key idea behind FoodLMM is to leverage the power of large, multi-modal AI models to create a comprehensive and intelligent food assistant. By combining different types of information and understanding, FoodLMM can provide more personalized and useful support to users compared to traditional food-related tools or apps.
Technical Explanation
The paper introduces FoodLMM: A Versatile Food Assistant using Large Multi-modal Model, which leverages large multi-modal models to assist users with a variety of food-related tasks. These models are able to process and integrate information from multiple modalities, such as text, images, and even audio.
The system architecture of FoodLMM is designed to take advantage of prompt-based techniques to enhance the model's understanding and generation capabilities. By prompting the model with multi-modal tokens, FoodLMM can provide personalized recommendations, dietary guidance, and other food-related support to users.
The paper also discusses the potential of efficiently transforming modalities within large language models to further improve the versatility and performance of FoodLMM.
Critical Analysis
The paper presents a compelling vision for FoodLMM as a comprehensive food assistant, but it also acknowledges some potential limitations and areas for further research. For example, the paper notes that the performance and reliability of FoodLMM may be dependent on the quality and breadth of the underlying multi-modal data used to train the models.
Additionally, the paper suggests that further research is needed to understand the long-term implications of relying on large multi-modal models for food-related decision making, particularly in terms of potential biases or inconsistencies that may arise.
Overall, the paper makes a strong case for the potential of FoodLMM, but also highlights the need for continued exploration and validation of this approach to ensure it provides a reliable and trustworthy food assistant for users.
Conclusion
The FoodLMM paper introduces a promising approach to leveraging large multi-modal models to create a versatile and intelligent food assistant system. By integrating various information modalities, FoodLMM has the potential to provide personalized and comprehensive support for users in a wide range of food-related tasks.
While the research shows the feasibility and potential benefits of this approach, it also identifies areas for further study, such as ensuring the reliability and trustworthiness of the system. As multi-modal AI models continue to advance, the insights and ideas presented in this paper could have significant implications for the future of food-related technologies and their impact on our daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FoodLMM: A Versatile Food Assistant using Large Multi-modal Model
Yuehao Yin, Huiyan Qi, Bin Zhu, Jingjing Chen, Yu-Gang Jiang, Chong-Wah Ngo
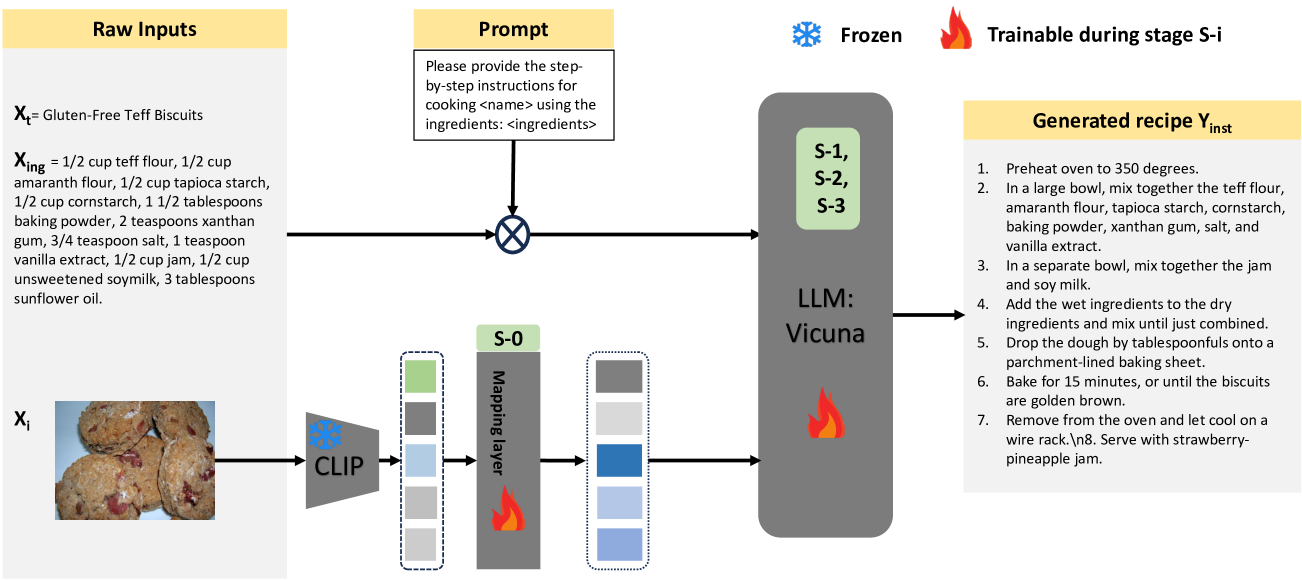
Large Multi-modal Models (LMMs) have made impressive progress in many vision-language tasks. Nevertheless, the performance of general LMMs in specific domains is still far from satisfactory. This paper proposes FoodLMM, a versatile food assistant based on LMMs with various capabilities, including food recognition, ingredient recognition, recipe generation, nutrition estimation, food segmentation and multi-round conversation. To facilitate FoodLMM to deal with tasks beyond pure text output, we introduce a series of novel task-specific tokens and heads, enabling the model to predict food nutritional values and multiple segmentation masks. We adopt a two-stage training strategy. In the first stage, we utilize multiple public food benchmarks for multi-task learning by leveraging the instruct-following paradigm. In the second stage, we construct a multi-round conversation dataset and a reasoning segmentation dataset to fine-tune the model, enabling it to conduct professional dialogues and generate segmentation masks based on complex reasoning in the food domain. Our fine-tuned FoodLMM achieves state-of-the-art results across several food benchmarks. We will make our code, models and datasets publicly available.
Read more4/15/2024

0
RoDE: Linear Rectified Mixture of Diverse Experts for Food Large Multi-Modal Models
Pengkun Jiao, Xinlan Wu, Bin Zhu, Jingjing Chen, Chong-Wah Ngo, Yugang Jiang
Large Multi-modal Models (LMMs) have significantly advanced a variety of vision-language tasks. The scalability and availability of high-quality training data play a pivotal role in the success of LMMs. In the realm of food, while comprehensive food datasets such as Recipe1M offer an abundance of ingredient and recipe information, they often fall short of providing ample data for nutritional analysis. The Recipe1M+ dataset, despite offering a subset for nutritional evaluation, is limited in the scale and accuracy of nutrition information. To bridge this gap, we introduce Uni-Food, a unified food dataset that comprises over 100,000 images with various food labels, including categories, ingredients, recipes, and ingredient-level nutritional information. Uni-Food is designed to provide a more holistic approach to food data analysis, thereby enhancing the performance and capabilities of LMMs in this domain. To mitigate the conflicts arising from multi-task supervision during fine-tuning of LMMs, we introduce a novel Linear Rectification Mixture of Diverse Experts (RoDE) approach. RoDE utilizes a diverse array of experts to address tasks of varying complexity, thereby facilitating the coordination of trainable parameters, i.e., it allocates more parameters for more complex tasks and, conversely, fewer parameters for simpler tasks. RoDE implements linear rectification union to refine the router's functionality, thereby enhancing the efficiency of sparse task allocation. These design choices endow RoDE with features that ensure GPU memory efficiency and ease of optimization. Our experimental results validate the effectiveness of our proposed approach in addressing the inherent challenges of food-related multitasking.
Read more7/18/2024
0
LLaVA-Chef: A Multi-modal Generative Model for Food Recipes
Fnu Mohbat, Mohammed J. Zaki
In the rapidly evolving landscape of online recipe sharing within a globalized context, there has been a notable surge in research towards comprehending and generating food recipes. Recent advancements in large language models (LLMs) like GPT-2 and LLaVA have paved the way for Natural Language Processing (NLP) approaches to delve deeper into various facets of food-related tasks, encompassing ingredient recognition and comprehensive recipe generation. Despite impressive performance and multi-modal adaptability of LLMs, domain-specific training remains paramount for their effective application. This work evaluates existing LLMs for recipe generation and proposes LLaVA-Chef, a novel model trained on a curated dataset of diverse recipe prompts in a multi-stage approach. First, we refine the mapping of visual food image embeddings to the language space. Second, we adapt LLaVA to the food domain by fine-tuning it on relevant recipe data. Third, we utilize diverse prompts to enhance the model's recipe comprehension. Finally, we improve the linguistic quality of generated recipes by penalizing the model with a custom loss function. LLaVA-Chef demonstrates impressive improvements over pretrained LLMs and prior works. A detailed qualitative analysis reveals that LLaVA-Chef generates more detailed recipes with precise ingredient mentions, compared to existing approaches.
Read more9/2/2024

0
FMiFood: Multi-modal Contrastive Learning for Food Image Classification
Xinyue Pan, Jiangpeng He, Fengqing Zhu
Food image classification is the fundamental step in image-based dietary assessment, which aims to estimate participants' nutrient intake from eating occasion images. A common challenge of food images is the intra-class diversity and inter-class similarity, which can significantly hinder classification performance. To address this issue, we introduce a novel multi-modal contrastive learning framework called FMiFood, which learns more discriminative features by integrating additional contextual information, such as food category text descriptions, to enhance classification accuracy. Specifically, we propose a flexible matching technique that improves the similarity matching between text and image embeddings to focus on multiple key information. Furthermore, we incorporate the classification objectives into the framework and explore the use of GPT-4 to enrich the text descriptions and provide more detailed context. Our method demonstrates improved performance on both the UPMC-101 and VFN datasets compared to existing methods.
Read more8/9/2024