FoRAG: Factuality-optimized Retrieval Augmented Generation for Web-enhanced Long-form Question Answering

0
Sign in to get full access
Overview
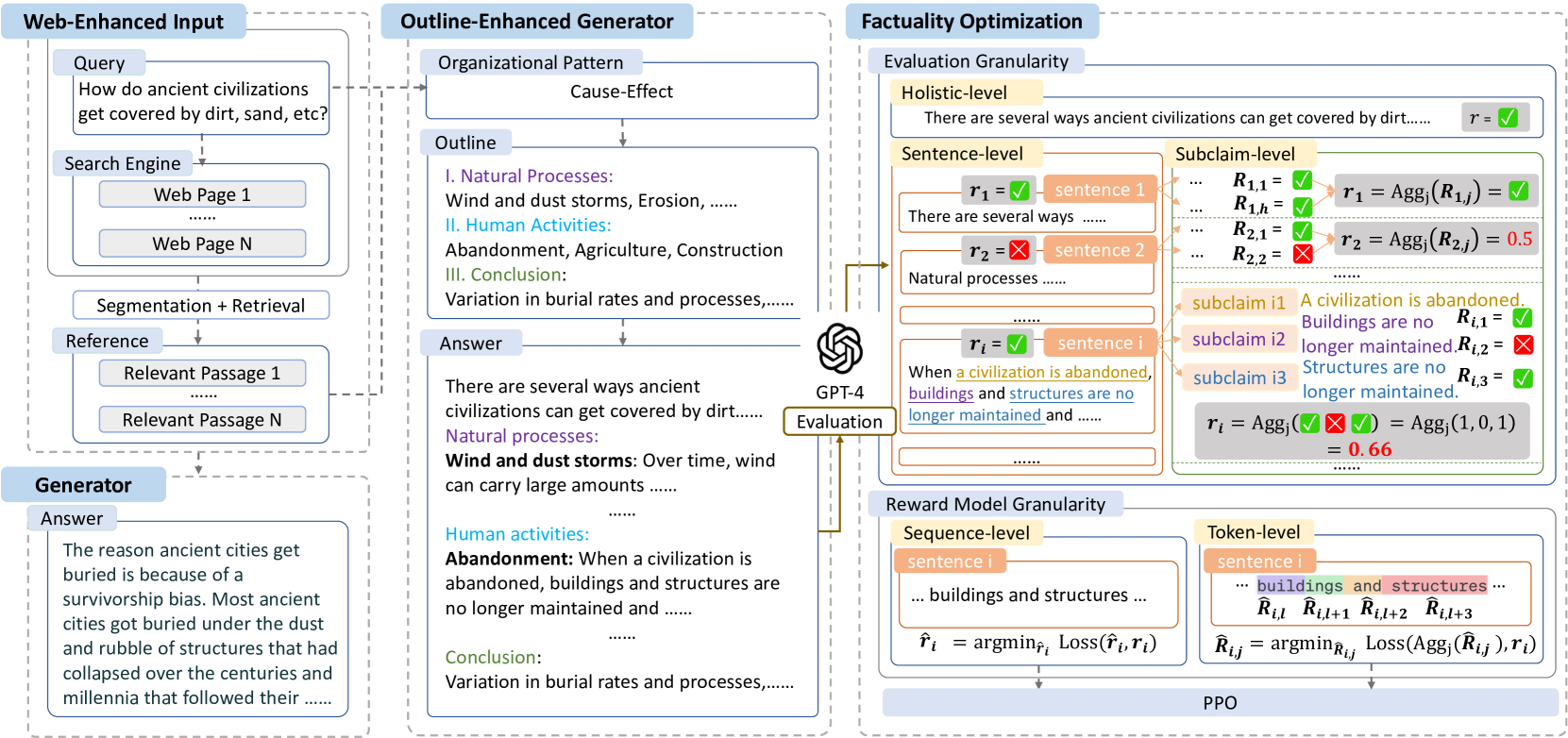
- This paper presents FoRAG, a Factuality-optimized Retrieval Augmented Generation model for web-enhanced long-form question answering.
- FoRAG leverages both retrieval and generation to provide comprehensive answers to complex questions, drawing information from relevant web pages.
- The key innovations include a factuality-aware retrieval module and a generation model that optimizes for factual accuracy.
Plain English Explanation
FoRAG is a system that can answer complex questions by combining information from web pages. It has two main parts:
-
A retrieval module that finds relevant web pages to help answer the question. This module is designed to prioritize pages that contain factual information.
-
A generation module that uses the retrieved web pages to generate a final answer. This generation model is trained to produce answers that are as factually accurate as possible.
The goal of FoRAG is to provide long-form answers to difficult questions while ensuring the information is reliable and true. By combining retrieval and generation, it can draw upon a wide range of sources to craft comprehensive responses, while the factuality-focused design helps maintain high accuracy.
Technical Explanation
FoRAG builds on prior work in retrieval-augmented generation and collaborative retrieval-augmented generation approaches. It introduces a novel factuality-aware retrieval module and a generation model optimized for factual accuracy.
The retrieval module uses a dual-encoder architecture to match the question with relevant web pages, but it is trained to prioritize pages containing factual information over those with subjective or opinionated content. This is achieved through a factuality scoring model that assesses the truthfulness of candidate pages.
The generation module then takes the retrieved pages and generates a long-form answer using a transformer-based language model. However, this model is fine-tuned not only on question-answer pairs, but also on factual consistency, encouraging the generated text to adhere closely to the information present in the source documents.
The authors evaluate FoRAG on web-enhanced question answering benchmarks and show that it outperforms prior retrieval-augmented generation approaches in terms of both factual accuracy and overall answer quality.
Critical Analysis
The paper presents a compelling approach to improving the factual reliability of long-form question answering systems. By explicitly modeling factuality in both the retrieval and generation components, FoRAG takes an important step towards making these systems more trustworthy and useful in real-world applications.
That said, the authors acknowledge several limitations and areas for future work. For example, the factuality scoring model relies on heuristics and may not capture all nuances of truthfulness. Additionally, the generation model is trained on existing question-answer pairs, which could introduce biases or inaccuracies present in the training data.
Further research could explore more sophisticated techniques for assessing factuality, such as leveraging knowledge graphs or fact-checking services. Integrating other signals of reliability, like source credibility or consensus across multiple documents, could also enhance the system's ability to identify and convey truthful information.
Conclusion
FoRAG represents an important advancement in web-enhanced long-form question answering by prioritizing factual accuracy. Its combination of factuality-aware retrieval and generation optimized for truthfulness helps address a critical challenge in building trustworthy AI systems.
While the current implementation has some limitations, the core ideas behind FoRAG - bridging retrieval and generation while emphasizing factual reliability - offer a promising direction for future research in this domain. As AI systems become more integral to how people access information, approaches like FoRAG will be crucial for ensuring the veracity and usefulness of the responses they provide.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FoRAG: Factuality-optimized Retrieval Augmented Generation for Web-enhanced Long-form Question Answering
Tianchi Cai, Zhiwen Tan, Xierui Song, Tao Sun, Jiyan Jiang, Yunqi Xu, Yinger Zhang, Jinjie Gu
Retrieval Augmented Generation (RAG) has become prevalent in question-answering (QA) tasks due to its ability of utilizing search engine to enhance the quality of long-form question-answering (LFQA). Despite the emergence of various open source methods and web-enhanced commercial systems such as Bing Chat, two critical problems remain unsolved, i.e., the lack of factuality and clear logic in the generated long-form answers. In this paper, we remedy these issues via a systematic study on answer generation in web-enhanced LFQA. Specifically, we first propose a novel outline-enhanced generator to achieve clear logic in the generation of multifaceted answers and construct two datasets accordingly. Then we propose a factuality optimization method based on a carefully designed doubly fine-grained RLHF framework, which contains automatic evaluation and reward modeling in different levels of granularity. Our generic framework comprises conventional fine-grained RLHF methods as special cases. Extensive experiments verify the superiority of our proposed textit{Factuality-optimized RAG (FoRAG)} method on both English and Chinese benchmarks. In particular, when applying our method to Llama2-7B-chat, the derived model FoRAG-L-7B outperforms WebGPT-175B in terms of three commonly used metrics (i.e., coherence, helpfulness, and factuality), while the number of parameters is much smaller (only 1/24 of that of WebGPT-175B). Our datasets and models are made publicly available for better reproducibility: https://huggingface.co/forag.
Read more6/21/2024

0
RAG-QA Arena: Evaluating Domain Robustness for Long-form Retrieval Augmented Question Answering
Rujun Han, Yuhao Zhang, Peng Qi, Yumo Xu, Jenyuan Wang, Lan Liu, William Yang Wang, Bonan Min, Vittorio Castelli
Question answering based on retrieval augmented generation (RAG-QA) is an important research topic in NLP and has a wide range of real-world applications. However, most existing datasets for this task are either constructed using a single source corpus or consist of short extractive answers, which fall short of evaluating large language model (LLM) based RAG-QA systems on cross-domain generalization. To address these limitations, we create Long-form RobustQA (LFRQA), a new dataset comprising human-written long-form answers that integrate short extractive answers from multiple documents into a single, coherent narrative, covering 26K queries and large corpora across seven different domains. We further propose RAG-QA Arena by directly comparing model-generated answers against LFRQA's answers using LLMs as evaluators. We show via extensive experiments that RAG-QA Arena and human judgments on answer quality are highly correlated. Moreover, only 41.3% of the most competitive LLM's answers are preferred to LFRQA's answers, demonstrating RAG-QA Arena as a challenging evaluation platform for future research.
Read more7/22/2024

0
RichRAG: Crafting Rich Responses for Multi-faceted Queries in Retrieval-Augmented Generation
Shuting Wang, Xin Yu, Mang Wang, Weipeng Chen, Yutao Zhu, Zhicheng Dou
Retrieval-augmented generation (RAG) effectively addresses issues of static knowledge and hallucination in large language models. Existing studies mostly focus on question scenarios with clear user intents and concise answers. However, it is prevalent that users issue broad, open-ended queries with diverse sub-intents, for which they desire rich and long-form answers covering multiple relevant aspects. To tackle this important yet underexplored problem, we propose a novel RAG framework, namely RichRAG. It includes a sub-aspect explorer to identify potential sub-aspects of input questions, a multi-faceted retriever to build a candidate pool of diverse external documents related to these sub-aspects, and a generative list-wise ranker, which is a key module to provide the top-k most valuable documents for the final generator. These ranked documents sufficiently cover various query aspects and are aware of the generator's preferences, hence incentivizing it to produce rich and comprehensive responses for users. The training of our ranker involves a supervised fine-tuning stage to ensure the basic coverage of documents, and a reinforcement learning stage to align downstream LLM's preferences to the ranking of documents. Experimental results on two publicly available datasets prove that our framework effectively and efficiently provides comprehensive and satisfying responses to users.
Read more6/26/2024

0
SFR-RAG: Towards Contextually Faithful LLMs
Xuan-Phi Nguyen, Shrey Pandit, Senthil Purushwalkam, Austin Xu, Hailin Chen, Yifei Ming, Zixuan Ke, Silvio Savarese, Caiming Xong, Shafiq Joty
Retrieval Augmented Generation (RAG), a paradigm that integrates external contextual information with large language models (LLMs) to enhance factual accuracy and relevance, has emerged as a pivotal area in generative AI. The LLMs used in RAG applications are required to faithfully and completely comprehend the provided context and users' questions, avoid hallucination, handle unanswerable, counterfactual or otherwise low-quality and irrelevant contexts, perform complex multi-hop reasoning and produce reliable citations. In this paper, we introduce SFR-RAG, a small LLM that is instruction-tuned with an emphasis on context-grounded generation and hallucination minimization. We also present ContextualBench, a new evaluation framework compiling multiple popular and diverse RAG benchmarks, such as HotpotQA and TriviaQA, with consistent RAG settings to ensure reproducibility and consistency in model assessments. Experimental results demonstrate that our SFR-RAG-9B model outperforms leading baselines such as Command-R+ (104B) and GPT-4o, achieving state-of-the-art results in 3 out of 7 benchmarks in ContextualBench with significantly fewer parameters. The model is also shown to be resilient to alteration in the contextual information and behave appropriately when relevant context is removed. Additionally, the SFR-RAG model maintains competitive performance in general instruction-following tasks and function-calling capabilities.
Read more9/17/2024