RAG-QA Arena: Evaluating Domain Robustness for Long-form Retrieval Augmented Question Answering

0

Sign in to get full access
Overview
- The paper evaluates the domain robustness of long-form retrieval-augmented question answering (RAG-QA) systems.
- It introduces the RAG-QA Arena, a benchmark for assessing the performance of RAG-QA models across different domains.
- The study examines how well RAG-QA models can handle questions from diverse domains, including ones not seen during training.
Plain English Explanation
The paper looks at how well AI systems can answer long, complex questions by combining information from various sources. These "retrieval-augmented question answering" (RAG-QA) systems can be very useful, but the researchers wanted to see how they perform on questions from different subject areas, not just the ones they were trained on.
To do this, the researchers created the "RAG-QA Arena" - a set of benchmark tests that cover a wide range of topics, from science and history to sports and pop culture. By testing RAG-QA models on this diverse set of questions, the researchers could evaluate how "domain-robust" the systems are - in other words, how well they can adapt to questions outside their original training.
The key idea is that a truly capable RAG-QA system should be able to handle questions from many different domains, not just the ones it was specifically trained on. This is important for real-world applications, where the system might need to answer all kinds of questions, not just ones from a narrow subject area.
Technical Explanation
The paper introduces the RAG-QA Arena, a novel benchmark for evaluating the domain robustness of retrieval-augmented question answering (RAG-QA) systems. RAG-QA models combine a question-answering neural network with a retrieval system that pulls relevant information from a knowledge base to generate long-form answers.
The RAG-QA Arena consists of a diverse set of question-answer pairs spanning 10 different domains, including science, history, sports, and entertainment. By testing RAG-QA models on this heterogeneous dataset, the researchers can assess how well the systems can handle questions outside their original training distribution.
The paper evaluates several state-of-the-art RAG-QA models on the benchmark, measuring their performance across domains using both automatic metrics and human evaluation. The results reveal that existing RAG-QA systems struggle with domain generalization, often performing much better on questions from domains similar to their training data.
The authors also investigate ways to improve domain robustness, such as iterative fine-tuning and adaptive retrieval. However, they find that significant challenges remain in building RAG-QA systems that can truly excel across a wide range of subject areas.
Critical Analysis
The paper makes a valuable contribution by highlighting the limitations of current RAG-QA systems in handling questions from diverse domains. The RAG-QA Arena benchmark is a well-designed test bed for evaluating domain robustness, and the results clearly show that existing models struggle to generalize beyond their training data.
One potential limitation of the study is the reliance on automatic evaluation metrics, which may not fully capture the nuances of long-form question answering. The inclusion of human evaluation helps address this, but more work is needed to develop reliable and comprehensive evaluation frameworks for this task.
Additionally, while the paper explores some techniques to improve domain robustness, such as iterative fine-tuning, the authors acknowledge that significant challenges remain. Further research is needed to develop more effective methods for building RAG-QA systems that can truly excel across a wide range of subject areas.
Conclusion
The RAG-QA Arena paper sheds light on an important limitation of current retrieval-augmented question answering systems - their lack of domain robustness. By introducing a diverse benchmark and evaluating state-of-the-art models, the study demonstrates that existing RAG-QA systems struggle to handle questions beyond their original training distribution.
These findings have significant implications for the deployment of RAG-QA technologies in real-world applications, where the ability to answer questions across a wide range of domains is essential. The paper's call for further research into improving domain robustness is a crucial step in advancing the field of long-form question answering and making these systems more broadly useful.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RAG-QA Arena: Evaluating Domain Robustness for Long-form Retrieval Augmented Question Answering
Rujun Han, Yuhao Zhang, Peng Qi, Yumo Xu, Jenyuan Wang, Lan Liu, William Yang Wang, Bonan Min, Vittorio Castelli
Question answering based on retrieval augmented generation (RAG-QA) is an important research topic in NLP and has a wide range of real-world applications. However, most existing datasets for this task are either constructed using a single source corpus or consist of short extractive answers, which fall short of evaluating large language model (LLM) based RAG-QA systems on cross-domain generalization. To address these limitations, we create Long-form RobustQA (LFRQA), a new dataset comprising human-written long-form answers that integrate short extractive answers from multiple documents into a single, coherent narrative, covering 26K queries and large corpora across seven different domains. We further propose RAG-QA Arena by directly comparing model-generated answers against LFRQA's answers using LLMs as evaluators. We show via extensive experiments that RAG-QA Arena and human judgments on answer quality are highly correlated. Moreover, only 41.3% of the most competitive LLM's answers are preferred to LFRQA's answers, demonstrating RAG-QA Arena as a challenging evaluation platform for future research.
Read more7/22/2024
0
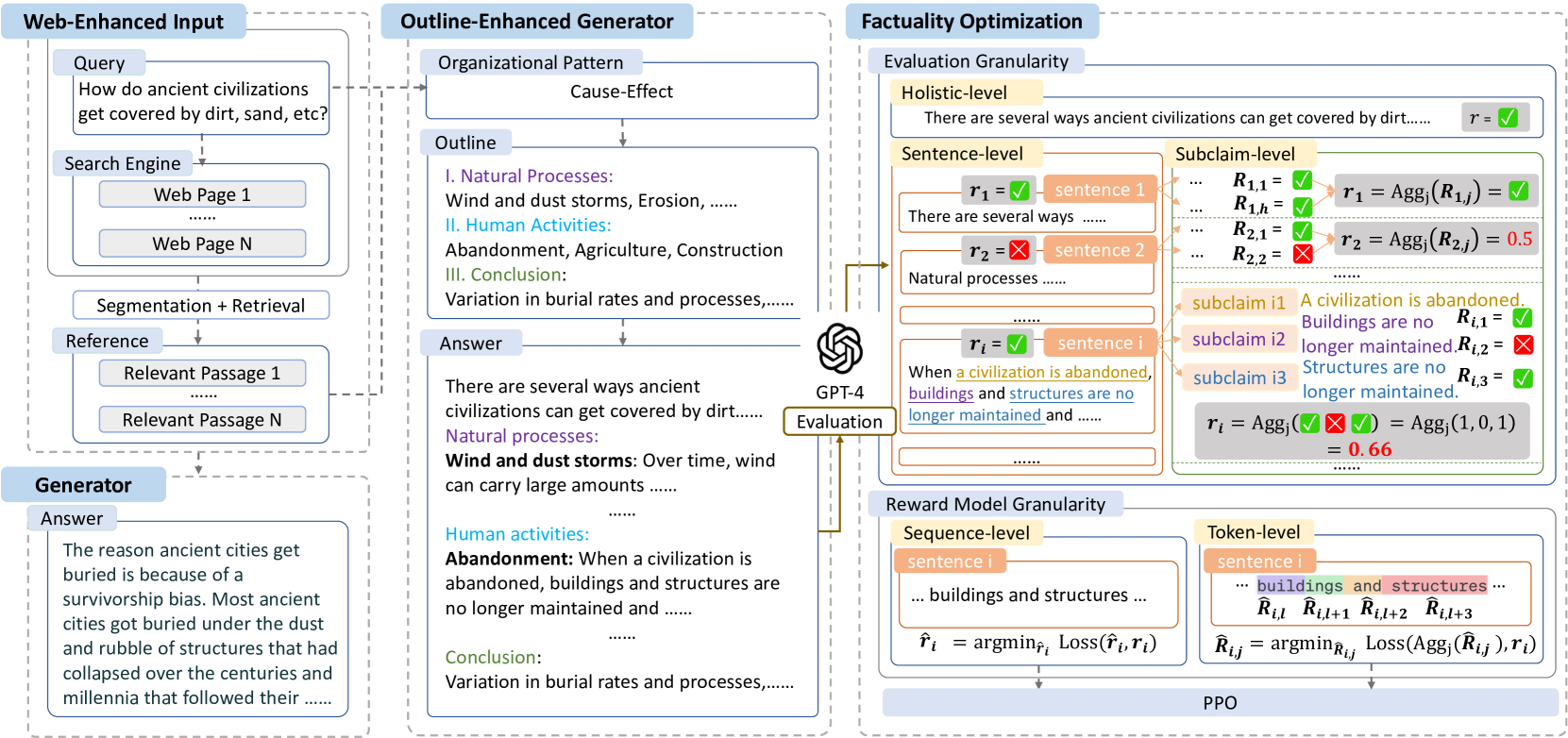
FoRAG: Factuality-optimized Retrieval Augmented Generation for Web-enhanced Long-form Question Answering
Tianchi Cai, Zhiwen Tan, Xierui Song, Tao Sun, Jiyan Jiang, Yunqi Xu, Yinger Zhang, Jinjie Gu
Retrieval Augmented Generation (RAG) has become prevalent in question-answering (QA) tasks due to its ability of utilizing search engine to enhance the quality of long-form question-answering (LFQA). Despite the emergence of various open source methods and web-enhanced commercial systems such as Bing Chat, two critical problems remain unsolved, i.e., the lack of factuality and clear logic in the generated long-form answers. In this paper, we remedy these issues via a systematic study on answer generation in web-enhanced LFQA. Specifically, we first propose a novel outline-enhanced generator to achieve clear logic in the generation of multifaceted answers and construct two datasets accordingly. Then we propose a factuality optimization method based on a carefully designed doubly fine-grained RLHF framework, which contains automatic evaluation and reward modeling in different levels of granularity. Our generic framework comprises conventional fine-grained RLHF methods as special cases. Extensive experiments verify the superiority of our proposed textit{Factuality-optimized RAG (FoRAG)} method on both English and Chinese benchmarks. In particular, when applying our method to Llama2-7B-chat, the derived model FoRAG-L-7B outperforms WebGPT-175B in terms of three commonly used metrics (i.e., coherence, helpfulness, and factuality), while the number of parameters is much smaller (only 1/24 of that of WebGPT-175B). Our datasets and models are made publicly available for better reproducibility: https://huggingface.co/forag.
Read more6/21/2024
0
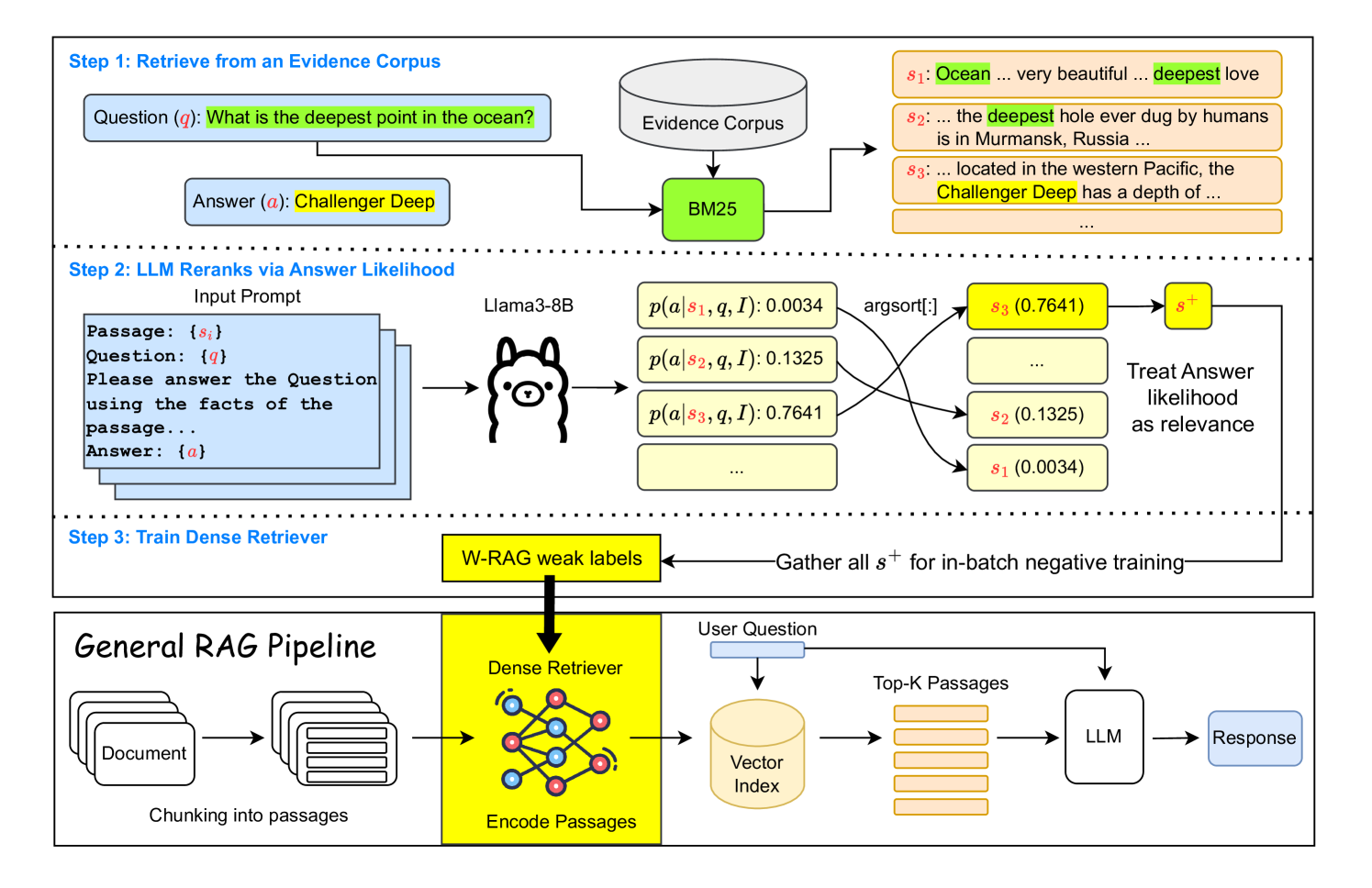
W-RAG: Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering
Jinming Nian, Zhiyuan Peng, Qifan Wang, Yi Fang
In knowledge-intensive tasks such as open-domain question answering (OpenQA), Large Language Models (LLMs) often struggle to generate factual answers relying solely on their internal (parametric) knowledge. To address this limitation, Retrieval-Augmented Generation (RAG) systems enhance LLMs by retrieving relevant information from external sources, thereby positioning the retriever as a pivotal component. Although dense retrieval demonstrates state-of-the-art performance, its training poses challenges due to the scarcity of ground-truth evidence, largely attributed to the high costs of human annotation. In this paper, we propose W-RAG by utilizing the ranking capabilities of LLMs to create weakly labeled data for training dense retrievers. Specifically, we rerank the top-$K$ passages retrieved via BM25 by assessing the probability that LLMs will generate the correct answer based on the question and each passage. The highest-ranking passages are then used as positive training examples for dense retrieval. Our comprehensive experiments across four publicly available OpenQA datasets demonstrate that our approach enhances both retrieval and OpenQA performance compared to baseline models.
Read more8/19/2024
💬
0
Enhancing Large Language Models with Domain-specific Retrieval Augment Generation: A Case Study on Long-form Consumer Health Question Answering in Ophthalmology
Aidan Gilson, Xuguang Ai, Thilaka Arunachalam, Ziyou Chen, Ki Xiong Cheong, Amisha Dave, Cameron Duic, Mercy Kibe, Annette Kaminaka, Minali Prasad, Fares Siddig, Maxwell Singer, Wendy Wong, Qiao Jin, Tiarnan D. L. Keenan, Xia Hu, Emily Y. Chew, Zhiyong Lu, Hua Xu, Ron A. Adelman, Yih-Chung Tham, Qingyu Chen
Despite the potential of Large Language Models (LLMs) in medicine, they may generate responses lacking supporting evidence or based on hallucinated evidence. While Retrieval Augment Generation (RAG) is popular to address this issue, few studies implemented and evaluated RAG in downstream domain-specific applications. We developed a RAG pipeline with 70,000 ophthalmology-specific documents that retrieve relevant documents to augment LLMs during inference time. In a case study on long-form consumer health questions, we systematically evaluated the responses including over 500 references of LLMs with and without RAG on 100 questions with 10 healthcare professionals. The evaluation focuses on factuality of evidence, selection and ranking of evidence, attribution of evidence, and answer accuracy and completeness. LLMs without RAG provided 252 references in total. Of which, 45.3% hallucinated, 34.1% consisted of minor errors, and 20.6% were correct. In contrast, LLMs with RAG significantly improved accuracy (54.5% being correct) and reduced error rates (18.8% with minor hallucinations and 26.7% with errors). 62.5% of the top 10 documents retrieved by RAG were selected as the top references in the LLM response, with an average ranking of 4.9. The use of RAG also improved evidence attribution (increasing from 1.85 to 2.49 on a 5-point scale, P<0.001), albeit with slight decreases in accuracy (from 3.52 to 3.23, P=0.03) and completeness (from 3.47 to 3.27, P=0.17). The results demonstrate that LLMs frequently exhibited hallucinated and erroneous evidence in the responses, raising concerns for downstream applications in the medical domain. RAG substantially reduced the proportion of such evidence but encountered challenges.
Read more9/24/2024