RichRAG: Crafting Rich Responses for Multi-faceted Queries in Retrieval-Augmented Generation

0

Sign in to get full access
Overview
- This paper proposes RichRAG, a novel retrieval-augmented generation (RAG) model that can craft rich and multi-faceted responses to complex queries.
- RichRAG combines a retrieval module that selects relevant information from a knowledge base with a generation module that synthesizes this information into a coherent and informative response.
- The key innovation of RichRAG is its ability to capture diverse aspects of a query and generate responses that cover multiple relevant facets, going beyond simple factual answers.
Plain English Explanation
RichRAG is a system that can provide detailed and comprehensive responses to complex queries by combining information retrieved from a knowledge base with natural language generation. Rather than just returning a simple factual answer, RichRAG aims to craft rich and multi-faceted responses that cover various relevant aspects of the query.
For example, if asked a question like "What is the history of the Eiffel Tower?", a traditional question-answering system might just provide a brief summary of when and why the Eiffel Tower was built. In contrast, RichRAG would try to give a more detailed response that covers the Tower's architectural design, its cultural significance, key events in its history, and other relevant information. The goal is to provide a richer and more informative answer that addresses the many facets of the original query.
The core innovation of RichRAG is its ability to first identify the different aspects of a query that need to be addressed, then retrieve relevant information about each of those aspects from a database, and finally synthesize all of that information into a coherent and natural-sounding response. This allows RichRAG to go beyond simple factual lookups and generate more comprehensive and engaging answers.
Technical Explanation
The RichRAG model consists of two main components: a retrieval module and a generation module. The retrieval module uses a neural network to select the most relevant information from a knowledge base to address the different aspects of the input query. The generation module then takes this retrieved information and uses language modeling to produce a fluent and coherent natural language response.
A key aspect of RichRAG is its ability to identify the multiple facets of a complex query and retrieve relevant information for each one. This is done through a multi-task training process where the retrieval module is trained to not just find the most relevant information overall, but to specifically target different aspects of the query. The generation module is then trained to assemble this diverse retrieved information into a well-structured and informative response.
Experiments show that RichRAG outperforms traditional RAG models on benchmark multi-faceted question answering tasks. It is able to provide richer and more comprehensive responses compared to simpler retrieval-based or generation-based approaches. The paper also discusses the model's robustness to different types of queries and its ability to handle queries that require reasoning beyond simple factual lookups.
Critical Analysis
One potential limitation of RichRAG is that it relies on having a high-quality and comprehensive knowledge base to draw information from. If the underlying database is incomplete or biased, the model's responses may also be limited or skewed. The paper acknowledges this and suggests that future work could explore techniques for dynamically expanding the knowledge base or incorporating information from multiple sources.
Additionally, while RichRAG demonstrates strong performance on benchmark question answering tasks, its real-world applicability may depend on how well it generalizes to open-ended user queries in practical settings. The paper does not extensively evaluate the model's performance on more diverse and unpredictable queries that might arise in real-world conversational scenarios.
Finally, the paper focuses primarily on the technical details of the RichRAG model and its quantitative evaluation. It would be valuable to also explore the qualitative aspects of the model's responses, such as their coherence, informativeness, and usefulness from an end-user perspective. This could help identify additional areas for improvement or refinement of the RichRAG approach.
Conclusion
The RichRAG model represents an important advancement in retrieval-augmented generation, demonstrating the potential to craft rich and multi-faceted responses that go beyond simplistic factual lookups. By combining targeted retrieval with natural language generation, RichRAG can provide more comprehensive and informative answers to complex queries.
While the model has some limitations, the core idea of leveraging diverse retrieved information to generate richer responses is a promising direction for improving the capabilities of question-answering and conversational AI systems. Further research and real-world deployment of models like RichRAG could lead to more engaging and useful interactions between humans and AI assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RichRAG: Crafting Rich Responses for Multi-faceted Queries in Retrieval-Augmented Generation
Shuting Wang, Xin Yu, Mang Wang, Weipeng Chen, Yutao Zhu, Zhicheng Dou
Retrieval-augmented generation (RAG) effectively addresses issues of static knowledge and hallucination in large language models. Existing studies mostly focus on question scenarios with clear user intents and concise answers. However, it is prevalent that users issue broad, open-ended queries with diverse sub-intents, for which they desire rich and long-form answers covering multiple relevant aspects. To tackle this important yet underexplored problem, we propose a novel RAG framework, namely RichRAG. It includes a sub-aspect explorer to identify potential sub-aspects of input questions, a multi-faceted retriever to build a candidate pool of diverse external documents related to these sub-aspects, and a generative list-wise ranker, which is a key module to provide the top-k most valuable documents for the final generator. These ranked documents sufficiently cover various query aspects and are aware of the generator's preferences, hence incentivizing it to produce rich and comprehensive responses for users. The training of our ranker involves a supervised fine-tuning stage to ensure the basic coverage of documents, and a reinforcement learning stage to align downstream LLM's preferences to the ranking of documents. Experimental results on two publicly available datasets prove that our framework effectively and efficiently provides comprehensive and satisfying responses to users.
Read more6/26/2024
0
Searching for Best Practices in Retrieval-Augmented Generation
Xiaohua Wang, Zhenghua Wang, Xuan Gao, Feiran Zhang, Yixin Wu, Zhibo Xu, Tianyuan Shi, Zhengyuan Wang, Shizheng Li, Qi Qian, Ruicheng Yin, Changze Lv, Xiaoqing Zheng, Xuanjing Huang
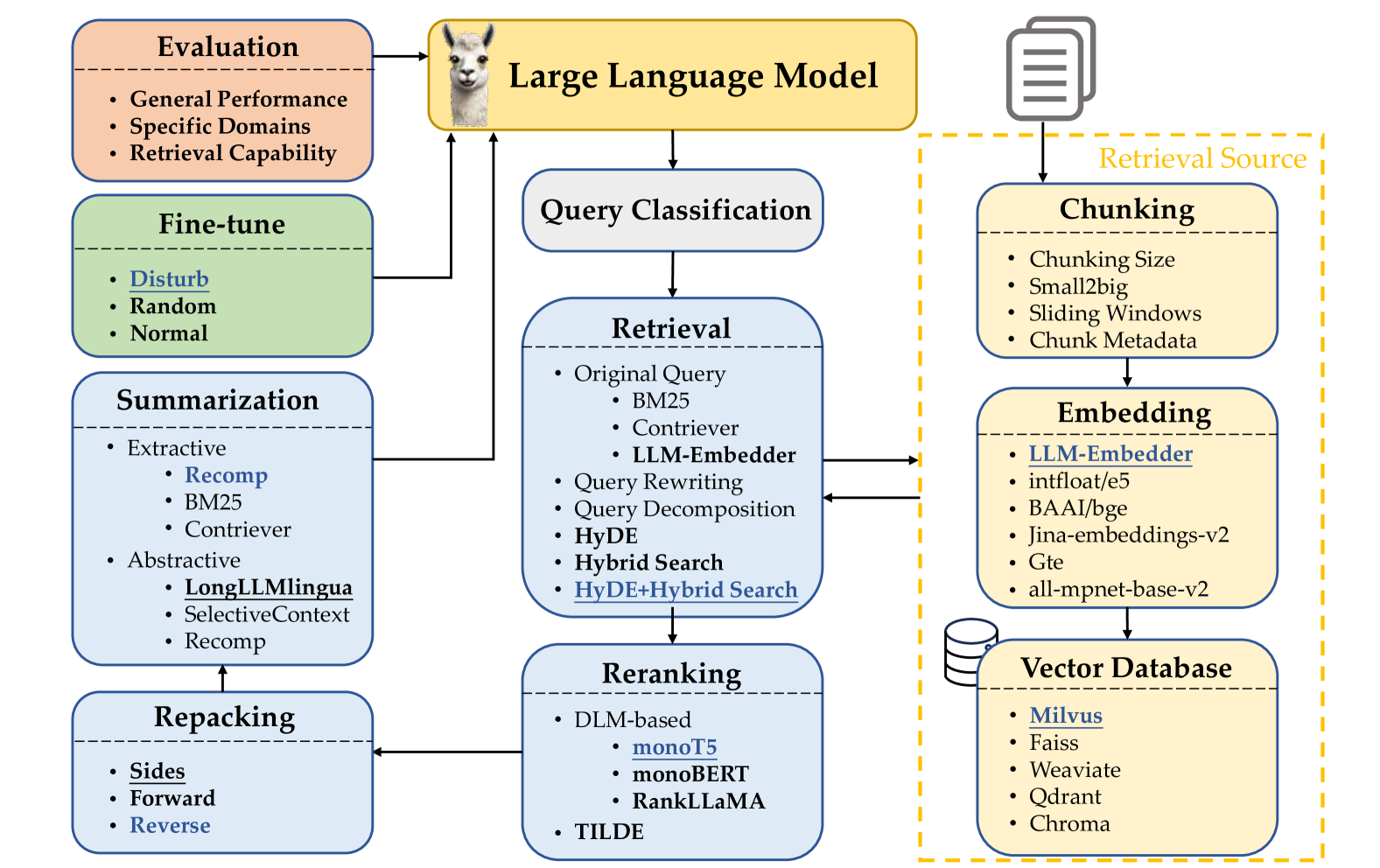
Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed to enhance large language models through query-dependent retrievals, these approaches still suffer from their complex implementation and prolonged response times. Typically, a RAG workflow involves multiple processing steps, each of which can be executed in various ways. Here, we investigate existing RAG approaches and their potential combinations to identify optimal RAG practices. Through extensive experiments, we suggest several strategies for deploying RAG that balance both performance and efficiency. Moreover, we demonstrate that multimodal retrieval techniques can significantly enhance question-answering capabilities about visual inputs and accelerate the generation of multimodal content using a retrieval as generation strategy.
Read more7/2/2024
🧪
0
A Multi-Source Retrieval Question Answering Framework Based on RAG
Ridong Wu, Shuhong Chen, Xiangbiao Su, Yuankai Zhu, Yifei Liao, Jianming Wu
With the rapid development of large-scale language models, Retrieval-Augmented Generation (RAG) has been widely adopted. However, existing RAG paradigms are inevitably influenced by erroneous retrieval information, thereby reducing the reliability and correctness of generated results. Therefore, to improve the relevance of retrieval information, this study proposes a method that replaces traditional retrievers with GPT-3.5, leveraging its vast corpus knowledge to generate retrieval information. We also propose a web retrieval based method to implement fine-grained knowledge retrieval, Utilizing the powerful reasoning capability of GPT-3.5 to realize semantic partitioning of problem.In order to mitigate the illusion of GPT retrieval and reduce noise in Web retrieval,we proposes a multi-source retrieval framework, named MSRAG, which combines GPT retrieval with web retrieval. Experiments on multiple knowledge-intensive QA datasets demonstrate that the proposed framework in this study performs better than existing RAG framework in enhancing the overall efficiency and accuracy of QA systems.
Read more5/30/2024
0
DR-RAG: Applying Dynamic Document Relevance to Retrieval-Augmented Generation for Question-Answering
Zijian Hei, Weiling Liu, Wenjie Ou, Juyi Qiao, Junming Jiao, Guowen Song, Ting Tian, Yi Lin
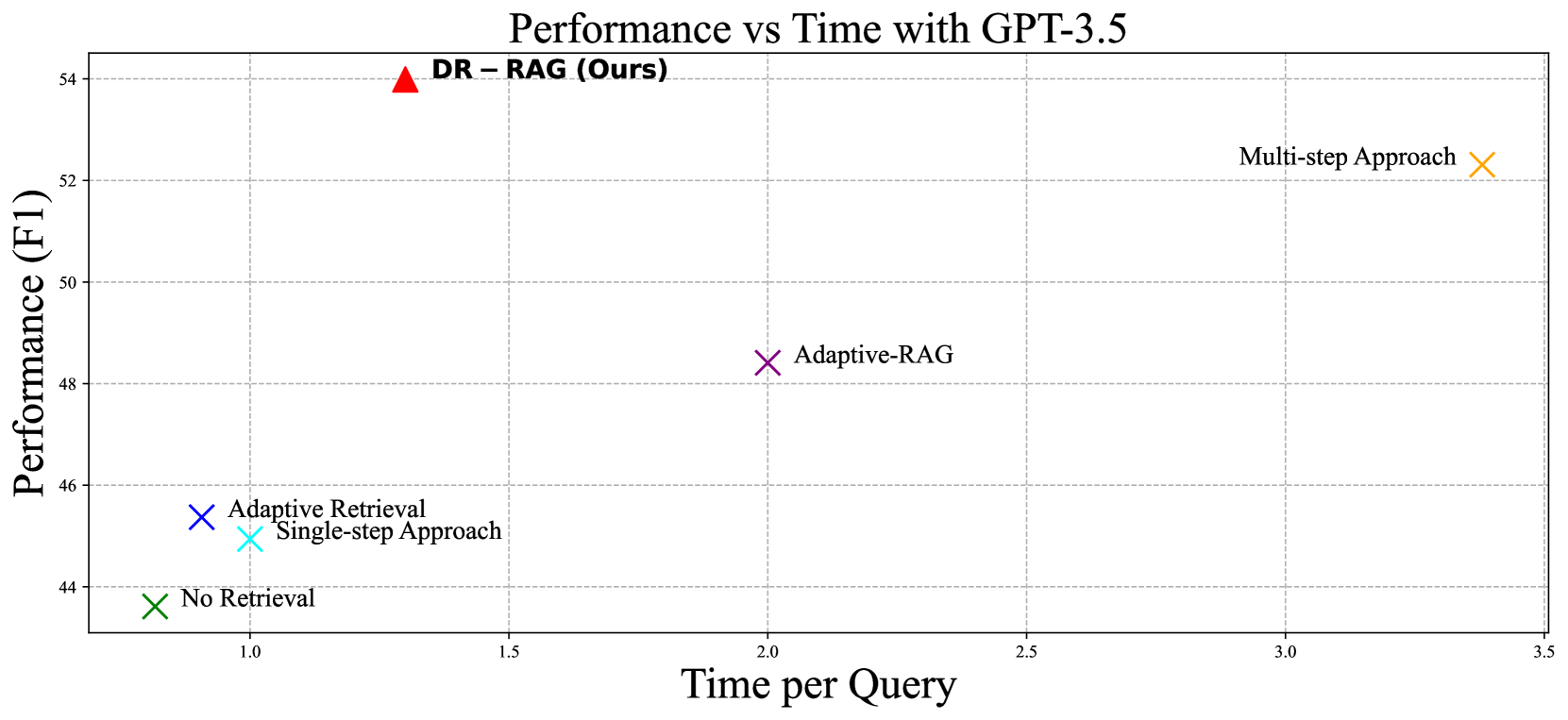
Retrieval-Augmented Generation (RAG) has recently demonstrated the performance of Large Language Models (LLMs) in the knowledge-intensive tasks such as Question-Answering (QA). RAG expands the query context by incorporating external knowledge bases to enhance the response accuracy. However, it would be inefficient to access LLMs multiple times for each query and unreliable to retrieve all the relevant documents by a single query. We have found that even though there is low relevance between some critical documents and query, it is possible to retrieve the remaining documents by combining parts of the documents with the query. To mine the relevance, a two-stage retrieval framework called Dynamic-Relevant Retrieval-Augmented Generation (DR-RAG) is proposed to improve document retrieval recall and the accuracy of answers while maintaining efficiency. Additionally, a compact classifier is applied to two different selection strategies to determine the contribution of the retrieved documents to answering the query and retrieve the relatively relevant documents. Meanwhile, DR-RAG call the LLMs only once, which significantly improves the efficiency of the experiment. The experimental results on multi-hop QA datasets show that DR-RAG can significantly improve the accuracy of the answers and achieve new progress in QA systems.
Read more6/18/2024