Self-Training for Sample-Efficient Active Learning for Text Classification with Pre-Trained Language Models
2406.09206
0
0

Abstract
Active learning is an iterative labeling process that is used to obtain a small labeled subset, despite the absence of labeled data, thereby enabling to train a model for supervised tasks such as text classification. While active learning has made considerable progress in recent years due to improvements provided by pre-trained language models, there is untapped potential in the often neglected unlabeled portion of the data, although it is available in considerably larger quantities than the usually small set of labeled data. Here we investigate how self-training, a semi-supervised approach where a model is used to obtain pseudo-labels from the unlabeled data, can be used to improve the efficiency of active learning for text classification. Starting with an extensive reproduction of four previous self-training approaches, some of which are evaluated for the first time in the context of active learning or natural language processing, we devise HAST, a new and effective self-training strategy, which is evaluated on four text classification benchmarks, on which it outperforms the reproduced self-training approaches and reaches classification results comparable to previous experiments for three out of four datasets, using only 25% of the data.
Create account to get full access
Overview
- The paper explores a self-training approach for active learning with pre-trained language models for text classification tasks.
- The method aims to improve sample efficiency by leveraging unlabeled data and pre-trained language model knowledge.
- The authors propose a self-training algorithm that iteratively adds high-confidence predictions to the training set, fine-tuning the model on the growing dataset.
Plain English Explanation
The paper presents a way to make text classification models more efficient by using a technique called "self-training." Text classification is the process of automatically categorizing text, like classifying emails as spam or not spam.
Typically, training these models requires a lot of labeled data, which can be expensive and time-consuming to collect. Active learning is a method that tries to reduce the amount of labeled data needed by focusing on the most informative samples.
The authors combine active learning with a self-training approach. Self-training means the model starts with a small amount of labeled data, makes predictions on unlabeled data, and then adds the most confident predictions back to the training set. By iterating this process, the model can learn from the unlabeled data and become more accurate over time, requiring fewer labeled samples.
The key insight is that pre-trained language models - models that have been trained on vast amounts of text data - can provide a strong starting point for this self-training approach. The authors show this technique can achieve good performance with much less labeled data than traditional methods.
Technical Explanation
The paper proposes a self-training algorithm for active learning with pre-trained language models. The core idea is to iteratively fine-tune the pre-trained model on a growing dataset, where the dataset is expanded by adding high-confidence predictions from the model on unlabeled samples.
Specifically, the method starts with a small labeled dataset and a pre-trained language model. In each iteration:
- The model is fine-tuned on the current labeled dataset.
- The fine-tuned model is used to make predictions on the unlabeled data.
- The most confident predictions are added to the training set, with their predicted labels.
- The model is fine-tuned again on the expanded training set.
This process continues until a desired performance level is reached or a budget of labeled samples is exhausted.
The authors experiment with different strategies for selecting which unlabeled samples to add to the training set, such as confidence thresholds and diversity-based sampling. They evaluate their approach on several text classification benchmarks and show it can achieve competitive performance with significantly fewer labeled samples compared to traditional active learning methods.
Critical Analysis
The paper presents a promising approach to improve sample efficiency for text classification tasks by leveraging pre-trained language models and self-training. However, there are a few potential limitations and areas for further research:
-
The self-training process relies on the model's ability to make accurate predictions on unlabeled data, which can be fragile and susceptible to confirmation bias. Careful selection of the unlabeled samples to add to the training set is crucial.
-
The performance of the self-training approach may depend on the quality and domain-relevance of the pre-trained language model. Applying the method to new domains or tasks could require fine-tuning or adapting the pre-trained model first.
-
The paper does not explore the potential for autonomous learning by the model, where the self-training process could continue without human supervision. Investigating this direction could lead to more incremental self-training approaches.
Overall, the proposed self-training method is a valuable contribution to the field of active learning and text classification, offering a sample-efficient way to leverage pre-trained language models. Further research on the robustness and adaptability of the approach could help expand its applicability and impact.
Conclusion
The paper presents a self-training algorithm for active learning with pre-trained language models, which aims to improve sample efficiency for text classification tasks. By iteratively fine-tuning the model on a growing dataset that includes high-confidence predictions on unlabeled samples, the approach can achieve competitive performance with significantly fewer labeled examples compared to traditional active learning methods.
While the self-training process has some potential limitations, the paper demonstrates the promising benefits of combining active learning, self-training, and pre-trained language models. Continued research in this direction could lead to more autonomous and incremental learning approaches, further reducing the need for extensive labeled data and manual supervision in text classification applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
Self-Training: A Survey
Massih-Reza Amini, Vasilii Feofanov, Loic Pauletto, Lies Hadjadj, Emilie Devijver, Yury Maximov
0
0
Semi-supervised algorithms aim to learn prediction functions from a small set of labeled observations and a large set of unlabeled observations. Because this framework is relevant in many applications, they have received a lot of interest in both academia and industry. Among the existing techniques, self-training methods have undoubtedly attracted greater attention in recent years. These models are designed to find the decision boundary on low density regions without making additional assumptions about the data distribution, and use the unsigned output score of a learned classifier, or its margin, as an indicator of confidence. The working principle of self-training algorithms is to learn a classifier iteratively by assigning pseudo-labels to the set of unlabeled training samples with a margin greater than a certain threshold. The pseudo-labeled examples are then used to enrich the labeled training data and to train a new classifier in conjunction with the labeled training set. In this paper, we present self-training methods for binary and multi-class classification; as well as their variants and two related approaches, namely consistency-based approaches and transductive learning. We examine the impact of significant self-training features on various methods, using different general and image classification benchmarks, and we discuss our ideas for future research in self-training. To the best of our knowledge, this is the first thorough and complete survey on this subject.
5/28/2024
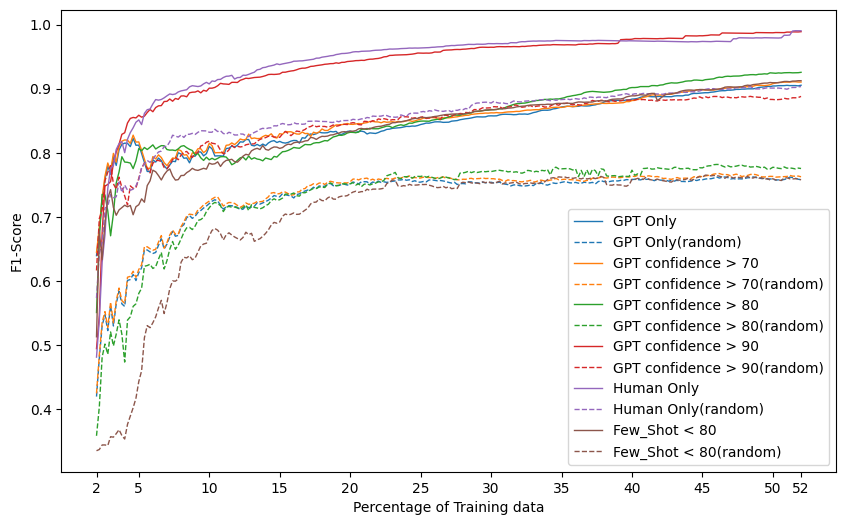
Enhancing Text Classification through LLM-Driven Active Learning and Human Annotation
Hamidreza Rouzegar, Masoud Makrehchi
0
0
In the context of text classification, the financial burden of annotation exercises for creating training data is a critical issue. Active learning techniques, particularly those rooted in uncertainty sampling, offer a cost-effective solution by pinpointing the most instructive samples for manual annotation. Similarly, Large Language Models (LLMs) such as GPT-3.5 provide an alternative for automated annotation but come with concerns regarding their reliability. This study introduces a novel methodology that integrates human annotators and LLMs within an Active Learning framework. We conducted evaluations on three public datasets. IMDB for sentiment analysis, a Fake News dataset for authenticity discernment, and a Movie Genres dataset for multi-label classification.The proposed framework integrates human annotation with the output of LLMs, depending on the model uncertainty levels. This strategy achieves an optimal balance between cost efficiency and classification performance. The empirical results show a substantial decrease in the costs associated with data annotation while either maintaining or improving model accuracy.
6/19/2024
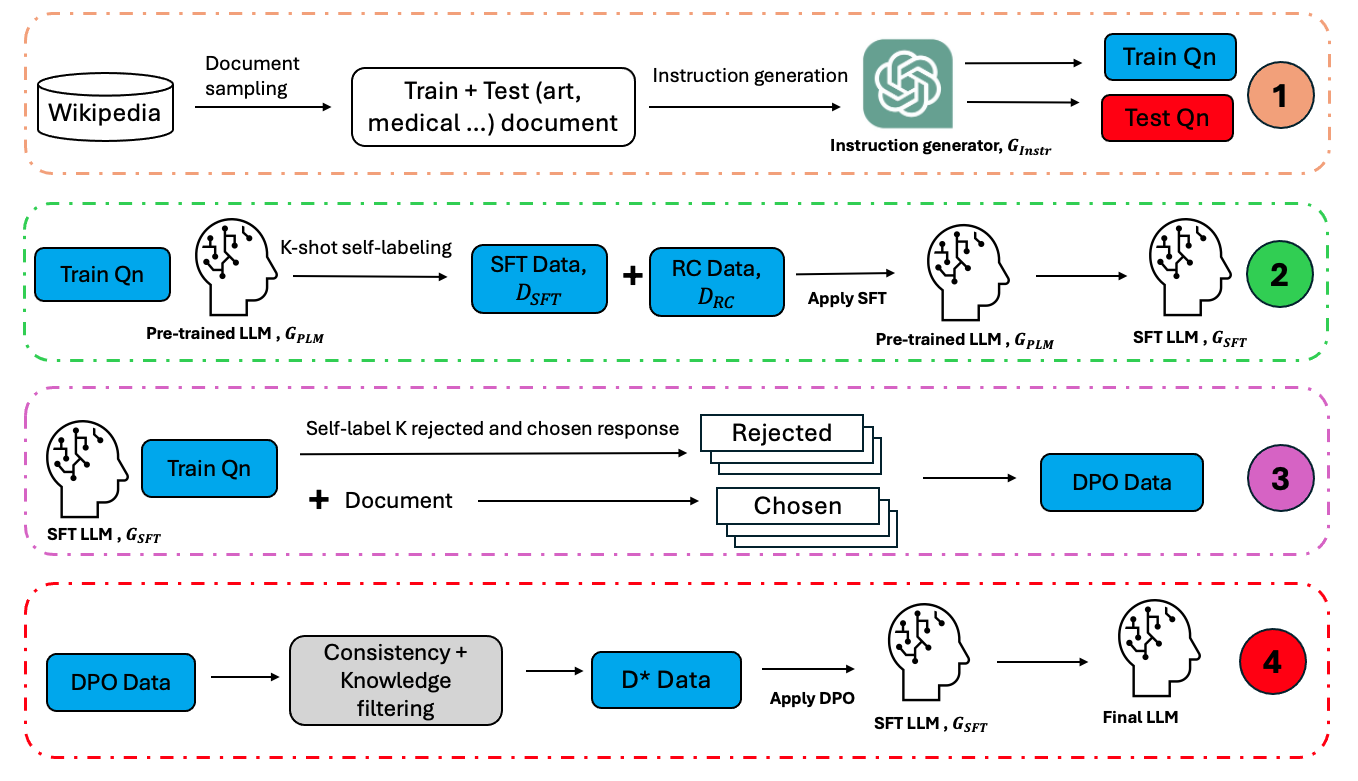
Self-training Large Language Models through Knowledge Detection
Wei Jie Yeo, Teddy Ferdinan, Przemyslaw Kazienko, Ranjan Satapathy, Erik Cambria
0
0
Large language models (LLMs) often necessitate extensive labeled datasets and training compute to achieve impressive performance across downstream tasks. This paper explores a self-training paradigm, where the LLM autonomously curates its own labels and selectively trains on unknown data samples identified through a reference-free consistency method. Empirical evaluations demonstrate significant improvements in reducing hallucination in generation across multiple subjects. Furthermore, the selective training framework mitigates catastrophic forgetting in out-of-distribution benchmarks, addressing a critical limitation in training LLMs. Our findings suggest that such an approach can substantially reduce the dependency on large labeled datasets, paving the way for more scalable and cost-effective language model training.
6/18/2024

Classification Tree-based Active Learning: A Wrapper Approach
Ashna Jose, Emilie Devijver, Massih-Reza Amini, Noel Jakse, Roberta Poloni
0
0
Supervised machine learning often requires large training sets to train accurate models, yet obtaining large amounts of labeled data is not always feasible. Hence, it becomes crucial to explore active learning methods for reducing the size of training sets while maintaining high accuracy. The aim is to select the optimal subset of data for labeling from an initial unlabeled set, ensuring precise prediction of outcomes. However, conventional active learning approaches are comparable to classical random sampling. This paper proposes a wrapper active learning method for classification, organizing the sampling process into a tree structure, that improves state-of-the-art algorithms. A classification tree constructed on an initial set of labeled samples is considered to decompose the space into low-entropy regions. Input-space based criteria are used thereafter to sub-sample from these regions, the total number of points to be labeled being decomposed into each region. This adaptation proves to be a significant enhancement over existing active learning methods. Through experiments conducted on various benchmark data sets, the paper demonstrates the efficacy of the proposed framework by being effective in constructing accurate classification models, even when provided with a severely restricted labeled data set.
4/16/2024