Frugal Algorithm Selection
2405.11059
0
0
Abstract
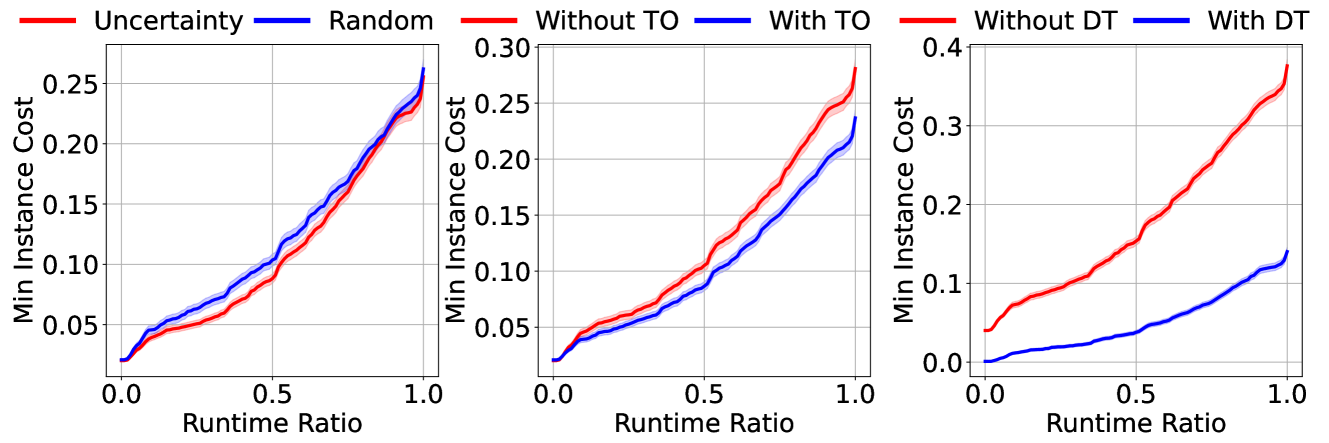
When solving decision and optimisation problems, many competing algorithms (model and solver choices) have complementary strengths. Typically, there is no single algorithm that works well for all instances of a problem. Automated algorithm selection has been shown to work very well for choosing a suitable algorithm for a given instance. However, the cost of training can be prohibitively large due to running candidate algorithms on a representative set of training instances. In this work, we explore reducing this cost by choosing a subset of the training instances on which to train. We approach this problem in three ways: using active learning to decide based on prediction uncertainty, augmenting the algorithm predictors with a timeout predictor, and collecting training data using a progressively increasing timeout. We evaluate combinations of these approaches on six datasets from ASLib and present the reduction in labelling cost achieved by each option.
Create account to get full access
Overview
- Proposes a "frugal" algorithm selection approach that aims to find high-performing algorithms using fewer computational resources
- Introduces an algorithm selection framework that leverages meta-features and performance prediction models to quickly identify promising algorithms
- Demonstrates the framework's effectiveness on a variety of benchmark optimization problems
Plain English Explanation
The paper explores a new way to choose the best algorithm for solving a given optimization problem. Often, finding the right algorithm can be a time-consuming process, as it may require testing many different options to see which one performs the best.
The researchers propose a "frugal" approach that aims to identify high-performing algorithms using fewer computational resources. Their framework relies on two key components: meta-features and performance prediction models. Meta-features are characteristics of the optimization problem that can provide insights into which algorithms might work well. The performance prediction models then use these meta-features to quickly estimate how well different algorithms are likely to perform, without having to run them all.
By leveraging this meta-information, the framework is able to efficiently explore the space of potential algorithms and identify the most promising ones. The researchers demonstrate the effectiveness of their approach on a variety of benchmark optimization problems, showing that it can find high-performing algorithms using significantly fewer computational resources compared to traditional methods.
This work builds on previous research that has explored ways to enhance algorithm selection performance and better understand the factors that influence algorithm generalization. The proposed "frugal" approach represents a promising step forward in the quest to unlock the power of algorithm features for generalization and enhance large language model-based algorithm selection.
Technical Explanation
The paper introduces a novel framework for automated algorithm selection, which aims to identify high-performing algorithms for a given optimization problem using fewer computational resources. The key elements of the framework are:
-
Meta-features: Characteristics of the optimization problem that can provide insights into which algorithms might work well. These include problem size, sparsity, multimodality, and other structural properties.
-
Performance prediction models: Machine learning models that use the meta-features to quickly estimate the performance of different algorithms, without having to run them all.
The researchers demonstrate the effectiveness of their framework on a variety of benchmark optimization problems, including continuous and combinatorial optimization tasks. They show that their "frugal" approach can identify high-performing algorithms using significantly fewer function evaluations compared to traditional algorithm selection methods.
The paper also provides a detailed analysis of the factors that influence algorithm performance and generalization, building on previous research in this area. This includes an examination of how problem meta-features impact algorithm selection and performance.
Critical Analysis
The paper presents a compelling approach to automated algorithm selection, with several strengths:
- The use of meta-features and performance prediction models to efficiently explore the space of potential algorithms is a promising idea that could have significant practical impact.
- The empirical results on benchmark problems demonstrate the effectiveness of the proposed framework, particularly in terms of reducing computational resources required.
- The analysis of algorithm performance and generalization factors provides valuable insights that could inform future research in this area.
However, the paper also has some limitations:
- The framework has only been evaluated on a relatively narrow set of benchmark problems, and its performance on real-world, large-scale optimization tasks remains to be seen.
- The paper does not provide much detail on the specific machine learning models and algorithms used for performance prediction, which makes it difficult to assess their transferability to other domains.
- While the "frugal" aspect of the approach is an important contribution, the paper does not quantify the exact computational savings compared to traditional methods in a systematic way.
Future research could address these limitations by expanding the evaluation to more diverse optimization problems, providing more technical details on the performance prediction models, and conducting a more rigorous comparative analysis of computational costs.
Conclusion
The paper presents a novel framework for automated algorithm selection that aims to identify high-performing algorithms using fewer computational resources. By leveraging meta-features and performance prediction models, the proposed approach can efficiently explore the space of potential algorithms and identify promising candidates without having to run them all.
The empirical results demonstrate the effectiveness of this "frugal" approach on a variety of benchmark optimization problems, and the analysis of algorithm performance and generalization factors provides valuable insights for the field. While the paper has some limitations, the overall contribution represents an important step forward in the quest to unlock the power of algorithm features for generalization and enhance large language model-based algorithm selection.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

On the Fragility of Active Learners
Abhishek Ghose, Emma Thuong Nguyen
0
0
Active learning (AL) techniques aim to maximally utilize a labeling budget by iteratively selecting instances that are most likely to improve prediction accuracy. However, their benefit compared to random sampling has not been consistent across various setups, e.g., different datasets, classifiers. In this empirical study, we examine how a combination of different factors might obscure any gains from an AL technique. Focusing on text classification, we rigorously evaluate AL techniques over around 1000 experiments that vary wrt the dataset, batch size, text representation and the classifier. We show that AL is only effective in a narrow set of circumstances. We also address the problem of using metrics that are better aligned with real world expectations. The impact of this study is in its insights for a practitioner: (a) the choice of text representation and classifier is as important as that of an AL technique, (b) choice of the right metric is critical in assessment of the latter, and, finally, (c) reported AL results must be holistically interpreted, accounting for variables other than just the query strategy.
4/16/2024

Improving Algorithm-Selection and Performance-Prediction via Learning Discriminating Training Samples
Quentin Renau, Emma Hart
0
0
The choice of input-data used to train algorithm-selection models is recognised as being a critical part of the model success. Recently, feature-free methods for algorithm-selection that use short trajectories obtained from running a solver as input have shown promise. However, it is unclear to what extent these trajectories reliably discriminate between solvers. We propose a meta approach to generating discriminatory trajectories with respect to a portfolio of solvers. The algorithm-configuration tool irace is used to tune the parameters of a simple Simulated Annealing algorithm (SA) to produce trajectories that maximise the performance metrics of ML models trained on this data. We show that when the trajectories obtained from the tuned SA algorithm are used in ML models for algorithm-selection and performance prediction, we obtain significantly improved performance metrics compared to models trained both on raw trajectory data and on exploratory landscape features.
4/9/2024
📊
Bayesian Data Selection
Julian Rodemann
0
0
A wide range of machine learning algorithms iteratively add data to the training sample. Examples include semi-supervised learning, active learning, multi-armed bandits, and Bayesian optimization. We embed this kind of data addition into decision theory by framing data selection as a decision problem. This paves the way for finding Bayes-optimal selections of data. For the illustrative case of self-training in semi-supervised learning, we derive the respective Bayes criterion. We further show that deploying this criterion mitigates the issue of confirmation bias by empirically assessing our method for generalized linear models, semi-parametric generalized additive models, and Bayesian neural networks on simulated and real-world data.
6/26/2024

An Active Learning Framework with a Class Balancing Strategy for Time Series Classification
Shemonto Das
0
0
Training machine learning models for classification tasks often requires labeling numerous samples, which is costly and time-consuming, especially in time series analysis. This research investigates Active Learning (AL) strategies to reduce the amount of labeled data needed for effective time series classification. Traditional AL techniques cannot control the selection of instances per class for labeling, leading to potential bias in classification performance and instance selection, particularly in imbalanced time series datasets. To address this, we propose a novel class-balancing instance selection algorithm integrated with standard AL strategies. Our approach aims to select more instances from classes with fewer labeled examples, thereby addressing imbalance in time series datasets. We demonstrate the effectiveness of our AL framework in selecting informative data samples for two distinct domains of tactile texture recognition and industrial fault detection. In robotics, our method achieves high-performance texture categorization while significantly reducing labeled training data requirements to 70%. We also evaluate the impact of different sliding window time intervals on robotic texture classification using AL strategies. In synthetic fiber manufacturing, we adapt AL techniques to address the challenge of fault classification, aiming to minimize data annotation cost and time for industries. We also address real-life class imbalances in the multiclass industrial anomalous dataset using our class-balancing instance algorithm integrated with AL strategies. Overall, this thesis highlights the potential of our AL framework across these two distinct domains.
5/21/2024